







 文章描述了一个通过-javaagent方式使用的jmx_prometheus_javaagent-0.15.0.jar在OpenJDK1.8.0_242上遇到的问题,表现为无法获取监控数据,原因是CPU占用过高,由一个死循环引起。分析发现该问题可能与JDK的NativeMethod相关,且在JDKbug库中找到类似问题。解决方案包括重启应用和升级JDK到11.0.8以上版本。同时,文中还提及Sentinel组件存在相同问题,提供了相应的解决策略。
文章描述了一个通过-javaagent方式使用的jmx_prometheus_javaagent-0.15.0.jar在OpenJDK1.8.0_242上遇到的问题,表现为无法获取监控数据,原因是CPU占用过高,由一个死循环引起。分析发现该问题可能与JDK的NativeMethod相关,且在JDKbug库中找到类似问题。解决方案包括重启应用和升级JDK到11.0.8以上版本。同时,文中还提及Sentinel组件存在相同问题,提供了相应的解决策略。
1. 问题描述
通过 -javaagent 方式挂载的 jmx_prometheus_javaagent-0.15.0.jar 代理包对接prometheus监控,通过暴露的HTTP服务端口无法获取监控数据。
OpenJDK:1.8.0_242-b08
jmx_prometheus_javaagent:0.15.0
2. 问题分析
- netstat 查看服务端口状态,发现存在大量的 CLOSE_WAIT状态的连接;

- 通过 top 命令发现应用进程比正常情况下占用高;
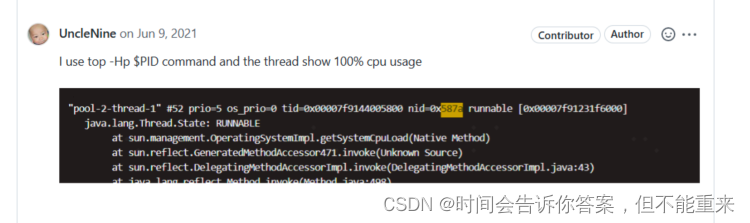
- 通过 top -o +%CPU -Hp {PID} 查看进程线程信息,发现 prometheus-http 线程 CPU占用 99%;
- printf ‘%x\n’ {PID} 将十进制线程ID转换为十六进制,注意此PID为第3步占用CPU高的线程ID;
- jstack -l {PID} > jstack.txt,注意此 PID 为Java进程ID;
- 打开 jstack.txt,搜索第4步中得到的十六进制的线程ID;
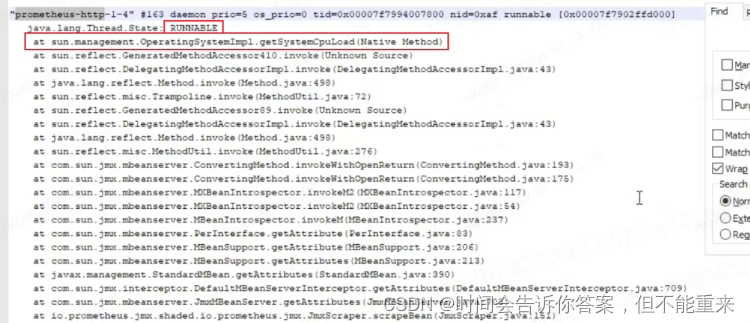
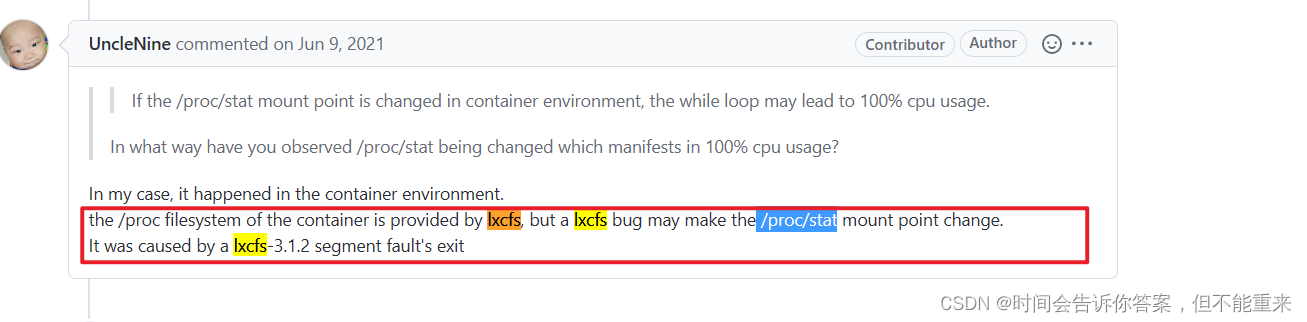
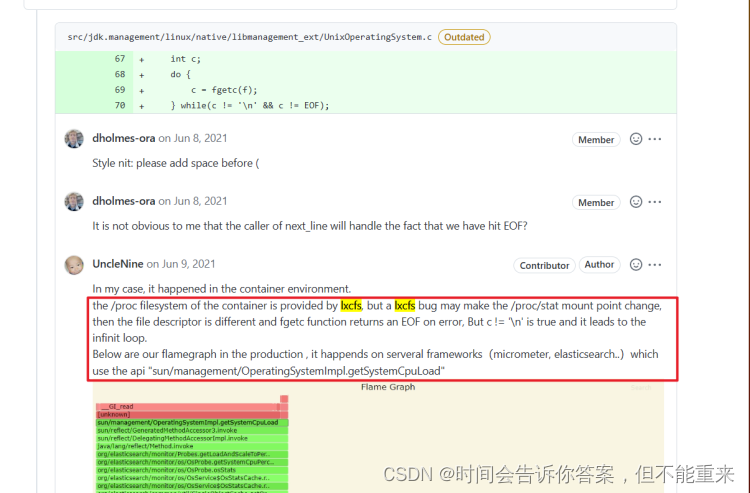
此线程名称为 prometheus-http-1-4 的守护线程(daemon),状态为 RUNNABLE,正在执行 sun.management.OperatingSystemImpl.getSystemCpuLoad(Native Method) 获取系统CPU负载信息, - 查看JDK源码,发现当 fgetc(f) != ‘\n’ 时就会进入死循环状态,我们知道死循环会导致CPU过高,这可能就是无法获取监控数据的元凶
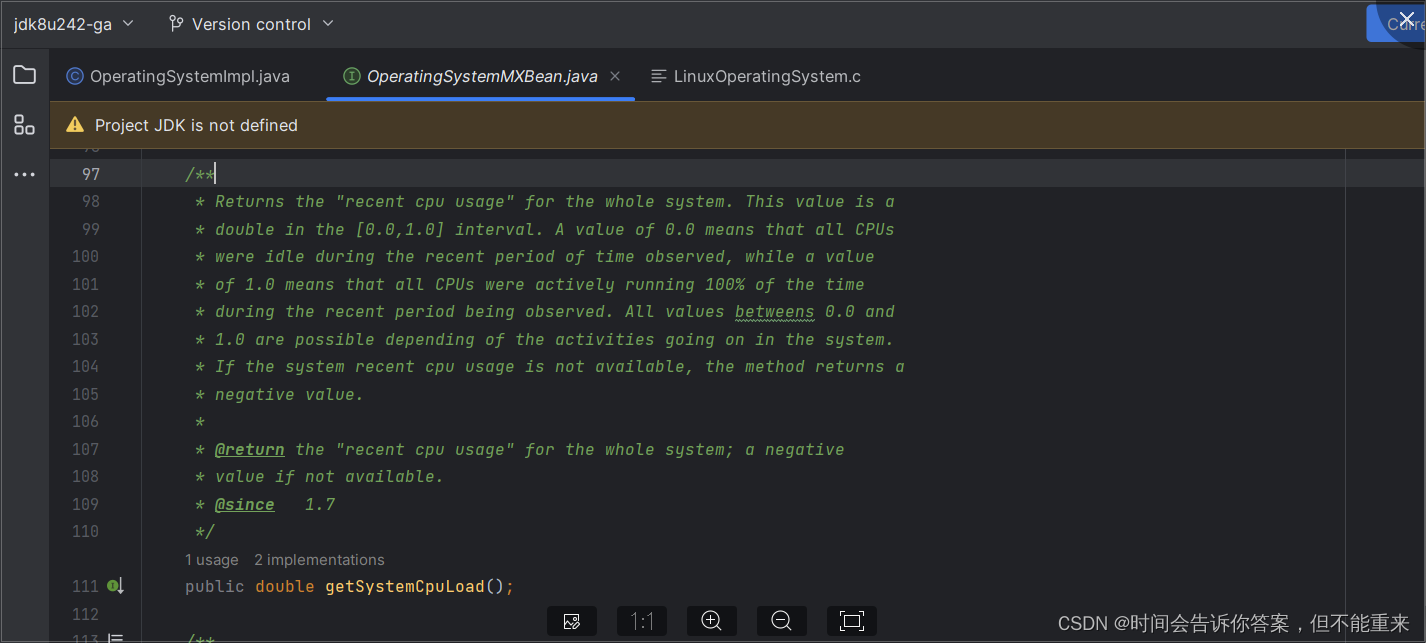
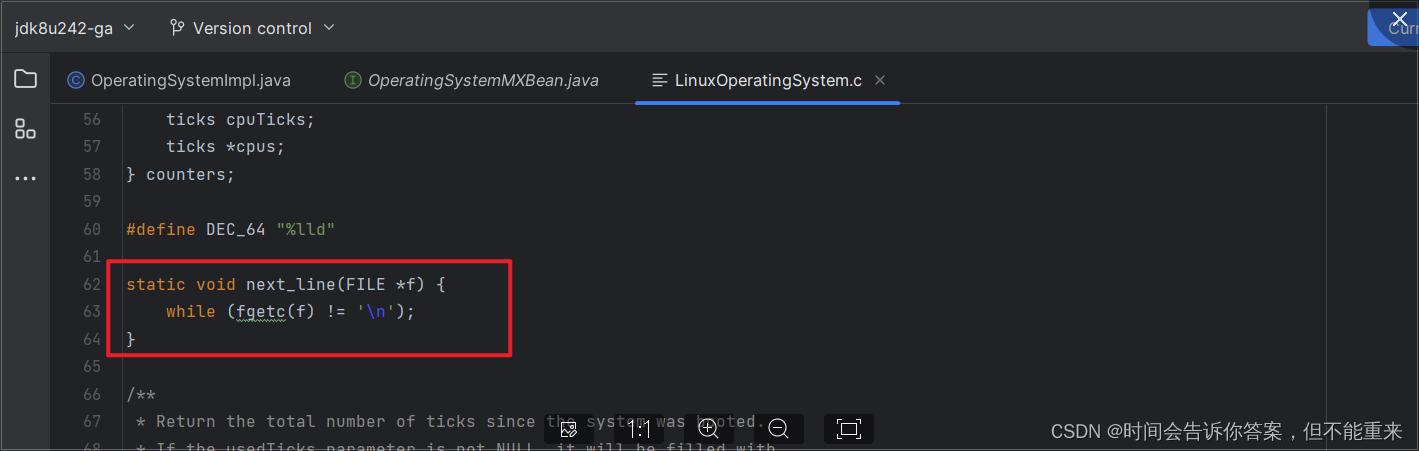
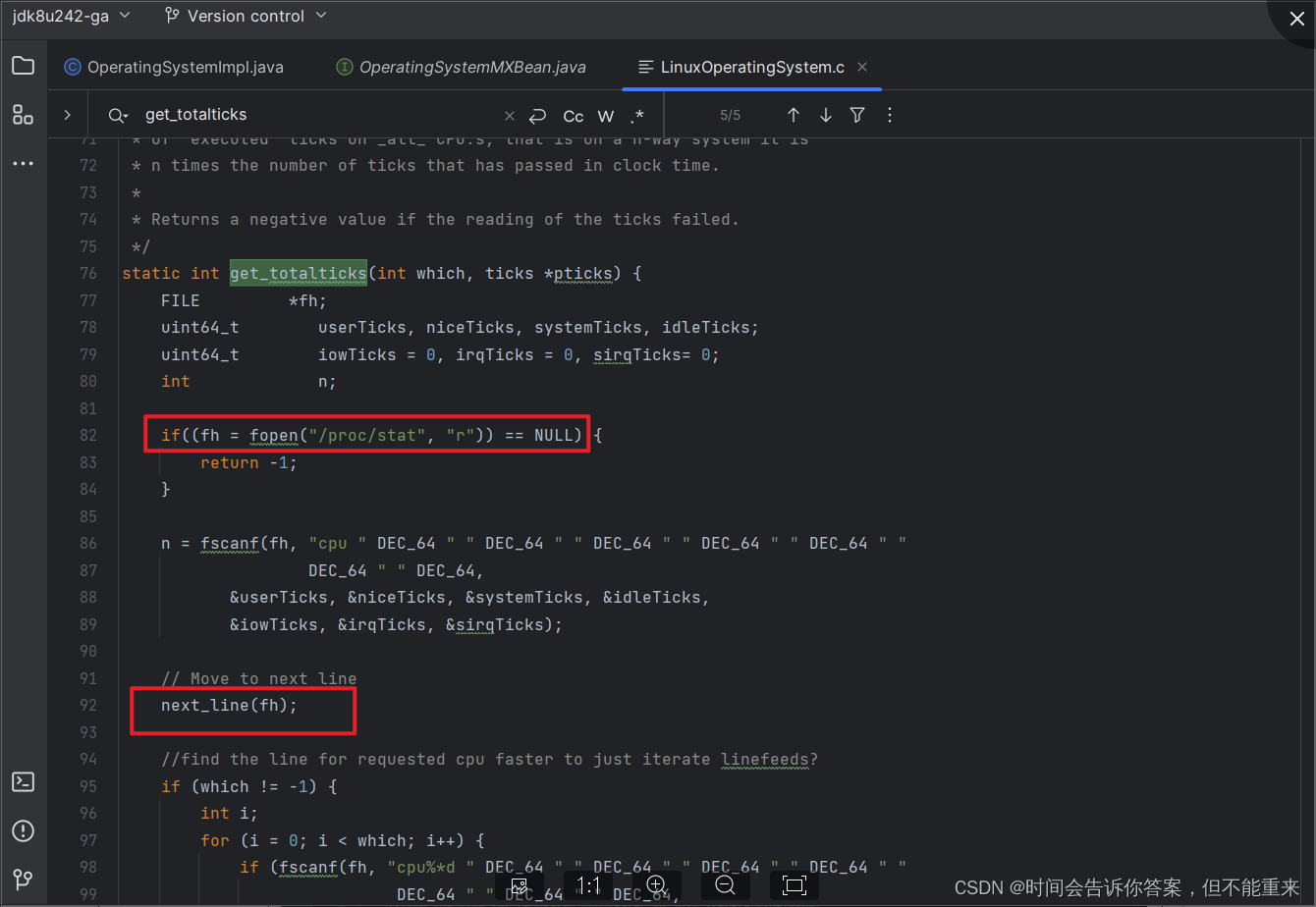
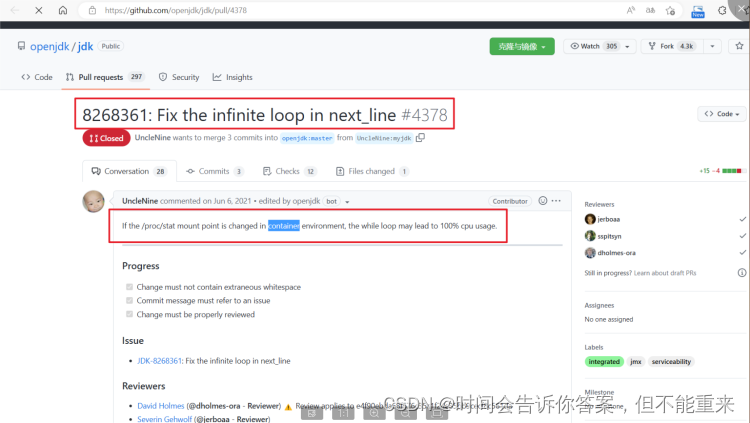
- 在JDK bug库中碰碰运气,看有没有类似bug,看看是否在哪个JDK 版本已经修复
https://github.com/openjdk/jdk/pull/4378
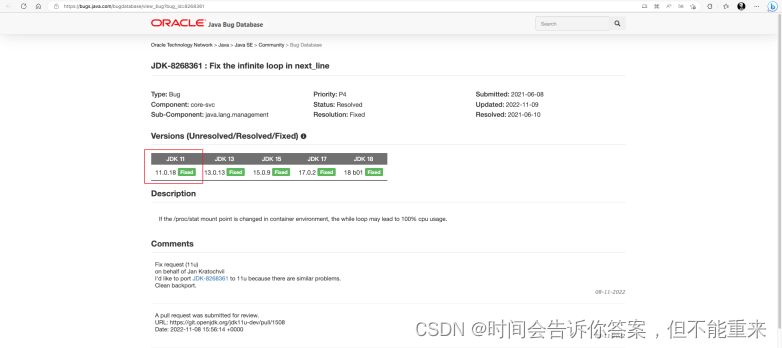
https://bugs.openjdk.org/browse/JDK-8268361
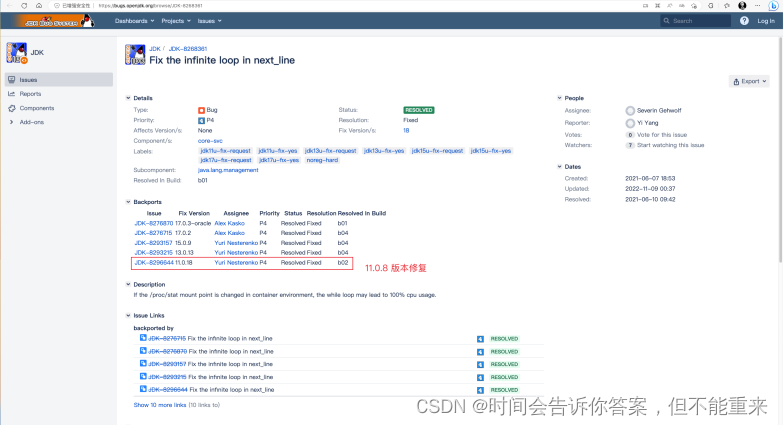
https://bugs.java.com/bugdatabase/view_bug?bug_id=8268361
3. 解决方法
临时解决方法:重启应用
永久解决方法:升级JDK版本到 11.0.8 或更高版本
4. 其它
在排查问题的过程中发现 sentinel-system 组件存在同样的问题。
https://github.com/alibaba/Sentinel/issues/2885
https://github.com/alibaba/Sentinel/issues/1206
解决方法1:把获取CPU负载信息的插槽去掉
解决方法2:升级JDK版本到11.0.8或更高版本

















 5453
5453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









