






一、用户交互
input 接收用户键盘的输入,为字符串格式(即使输入为数字,也转化为字符串格式)
1 name = input("input your name:") 2 num = int(input("input your number:")) 3 print(name) 4 print(num)

查看某一功能(例如,字符串、列表、字典、元组等)的功能,利用 dir()方法
1 list_test = list(["zhu","shan","wei","zhu"]) 2 print(dir(list_test))
['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
查看变量的类型,利用type()方法
1 test_list = [] 2 print(type(test_list))
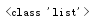
二、字符串连接和格式化
利用加号可以把几个字符串连为一个,利用 %(变量) 的形式可以格式化字符串
1 name = input("input your name:") 2 age = int(input("input your number:")) 3 job = input("input your job:") 4 print("my name is " + name + "\n" "my age is " + str(age) + "\n" "my job is " + job) 5 print(''' 6 my name is %s; 7 my age is %s; 8 my job is %s 9 '''%(name,age,job))

三、字符串常用功能
创建一个字符串
1 test_str = ' ' 2 #或 3 test_str = str(' ')
利用字符串的 strip() 功能移除字符串两边的字符,不能去除中间的字符,默认为空白字符,可以在括号内写入其它字符,删除左侧字符lstrip(),删除右侧字符rstrip()
1 str_test1 = input("input your string:").strip() 2 str_test2 = input("input your string:") 3 str2 = str_test2.strip('z') 4 print(str_test1) 5 print(str2)

把字符串的第一个字母变为大写,只改变第一个字母,利用capitalize()方法
1 name = str('zhu shan wei') 2 name1 = name.capitalize() 3 print(name1)
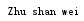
把字符串的所有字母都变为小写,利用casefold()方法
1 name = str('Zhu Shan Wei') 2 name1 = name.casefold() 3 print(name1)
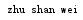
填充字符串,第一个参数为填充后字符串宽度,第二个参数为填充的内容,默认为空格,利用center()、ljust()、rjust()方法,原字符串分别为居中、居左、居右,剩余填充;zfill()方法,参数为字符串的宽度,原字符串小于参数设定,则在左边补0
1 name = str('Zhu Shan Wei') 2 name1 = name.center(50,"*") 3 name2 = name.rjust(50) 4 name3 = name.ljust(50,"$") 5 print(name1) 6 print(name2) 7 print(name3)

统计字符串中某一元素的个数,利用count()方法,第一参数为元素,第二和第三位开始和结束索引位置,默认为全部
1 name = str('Zhu Shan Wei IS a handsome') 2 num1 = name.count("S",3,20) 3 print(num1)
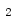
字符串变为其他编码的格式,利用encode()方法,参数为要改变的编码格式
1 name = str('Zhu Shan Wei IS a handsome') 2 name1 = name.encode("utf-8") 3 print(name1)
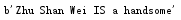
判断字符串是否以某一元素开始或结尾,利用startwith()、endwith()方法,返回布尔值,第一个参数为元素,第二和第三参数为开始和结束索引位置,默认为开头或结尾
1 name = str('Zhu Shan Wei IS a handsome') 2 result1 = name.startswith("Z") 3 result2 = name.endswith("E") 4 print(result1) 5 print(result2)
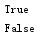
将字符串中的 \t 转换为空格,利用expendtabs(),参数为空格个数,默认为8
1 name = str('hand\tsome') 2 result1 = name.expandtabs(20) 3 print(result1)

在字符串中从左边开始,找到某一元素的索引位置,利用find()、index()方法,第一参数为元素,第二和第三参数为开始和结束索引位置,默认为全部,返回索引位置,从右边开始查rindex()
1 name = str('handsome') 2 result1 = name.index("d") 3 result2 = name.find("e",5,20) 4 print(result1) 5 print(result2)
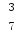
字符串格式化,按对应的位置格式或内容,利用format()方法,起始从0开始
1 name = str('{0} {1} handsome') 2 result1 = name.format("zhu shan wei","is") 3 print(result1)
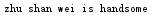
判断字符串是否符合,是否全部由数字或字母组成isalnum(),是否全部由字母组成isalpha(),是否全部由十进制数组成isdecimal(),是否全部由整数组成isdigit(),是否为有效字符isidentifier(),是否都是小写islower(),是否都是大写isupper(),是否全部为数字isnumeric(),是否全部为空格isspace(),每个单词的首字母是否为大写istitle()
1 str1 = str("zhu shan wei") #有空格存在,不全部为字母 2 result1 = str1.isalpha() 3 print(result1)
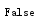
分割字符串,split()方法,参数为元素,把分割的字符串生成一个列表,参数元素不在列表中,splitlines()方法,把字符串按行分割,每一行为一个字符串生成一个列表,功能相当于split('\n'),partition()方法,参数为元素,从左查起,将第一个参数的左右分为连个字符串,包括参数元素在内,分为三个部分,生成一个列表
1 str1 = str("zhushanw eiisahandsome") 2 result1 = str1.rsplit("a") 3 print(result1)
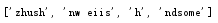
字符串替换,利用replace()功能,第一参数为原元素,第二个参数为新元素,第三个参数为替换个数,从左到右替换,默认为全部
str1 = str('ABCdlnDCDDDCCCCCg') str2 = str1.replace('C','F',5) print(str2)
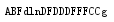
字符串映射,把原字符串按设定好的对应关系一一替换,利用maketrans()和translate()的方法
1 intab = "abcd" 2 outtab = "1234" 3 str_trantab = str.maketrans(intab, outtab) 4 test_str = "csdn blog: http://blog.youkuaiyun.com/wirelessqa" 5 print(test_str.translate(str_trantab))
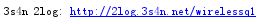
将字符串的大写变小写,小写变大写,利用swapcase()方法,将字符串的每个单词的首字母变大写,利用title()方法
1 str1 = '''abcllkng 2 slALNGlla 3 skjlajg 4 ''' 5 str2 = str1.swapcase() 6 str3 = str1.title() 7 print(str2) 8 print(str3)
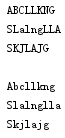
把字符串的每个字符用其他字符元素连接起来,利用join()方法,线设定好连接的字符元素
1 str1 = ''' 2 abcllkngs 3 lALNGll 4 askjlajg 5 ''' 6 str2 = str('-') 7 str3 = str2.join(str1) 8 print(str1) 9 print(str3)

四、列表和元组常用功能
创建一个列表
1 test_list = [] 2 #或 3 test_list = list([])
取出列表中的某一元素,元素可以是字符、字符串、数字等,利用索引的方式,索引值从0开始
1 list_test = ["zhu","shan","wei"] 2 string_list = list_test[1] 3 print(string_list)
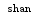
向列表中添加元素,利用 append() 方法,可以在列表的末尾添加元素,元素可以和列表中原来的元素重复
1 list_test = ["zhu","shan","wei"] 2 list_test.append("is") 3 print(list_test)
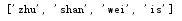
寻找列表中元素的索引,利用 index() 方法,从左到右找到第一个符合的元素,返回索引值结束
1 list_test = ["zhu","shan","wei"] 2 list_index = list_test.index("zhu") 3 print(list_index)
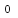
统计列表中某一个元素的个数,利用 count()方法
1 list_test = ["zhu","shan","wei","zhu"] 2 list_num = list_test.count("zhu") 3 print(list_num)
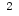
想列表中想要的索引位置插入一个元素,利用 insert() 方法,第一个参数为要插入元素的索引位置,第二个参数为元素
1 list_test = ["zhu","shan","wei"] 2 list_test.insert(3,"is") 3 print(list_test)
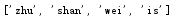
从列表的末尾处弹出一个元素,利用 pop() 方法,弹出的元素可以被接收
1 list_test = ["zhu","shan","wei"] 2 list_element = list_test.pop() 3 print(list_test) 4 print(list_element)
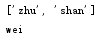
从列表中删除一个指定的元素,利用 remove() 方法,从左到右查找,只能删除一个,删除的元素不嫩被接收
1 list_test = ["zhu","shan","wei"] 2 list_element = list_test.remove("zhu") 3 print(list_test) 4 print(list_element)
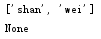
将列表中的元素进行反向排列,利用 reverse() 方法
1 list_test = ["zhu","shan","wei"] 2 list_test.reverse() 3 print(list_test)
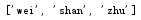
将列表中的元素按照ASCII码的顺序从小到大排列,利用 sort() 方法
1 list_test = ["zhu","shan","wei"] 2 list_test.sort() 3 print(list_test)
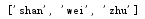
列表切片,即把一部分元素从列表中分离出来,利用 list[index : index:num] 方法,最后一个index不计算在内,index可以省略不写,第一个不写表示从头开始,最后一个不写表示到末尾结束,都不写表示切片后的列表与原列表相同,-1表示倒数第一个,-2表示倒数第二个,num表示间隔可以不写
1 list_test = list(["zhu","shan","wei","zhu"]) 2 list_split = list_test[0:-1] 3 print(list_test[0:-1]) 4 print(list_split)
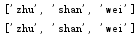
将两个列表中的元素合并到一起,利用 list1 + list2 的方法,或者利用 list1.extend(list2) 的方法,若扩展的是一个字符串,则会将字符串分为一个个的元素添加到原来的列表中
1 list_test = ["zhu","shan","wei"] 2 list_test1 = ["is","a","handsome","man"] 3 list_test2 = list_test + list_test1 4 list_test.extend(list_test1) 5 print(list_test) 6 print(list_test2)

清空列表中的元素,利用clear()方法
1 list1 = list(['anbg','lelng',5,'skg']) 2 list1.clear() 3 print(list1)
元组中的整个的元素不能被更改,但元素中的元素可以被更改,例如元组中有一个元素为字典,可以更改字典中的值,有count()和index()功能,用法同列表
1 tuple1 = (1,2,'zhu',9) 2 tuple2 = tuple((1,2,'zhu',9,{'k1':2,'k2':3})) 3 result1 = tuple2.count(2) 4 result12 = tuple2.index('zhu') 5 print(result1) 6 print(result12) 7 print(tuple2) 8 tuple2[4]['k1'] = 5 9 print(tuple1) 10 print(tuple2)

五、运算符、循环嵌套、主文件判断
基本的运算符 + - * /,取模返回余数%,幂运算**,整除返回商//,等于==,不等于!=,与and,或or,非not,判断x在y序列中in,判断x不在y序列中not in,判断x是y is,判断x不是y is not,continue结束本层循环的本次循环,继续本层循环的下一次循环,break结束本层循环,若本层外面还有循环层,则会继续外层的循环,外层循环不能被结束
1 def a(): 2 pass 3 def b(): 4 pass 5 6 if __name__ == "__main__" : 7 a()
以上代码是主文件判断,若是单独执行这个文件则执行 if __name__ == "__main__" : 下面的代码,若是这个文件被其他文件调用,则不会执行 if __name__ == "__main__" : 下面的代码,只能调用上面的函数
六、文件操作
文件操作模式分为:r只读模式,文件不存在会出错;w写入模式,文件不存在则会生成一个新的文件,文件已经存在则会覆盖原文件;a追加模式,文件不存在则生成新的文件,文件已经存在则在原文件内容的结尾处继续写入;w+读写模式,可以对文件进行读和写的操作,若文件不存在新建一个文件,若文件已经存在则会覆盖原文件。
打开文件操作,利用obj = open("文件路径","模式")方法;读取文件内容,obj.read()一次性将文件中的内容全部读取到内存中;obj.readlines()一次性将文件中的内容读到内存,并且按行分割为一个个字符串,形成一个列表;obj.readline()运行一次读取一行,再次运行读取下一行;for line in obj循环读取,每次只读取一行;向文件中写入内容,obj.write("内容"),多次写入是末尾没后换行符\n则会接着上一次的末尾写入;关闭文件,obj.close()方法
1 file_obj = open("123.txt","w+") 2 file_obj.write("this is first line") 3 file_obj.write("this is second line\n") 4 file_obj.write("this is third line\n") 5 file_obj.close()
123.txt中的内容为:
this is first linethis is second line
this is third line
1 file_obj = open("123.txt","r") 2 f1 = file_obj.read() 3 print(f1) 4 file_obj.close()
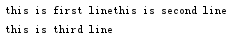
1 file_obj = open("123.txt","r") 2 f1 = file_obj.readline() 3 f2 = file_obj.readline() 4 print(f1) 5 print(f2) 6 file_obj.close()

1 file_obj = open("123.txt","r") 2 f1 = file_obj.readlines() 3 print(f1) 4 file_obj.close()
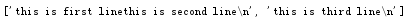
1 file_obj = open("123.txt","r") 2 for line in file_obj: 3 print(line) 4 file_obj.close()

1 f = open('456.txt','w',encoding='utf-8') # 以写的方式打开文件,没有则创建文件,每个汉字算一个字符,最后编码格式可以不加 2 f.write('古剑奇谭OL') # 写入文件 3 f.close() # 关闭保存文件 4 5 f = open('456.txt','a+',encoding='utf-8') # 以读的方式打开文件,不能写,,最后编码格式可以不加 6 file1 = f.read(4) # 读文件内容,可指定字符个数,默认为全读 7 print(file1) 8 print(f.tell()) # tell()查看当前指针位置,每个汉字为三个字节 9 f.seek(3) # seek()指定当前指针位置,参数为字节数 10 file2 = f.read(4) # 从指定位置开始读取 11 print(file2) 12 f.truncate() # 保留内存中当前指针位置之后的内容,前边的删除掉,不修改原文件 13 file3 = f.read() 14 print(file3) 15 f.close()
14
剑奇谭O
L
七、字典常用功能
创建一个字典dict()方法,复制一个字典copy()方法,清空一个字典clear()方法,字典是没有序列的
1 dict1 = {'k1':2,'k2':3} 2 dict2 = dict({'k1':2,'k2':3}) 3 dict3 = dict2.copy() 4 print(dict1) 5 print(dict2) 6 print(dict3) 7 dict3.clear() 8 print(dict3)

可以以某一序列(列表、元组)中的元素作为键创建一个字典,利用方法dict.fromkeys(),第一个参数为序列,第二个参数为键的值(默认为none);得到某一键对应的值,利用dict.get()方法,参数为键,返回键对应的值,若字典中没有该键则返回none;得到字典的键和键对应的值,利用dict.items()方法,每一对形成一个元组作为一个元素,形成一个列表;得到字典的键,利用dict.keys()方法,以列表的形式返回;弹出字典末尾的一对键和键对应的值,利用dict.popitem()方法,以元组的形成给出,字典为空则报错误KeyError;弹出字典对应键的值,利用dict.pop()方法,参数为键;查找字典中是否存在某一个键,利用dict.setdefault()方法,第一个参数为要查找的键,第二个参数为给键对应赋给的值(不写默认为none),若该键存在则返回原字典中键所对应的值,若该键不存在字典中则添加该键,并把第二参数的值作为改建对应的值;把字典A中的元素添加到字典B中,利用B.update(A)方法,参数为字典或者字典变量
1 seq = ['apple', 'pen', 'pineapple'] 2 dict1 = dict.fromkeys(seq,10) 3 print(dict1) 4 print('\n') 5 6 items_list = dict1.items() 7 print(items_list) 8 for key,value in items_list: 9 print(key,value) 10 print('\n') 11 12 keys_list = dict1.keys() 13 print(keys_list) 14 for key in dict1.keys(): 15 print(key) 16 print('\n') 17 18 item_tuple = dict1.popitem() 19 print(item_tuple) 20 for item_key in item_tuple: 21 print(item_key) 22 print(dict1) 23 print('\n') 24 25 item_value = dict1.pop('apple') 26 print(item_value) 27 print(dict1) 28 print('\n') 29 30 dict_value = dict1.setdefault('pen',20) 31 print(dict_value) 32 dict_value1 = dict1.setdefault('pear',20) 33 print(dict_value1) 34 print(dict1) 35 print('\n') 36 37 dict2 = dict({'banana':30, 'orange':40}) 38 dict1.update(dict2) 39 print(dict1)
{'apple': 10, 'pen': 10, 'pineapple': 10}
dict_items([('apple', 10), ('pen', 10), ('pineapple', 10)])
apple 10
pen 10
pineapple 10
dict_keys(['apple', 'pen', 'pineapple'])
apple
pen
pineapple
('pineapple', 10)
pineapple
10
{'apple': 10, 'pen': 10}
10
{'pen': 10}
10
20
{'pen': 10, 'pear': 20}
{'pen': 10, 'pear': 20, 'banana': 30, 'orange': 40}
八、集合的常用功能
集合是一些无序列的,不重复元素的组合,创建一个集合用set()方法,参数为一个元组或者列表(内容有重复的元素,集合会自动去掉重复元素,只保留一个);向集合中添加元素用set.add()方法,参数为要添加的元素;比较集合A和集合B中元素,把A集合中二者不同的元素作为一个新的集合,利用A.difference(B)方法,参数为集合变量或者列表;移除A集合中与B集合相同的元素,利用A.diffrence_update(B)方法,参数为集合变量或者列表;比较集合A和集合B中元素,把集合A中二者相同的元素作为一个新的集合,利用A.intersection(B)方法,参数为集合变量或者列表;保留A集合中与B集合相同的元素,利用A.intersection_update(B)方法,参数为集合变量或者列表;移除集合中的元素,利用set.discard()方法,参数为要移除的元素,若集合中有该元素则被移除;判断集合A与集合B有没有交集,利用A.isdisjoint(B)方法,参数为集合变量或者列表,有交集返回false,没有交集返回true;判断A集合是否为B集合的子集,利用A.issubset()方法,是返回true,不是返回false;判断A集合是否为B集合的父集,利用A.issuperset()方法,是返回true,不是返回false;对集合A和集合B做差集,去除两个集合中相同的元素,把两个集合只能怪不同的元素生成一个新的集,利用A.symmertric_difference(B)方法,参数为集合变量或者列表;把集合B与集合A不同的元素添加到集合A中,利用A.symmertric_difference_update(B)方法,参数为集合变量或者列表;合并集合A和集合B,形成一个新的集合,利用A.union(B)方法,参数为集合变量或者列表;向集合A中添加一个序列,利用A.update()方法,参数为列表、集合、元组或者他们的变量;随机弹出一个元素,利用set.pop()方法,弹出的元素可接收;移除集合中指定的元素,利用remove()方法,参数为要移除的元素,移除的元素不能被接收;清空集合利用set.clear()方法
1 set1 = set(['zhu shan wei','is']) 2 set2 = set1.copy() 3 set1.add('handsome') 4 set2.add('man') 5 print(set1) 6 print(set2) 7 print('\n') 8 9 set3 = set1.difference(set2) 10 print(set3) 11 print('\n') 12 13 set1.difference_update(set2) 14 print(set1) 15 print('\n') 16 17 set1.add('zhu shan wei') 18 set1.add('is') 19 print(set1) 20 set4 = set1.intersection(set2) 21 print(set4) 22 print('\n') 23 24 set1.intersection_update(set2) 25 print(set1) 26 print('\n') 27 28 set1.discard('is') 29 print(set1) 30 print('\n') 31 32 result1 = set1.isdisjoint(set2) 33 print(result1) 34 print('\n') 35 36 result2 = set1.issubset(set2) 37 print(result2) 38 print('\n') 39 40 result3 = set1.issuperset(set2) 41 print(result3) 42 print('\n') 43 44 set1.add('excellent') 45 set5 = set1.symmetric_difference(set2) 46 print(set5) 47 print('\n') 48 49 set1.symmetric_difference_update(set2) 50 print(set1) 51 print('\n') 52 53 set6 = set1.union(set2) 54 print(set6) 55 print('\n') 56 57 set6.update(['a']) 58 print(set6) 59 print('\n') 60 61 result4 = set6.pop() 62 print(result4) 63 print(set6) 64 print('\n') 65 66 result5 = set6.remove('a') 67 print(result5) 68 print(set6) 69 print('\n') 70 71 set6.clear() 72 print(set6)
{'zhu shan wei', 'handsome', 'is'}
{'zhu shan wei', 'is', 'man'}
{'handsome'}
{'handsome'}
{'zhu shan wei', 'handsome', 'is'}
{'zhu shan wei', 'is'}
{'zhu shan wei', 'is'}
{'zhu shan wei'}
False
True
False
{'excellent', 'is', 'man'}
{'is', 'excellent', 'man'}
{'zhu shan wei', 'excellent', 'is', 'man'}
{'zhu shan wei', 'excellent', 'is', 'man', 'a'}
zhu shan wei
{'excellent', 'is', 'man', 'a'}
None
{'excellent', 'is', 'man'}
set()
九、计数器 有序字典 默认字典 可命名元组 队列
以上功能都在collections模块中,使用时需要导入该模块 import collections;计数器可以对字符串或列表中元素的个数进行统计,并将统计的个数作为元素(键)对应的值形成字典,利用collections.Counter()方法,参数可以是字符串或者列表(变量也可),键对应的值从大到小排列,得到一个字典对象;得到计数器中的元素(键),利用obj.elements()方法,得到一个列表变量地址,要循环读出其内容;将一个字符串或者列表中的元素添加到一个计数器中,利用obj.update()方法,参数为字符串或者列表(变量也可);从一个计数器中减去部分内容,利用obj.subtract()方法,参数为字符串或者列表(变量也可),若没有对应的元素(键)或者元素不够,则计为负值
1 import collections 2 str_test = 'zhu shanwei' 3 list_test = ['is','a','handsome','man','is','excellent'] 4 obj1 = collections.Counter(str_test) 5 obj2 = collections.Counter(list_test) 6 print(obj1) 7 print(obj2) 8 print('\n') 9 10 list1 = obj2.elements() 11 list2 = [] 12 for elem in list1: 13 list2.append(elem) 14 print(list2) 15 print('\n') 16 17 list3 = ['and','is','a','very','good','man'] 18 obj2.update(list3) 19 print(obj2) 20 print('\n') 21 22 obj2.subtract(list3) 23 print(obj2) 24 print('\n')
Counter({'h': 2, 'z': 1, 'u': 1, ' ': 1, 's': 1, 'a': 1, 'n': 1, 'w': 1, 'e': 1, 'i': 1})
Counter({'is': 2, 'a': 1, 'handsome': 1, 'man': 1, 'excellent': 1})
['is', 'is', 'a', 'handsome', 'man', 'excellent']
Counter({'is': 3, 'a': 2, 'man': 2, 'handsome': 1, 'excellent': 1, 'and': 1, 'very': 1, 'good': 1})
Counter({'is': 2, 'a': 1, 'handsome': 1, 'man': 1, 'excellent': 1, 'and': 0, 'very': 0, 'good': 0})
字典是没有顺序的,所以不嫩用索引下标的方法来读取键对应的值,但列表可以,以列表中的元素作为键可以变相的进行索引,利用collections.OrderedDict()方法可以使字典变得有序
1 import collections 2 list1 = ['k1','k2','k3'] 3 dic1 = {} 4 dic1[list1[0]] = 'v1' 5 dic1[list1[1]] = 'v1' 6 dic1[list1[2]] = 'v1' 7 print(dic1) 8 list2 = [] 9 for i in range(3): 10 list2.append(dic1[list1[i]]) 11 print(list2) 12 print('\n') 13 14 dic2 = collections.OrderedDict() 15 dic2['k1'] = 'v1' 16 dic2['k2'] = 'v2' 17 dic2['k3'] = 'v3' 18 print(dic2) 19 list3 = [] 20 list4 = [] 21 for key in dic2: 22 list3.append(key) 23 list4.append(dic2[key]) 24 print(list3) 25 print(list4)
{'k1': 'v1', 'k2': 'v1', 'k3': 'v1'}
['v1', 'v1', 'v1']
OrderedDict([('k1', 'v1'), ('k2', 'v2'), ('k3', 'v3')])
['k1', 'k2', 'k3']
['v1', 'v2', 'v3']
默认字典可以对键对应的值进行类型的预设(例如想要键对应的值为一个列表,这一可以为键添加多个对应的值),利用collections.defaultdict()方法
1 import collections 2 dic = collections.defaultdict(list) 3 dic['k1'].append('v1') 4 dic['k2'].append('v2') 5 dic['k3'].append('v3') 6 print(dic) 7 print(dic['k1'])
defaultdict(<class 'list'>, {'k1': ['v1'], 'k2': ['v2'], 'k3': ['v3']})
['v1']
可命名元组,即为元组中的元素添加一个名称,可以通过名称访问元组中的元素,不必通过索引,利用class_name = collections.namedtuple('class_name', [])方法,第一个参数为设定的类名,第二个参数为给元组中元素添加的别名,然后创建对象obj = class_name(),参数为元组元素,不能用元组变量名
1 import collections 2 tuple_class = collections.namedtuple('tuple_class',['name','job','sex']) 3 obj = tuple_class('zhu shan wei','educated student','male') 4 print(obj.name) 5 print(obj.job) 6 print(obj.sex)
zhu shan wei
educated student
male
队列有双向队列和单项队列,创建一个双向队列,利用collections.deque()方法,参数可以为列表的变量名或者为空,不能为一系列字符串;浅拷贝一个队列,利用obj.copy()方法;在队列右边添加元素,利用obj.append()方法,参数为元素;在队列左边添加元素,利用obj.appendleft()方法,参数为元素;统计队列中某一元素的个数,利用obj.count()方法,参数为元素;在队列的右边扩展元素,利用obj.extend()方法,在队列左边扩展元素,利用obj.extendleft()方法,参数为一个列表或者列表变量名;查找队列中某一元素的索引,利用obj.index()方法,第一参数为元素,第二参数为起始位置,第三参数为介绍位置,不写默认为整个队列;向队列中在指定的索引位置插入元素,利用obj.insert()方法,第一参数为索引位置,第二参数为元素;从队列的右侧弹出一个元素,利用obj.pop()方法,从队列左侧弹出一个元素,利用obj.popleft()方法,弹出的元素均可被接收;从队列中移除指定元素,利用obj.remove()方法,参数为要移除的元素;将队列反转,利用obj.reverse()方法;将队列末尾的元素移到前面,利用obj.rotate()方法,参数为元素个数,默认为一个;清空一个队列,利用obj.clear()方法
1 import collections 2 list_test = ['zhu shan wei','is','a','handsome','man'] 3 test_queue = collections.deque(list_test) 4 test_queue1 = test_queue.copy() 5 print(test_queue) 6 print(test_queue1) 7 test_queue.append('excellent') 8 print(test_queue) 9 test_queue.appendleft('man') 10 print(test_queue) 11 result1 = test_queue.count('a') 12 print(result1) 13 list_test1 = ['good','kind'] 14 test_queue.extend(list_test1) 15 print(test_queue) 16 test_queue.extendleft(list_test1) 17 print(test_queue) 18 result2 = test_queue.index('is') 19 print(result2) 20 test_queue.insert(6,'kindhearted') 21 print(test_queue) 22 result3 = test_queue.pop() 23 print(result3) 24 result4 = test_queue.popleft() 25 print(result4) 26 test_queue.remove('kindhearted') 27 print(test_queue) 28 test_queue.reverse() 29 print(test_queue) 30 test_queue.rotate(3) 31 print(test_queue) 32 test_queue.clear() 33 print(test_queue)
deque(['zhu shan wei', 'is', 'a', 'handsome', 'man'])
deque(['zhu shan wei', 'is', 'a', 'handsome', 'man'])
deque(['zhu shan wei', 'is', 'a', 'handsome', 'man', 'excellent'])
deque(['man', 'zhu shan wei', 'is', 'a', 'handsome', 'man', 'excellent'])
1
deque(['man', 'zhu shan wei', 'is', 'a', 'handsome', 'man', 'excellent', 'good', 'kind'])
deque(['kind', 'good', 'man', 'zhu shan wei', 'is', 'a', 'handsome', 'man', 'excellent', 'good', 'kind'])
4
deque(['kind', 'good', 'man', 'zhu shan wei', 'is', 'a', 'kindhearted', 'handsome', 'man', 'excellent', 'good', 'kind'])
kind
kind
deque(['good', 'man', 'zhu shan wei', 'is', 'a', 'handsome', 'man', 'excellent', 'good'])
deque(['good', 'excellent', 'man', 'handsome', 'a', 'is', 'zhu shan wei', 'man', 'good'])
deque(['zhu shan wei', 'man', 'good', 'good', 'excellent', 'man', 'handsome', 'a', 'is'])
deque([])
单项队列中的元素先进先出,在queue模块中,使用时需导入模块 import queue,创建一个队列,利用方法obj=queue.Queue()方法,参数为队列长度,可以不写;向队列中添加元素,利用obj.put()方法,参数为元素;查看列表中元素的个数,利用obj.qsize()方法;从队列中取出一个元素,利用obj.get()方法;判断队列是否为空,利用obj.empty()方法,判断队列是否满了,利用obj.full()方法,返回布尔值
1 import queue 2 obj = queue.Queue(5) 3 obj.put('zhu shan wei') 4 obj.put('is') 5 print(obj) 6 result1 = obj.qsize() 7 print(result1) 8 result2 = obj.get() # 取队列中的数据,括号内可以设定参数,block=False为当队列中的内容为空时会抛出一个queue.Empty的异常,timeout=NUM为当内容为空时等待NUM秒后抛出queue.Empty异常,可以抓取这个异常来判断是否为空,
# 也可以用qsize或者empty来判定队列是否为空
9 print(result2)
10 result3 = obj.empty()
11 print(result3)
12 result4 = obj.full()
13 print(result4)
<queue.Queue object at 0x00000000023287F0>
2
zhu shan wei
False
False
import queue queue_test = queue.LifoQueue() # 定义一个后进先出的队列 queue_test.put(1) queue_test.put(2) queue_test.put(3) print(queue_test.get()) print(queue_test.get())
3
2
import queue queue_test2 = queue.PriorityQueue() # 定义一个具有优先级的队列 queue_test2.put((4,"zhao","qian")) # 放入的参数为一个元组,按照元组中的第一个元素进行排序,按照从小到大的顺序定义优先级从高到低,优先级高的先处理 queue_test2.put((3,"sun")) queue_test2.put((7,"zhou","wu","zheng")) print(queue_test2.get()) print(queue_test2.get())
(3, 'sun')
(4, 'zhao', 'qian')


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









