




 本文介绍如何使用Java实现科学网的用户信息爬取,包括解决URL中中文字符的转码问题,利用URLConnection发起请求并解析HTML内容,最终获取用户的ID和姓名。
本文介绍如何使用Java实现科学网的用户信息爬取,包括解决URL中中文字符的转码问题,利用URLConnection发起请求并解析HTML内容,最终获取用户的ID和姓名。
目录
爬取内容分析
本文以科学网为例讲解URLConnection的使用。如下图所示,为我们要爬取的第一个页面。即第一层。 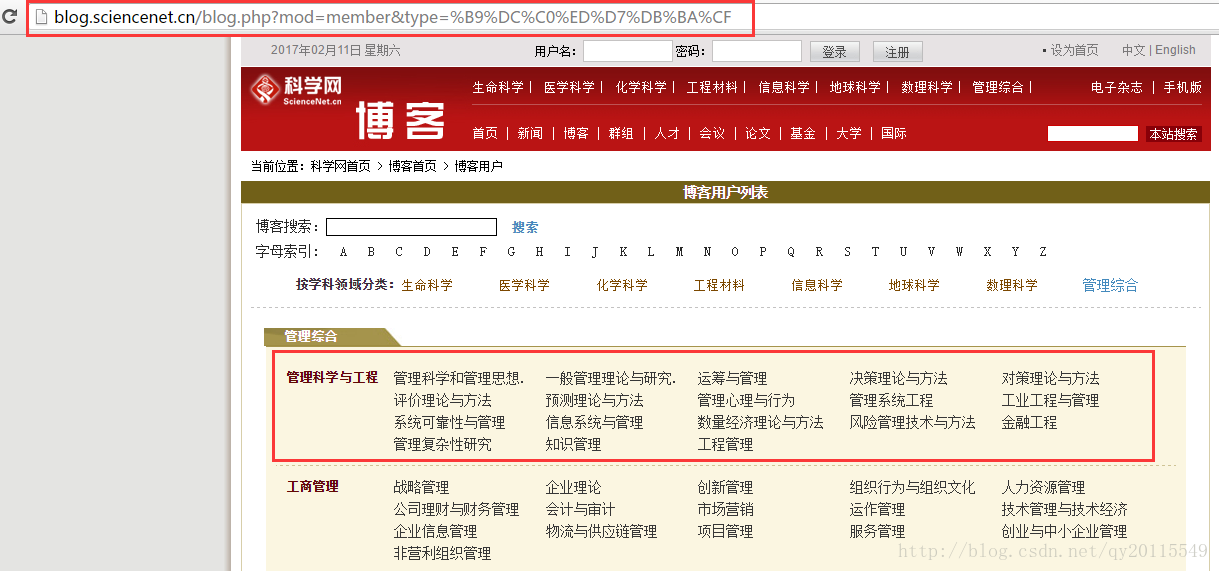
下图为我们要爬取的第二个页面,也是我们真正想要爬取的页面。即用户id及用户名。即第二层。 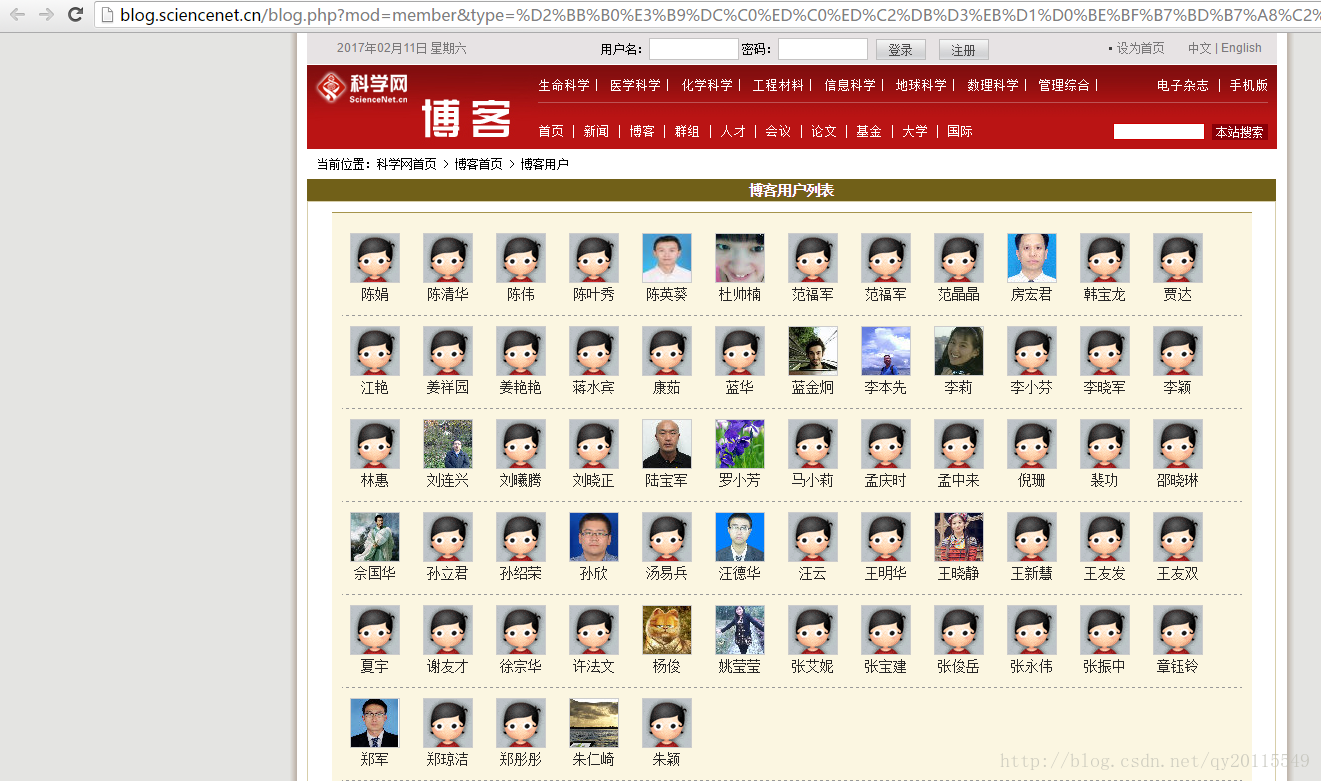
在爬取第二层的入口地址时,我们发现第一层获取的url中含有中文字符,所以要对其进行转码,获取可供请求的url。
下面提供本人自己写了一个,针对此网站的url转码方法,这个方法不对其他页面适用,如有其他页面也存在该问题,可在此基础上进行修改。
package collectip;
import java.io.UnsupportedEncodingException;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class UrlUtil {
private final static String ENCODE = "GBK";
public static String getURLEncoderString(String str) {
String result = "";
if (null == str) {
return "";
}
try {
result = java.net.URLEncoder.encode(str, ENCODE);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return result;
}
public static void main(String[] args) throws UnsupportedEncodingException {
String str = "blog.php?mod=member&type=管理科学和管理思想史&realmmedium=管理科学与工程&realm=管理综合&catid=565";
UrlTrans(str);
}
public static String UrlTrans(String str) {
//中文正则匹配,将中文进行转码,其他字符不变
Pattern p = Pattern.compile("([\u4e00-\u9fa5]+)");
Matcher m = p.matcher( str );
String mv = null;
List<String> list=new ArrayList<String>();
while (m.find()) {
mv = m.group(0);
list.add(getURLEncoderString(mv));
}
//找出id,即565
String regEx="[^0-9]";
Pattern p1 = Pattern.compile(regEx);
Matcher m1 = p1.matcher(str);
String url=" http://blog.sciencenet.cn/blog.php?mod=member&type="+list.get(0)+"&realmmedium="+list.get(1)+"&realm="+list.get(2)+"&catid="+m1.replaceAll("").trim();
System.out.println(url);
return url;
}
}URLConnection的使用
URLConnection是java自带的请求url的工具。下面将以爬取科学网的用户为例,讲解其使用。下面程序可复制下来,直接运行,并求注释已经很清晰明了。
package navi.main;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import collectip.UrlUtil;
public class JsonTest {
public static void main(String[] args) throws Exception {
//使用URLConnection请求url,并返回html字符,这里使请求第一层数据,获取第二层请求的url
String html = getRawHtml("http://blog.sciencenet.cn/blog.php?mod=member&type=%B9%DC%C0%ED%D7%DB%BA%CF");
//使用Jsoup方式进行解析html
Document document=Jsoup.parse(html);
Elements elements=document.select("div[class=box_line]").get(0).select("li").select("a");
for (Element ele: elements) {
//第二层请求,为了爬取用户信息
String html1 = getRawHtml(UrlUtil.UrlTrans(ele.attr("href")));
//使用Jsoup方式进行解析html1
Document document1=Jsoup.parse(html1);
Elements elements2=document1.select("div[id=con_box]").select("p[class=potfont]").select("a");
for (Element ele1: elements2) {
//匹配字符串中的数字,获取id
String idtest=ele1.attr("href");
String regEx="[^0-9]";
Pattern p1 = Pattern.compile(regEx);
Matcher m1 = p1.matcher(idtest);
String id=m1.replaceAll("").trim();
//获取用户名
String name=ele1.text();
System.out.println(id+"=="+name);
}
}
}
//URLConnection方法
public static String getRawHtml(String personalUrl) throws InterruptedException,IOException {
//使用URLConnection请求数据
URL url = new URL(personalUrl);
URLConnection conn = url.openConnection();
InputStream in=null;
try {
conn.setConnectTimeout(3000);
in = conn.getInputStream();
} catch (Exception e) {
}
//将获取的数据转化为String
String html = convertStreamToString(in);
return html;
}
//这个方法是将InputStream转化为String
public static String convertStreamToString(InputStream is) throws IOException {
if (is == null)
return "";
BufferedReader reader = new BufferedReader(new InputStreamReader(is,"gbk"));
StringBuilder sb = new StringBuilder();
String line = null;
try {
while ((line = reader.readLine()) != null) {
sb.append(line);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
reader.close();
return sb.toString();
}
}
运行结果展示
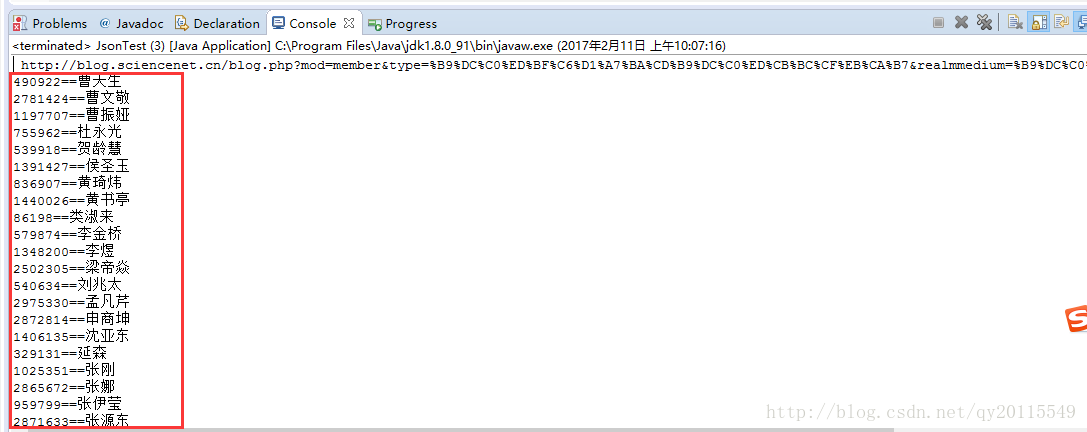
转载地址: https://blog.youkuaiyun.com/qy20115549/article/details/54980904

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









