




使用hive带where条件查询发生错误
select uid,fullname from member_ro where uid >=0 and uid <20;
发现错误
java.io.IOException: cannot find class org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat
at org.apache.hadoop.hive.ql.io.CombineHiveInputFormat.getRecordReader(CombineHiveInputFormat.java:696)
at org.apache.hadoop.mapred.MapTask$TrackedRecordReader.<init>(MapTask.java:175)
在源码中查询该类HoodieParquetRealtimeInputFormat是
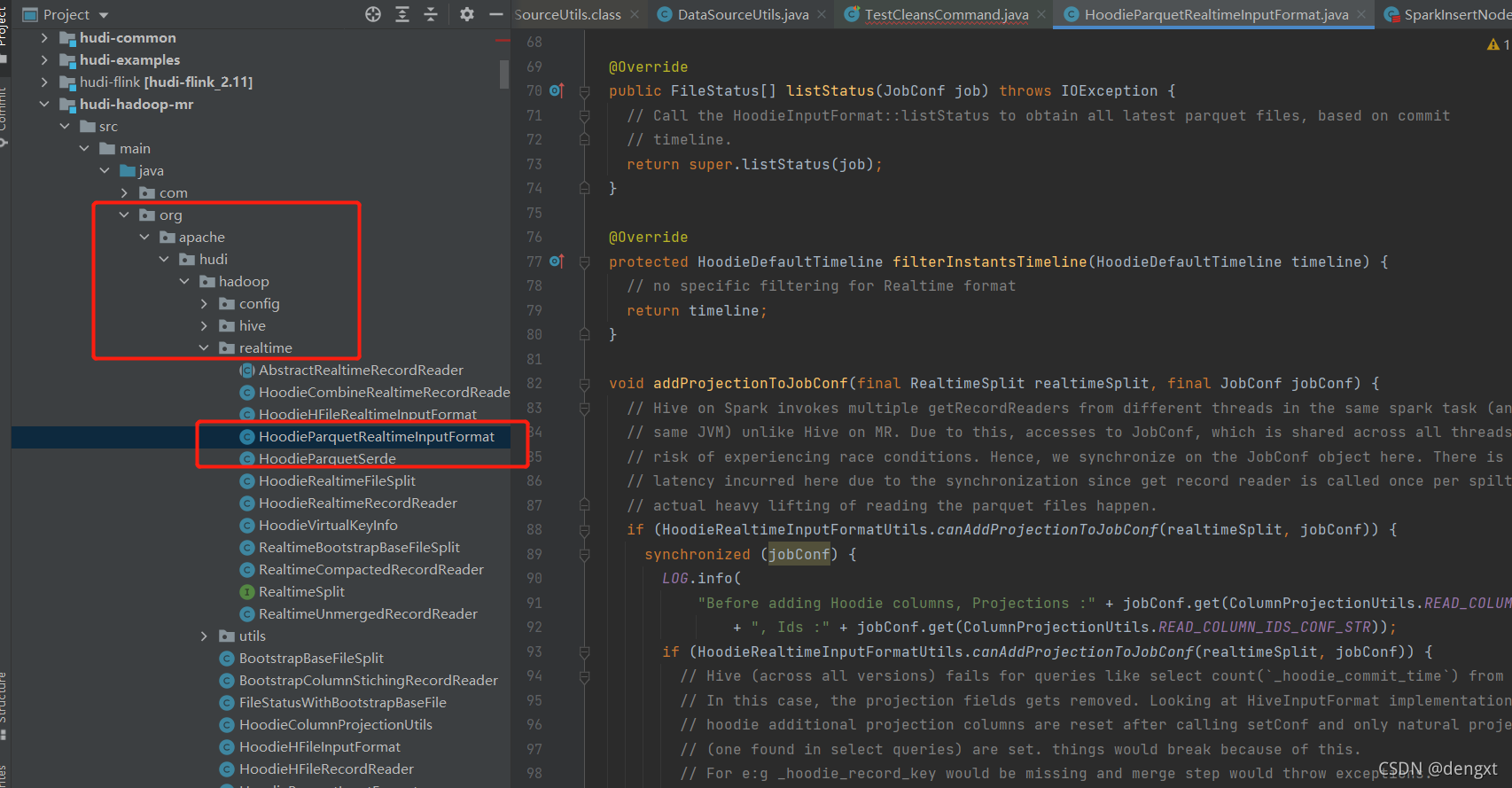
应该是在第3节中引入到hive lib下的 hudi-hadoop-mr-bundle-0.9.0.jar
尝试在hive query中加入
add jar hdfs://nameservice1/tmp/hiveshare/hudi-hadoop-mr-bundle-0.9.0.jar
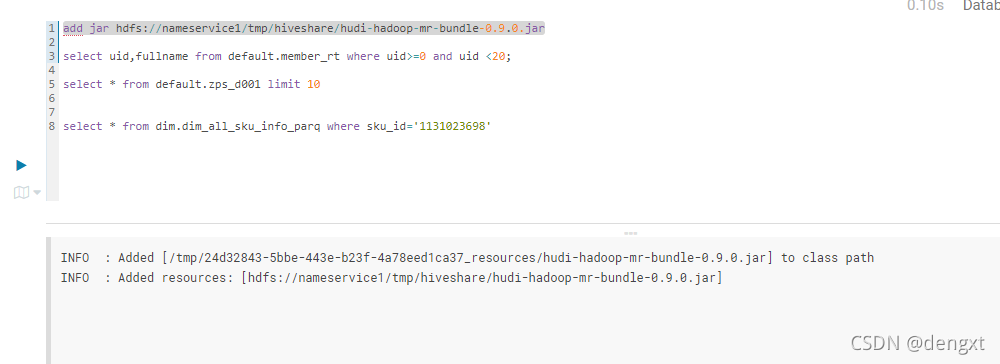
add jar 后 member_ro 可以根据条件查询,通过查询两个rt和ro的表的建表语句对比,发现
rt表存储输入格式的 (merge on read 表就会出现rt与ro copy on write 表只会出现一个表名且不带rt/ro)
STORED AS INPUTFORMAT 'org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat'
ro表存储输入格式的
STORED AS INPUTFORMAT
'org.apache.hudi.hadoop.HoodieParquetInputFormat'
其实 add jar hudi-hadoop-mr-bundle-0.9.0.jar 包里面包含 HoodieParquetInputFormat 和 HoodieParquetRealtimeInputFormat 但是就是rt的时候报如下错误
Caused by: java.lang.IllegalArgumentException: HoodieRealtimeRecordReader can only work on RealtimeSplit and not with hdfs://nameservice1/tmp/hudi/hivetest/20200918/WebA/0ac945ef-b1f1-4a64-96b9-faa18d7c5563-0_7-34-123_20210918173310.parquet:0+3037944
at org.apache.hudi.common.util.ValidationUtils.checkArgument(ValidationUtils.java:40)
at org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat.getRecordReader(HoodieParquetRealtimeInputFormat.java:116)查看源码
@Override
public RecordReader<NullWritable, ArrayWritable> getRecordReader(final InputSplit split, final JobConf jobConf,
final Reporter reporter) throws IOException {
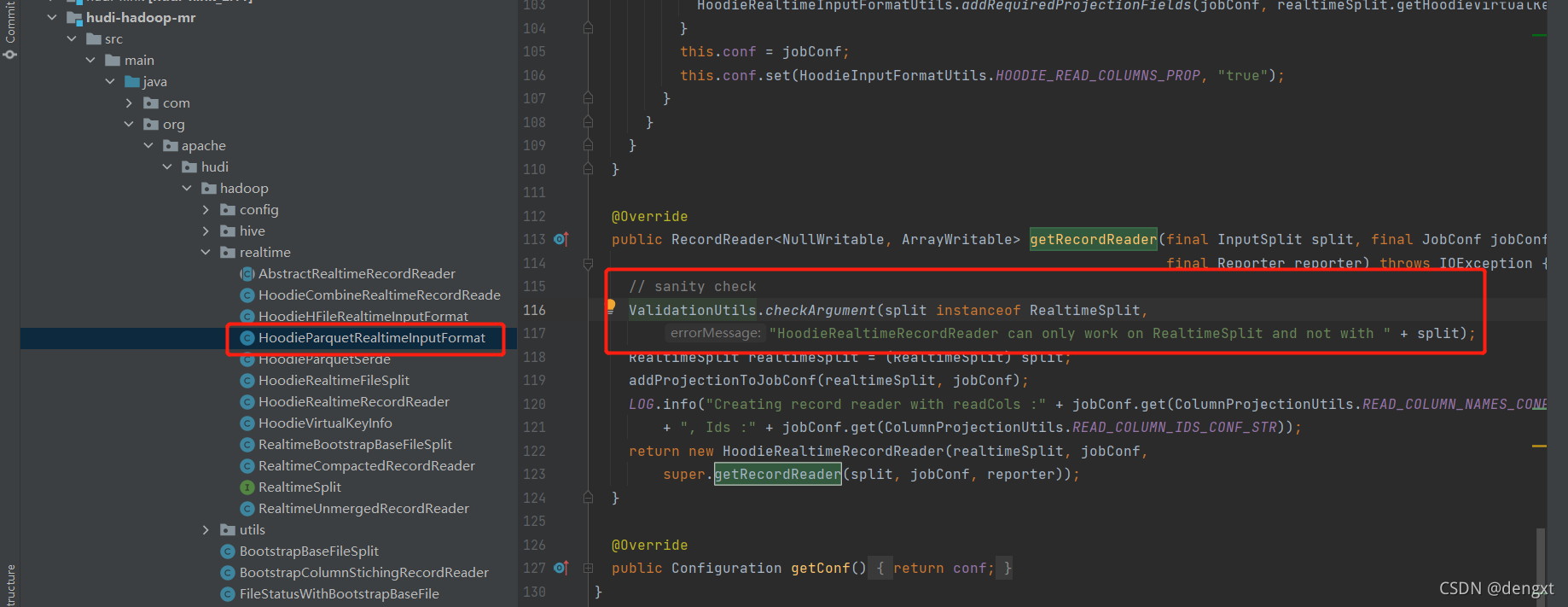
// sanity check 爆出的异常是如下检测这部分,将这个检测注释掉 重新编译
ValidationUtils.checkArgument(split instanceof RealtimeSplit,
"HoodieRealtimeRecordReader can only work on RealtimeSplit and not with " + split);
RealtimeSplit realtimeSplit = (RealtimeSplit) split;
addProjectionToJobConf(realtimeSplit, jobConf);
LOG.info("Creating record reader with readCols :" + jobConf.get(ColumnProjectionUtils.READ_COLUMN_NAMES_CONF_STR)
+ ", Ids :" + jobConf.get(ColumnProjectionUtils.READ_COLUMN_IDS_CONF_STR));
return new HoodieRealtimeRecordReader(realtimeSplit, jobConf,
super.getRecordReader(split, jobConf, reporter));
} 找到linux中源码的位置
找到linux中源码的位置
修改源码
/Hudi/hudi-hadoop-mr/src/main/java/org/apache/hudi/hadoop/realtime 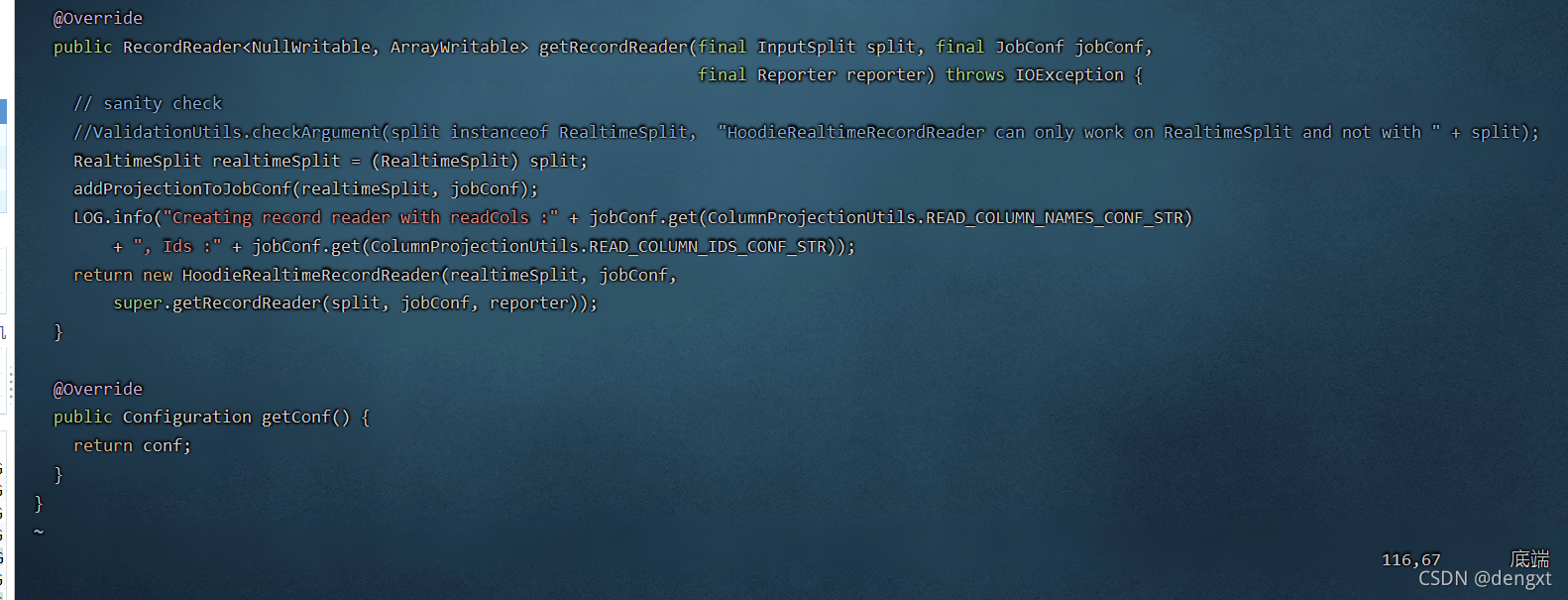
rt 的 hive 表依旧无法读取,暂时不测试hive读,用spark读取,可能原因是不兼容问题,后面用apache 版本测试后再补充
使用spark-shell
[xxx@xxx Hudi]# spark-shell
--master local[*]
--jars packaging/hudi-spark-bundle/target/hudi-spark-bundle_2.11-0.9.0.jar
--packages org.apache.spark:spark-avro_2.11:2.4.4,org.apache.spark:spark-sql_2.11:2.4.4 --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'scala> spark.sql("select uid,fullname from member_rt limit where uid >=0 and uid <20").show();
21/09/23 11:28:24 WARN lineage.LineageWriter: Lineage directory /var/log/spark/lineage doesn't exist or is not writable. Lineage for this application will be disabled.
+---+--------+
|uid|fullname|
+---+--------+
| 6|进行修改|
| 16|进行修改|
| 18|进行修改|
| 3|进行修改|
| 9|进行修改|
| 11|进行修改|
| 0|进行修改|
| 4|进行修改|
| 5|进行修改|
| 10|进行修改|
| 15|进行修改|
| 17|进行修改|
| 13|进行修改|
| 14|进行修改|
| 1|进行修改|
| 7|进行修改|
| 8|进行修改|
| 12|进行修改|
| 2|进行修改|
| 19|进行修改|
+---+--------+
使用spark sql就可以读取到member_rt表的变化
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3092
3092

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









