



SparkSQL和Hive都是大数据处理领域中的重要工具,它们各自具有独特的特点和优势。以下是SparkSQL和Hive的异同点的详细分析:
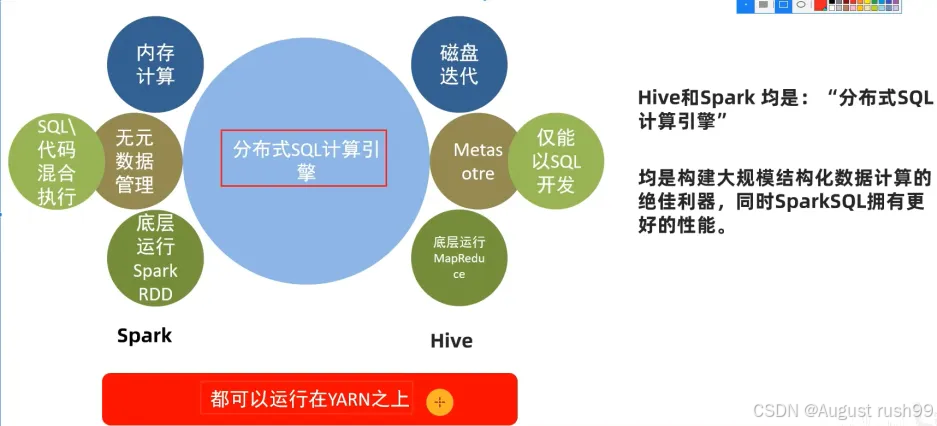
相同点
-
分布式计算引擎:
- SparkSQL和Hive都是分布式SQL计算引擎,能够处理大规模的数据集。
-
处理结构化数据:
- 两者都专注于处理结构化数据,提供了类似SQL的查询语言,使得用户能够方便地进行数据分析和处理。
-
运行在YARN集群上:
- SparkSQL和Hive都可以运行在Hadoop的YARN集群上,充分利用集群的计算和存储资源。
不同点
-
计算方式:
- SparkSQL是基于内存的计算引擎,它利用Spark的弹性分布式数据集(RDD)和DataFrame等抽象,将数据加载到内存中,从而加速查询性能。
- Hive则基于磁盘进行计算,它使用Hadoop的MapReduce或Tez等计算框架,将查询任务分解为多个小任务,并在集群中并行执行。
-
元数据管理:
- SparkSQL没有自身的元数据管理功能,它依赖于外部的数据源或数据仓库来提供元数据。
- Hive则使用Metastore进行元数据管理,Metastore是一个独立的存储系统,用于存储Hive表的元数据、数据库信息等。
-
底层执行框架:
- SparkSQL的底层执行框架是RDD或DataFrame等Spark自身的抽象,这些抽象提供了丰富的API,使得用户可以方便地进行数据转换和查询优化。
- Hive的底层执行框架则是MapReduce或Tez等Hadoop的计算框架,这些框架提供了分布式计算的能力,但相对于Spark来说可能较为笨重。
-
查询语言和功能:
- SparkSQL支持标准的纯SQL查询,或者纯代码执行,或者混合执行,并且提供了丰富的函数和API,如窗口函数、聚合函数、用户自定义函数等,使得用户能够进行复杂的数据分析和处理。
- Hive只支持标准的SQL查询,但它更侧重于批处理和分析,提供了丰富的分析函数和统计函数。然而,与SparkSQL相比,Hive的查询语言可能较为有限,且在某些方面可能不够灵活。
-
应用场景:
- SparkSQL适用于需要快速查询和实时数据处理的场景,如流处理、交互式查询等。它能够充分利用内存资源,提供快速的查询性能。
- Hive则更适用于大规模数据的离线分析和批处理场景。它提供了丰富的分析函数和统计函数,使得用户能够对大规模数据进行深入的分析和挖掘。
综上所述,SparkSQL和Hive在大数据处理领域中都发挥着重要的作用,但它们各自具有不同的特点和优势。在选择使用哪种工具时,需要根据具体的应用需求、数据规模和现有的基础设施进行综合考虑。

















 1010
1010

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









