



LeetCode 151.反转字符串中的单词:
看到题目后的思路:
① 先去除多余的空格,包括前后空格和中间的多余空格。思路与前面原地移除多余元素相同。
② 反转整个字符串
③ 再反转字符串中的单个单词。反转的思想与前面字符串反转相同。
需要注意的是:去除多余空格时:①单词后加空格在遇到/开始另一个单词时更好;②循环中嵌套循环while改变 i ,使用range的话,内层循环改变的 i 对外层循环无影响。③原地删除空格后需要将多余的元素删除并更新列表的长度
class Solution(object):
def reverseWords(self, s):
"""
:type s: str
:rtype: str
"""
s_list = list(s)
len_s = len(s_list)
len_s = self.removeBlank(s_list, len_s)
self.reverse(s_list, 0, len_s - 1)
# 反转每个单词
start = 0
for i in range(len_s + 1):
if i == len_s or s_list[i] == " ":
self.reverse(s_list, start, i - 1)
start = i + 1
return "".join(s_list)
# 反转字符串
def reverse(self, s, start, end):
left, right = start, end
while left < right:
s[left], s[right] = s[right], s[left]
left += 1
right -= 1
# 移除多余空格
def removeBlank(self, s, len_s):
i, slow = 0, 0
# 循环中嵌套循环,且改变了i,使用while更合适
while i < len_s:
if s[i] != " ":
# 单词后加空格在遇到下一个单词时
if slow != 0:
s[slow] = " "
slow += 1
while i < len_s and s[i] != " ":
s[slow] = s[i]
slow += 1
i += 1
i += 1
del s[slow: len_s]
return slow
# 算更简便的
class Solution(object):
def reverseWords(self, s):
# 删除前后空白
s = s.strip()
# 反转整个字符串
s = s[::-1]
# 将字符串拆分成单词,反转每个单词
s = ' '.join(word[::-1] for word in s.split())
return s
实现过程遇到的问题:
① 去除空格时,在单词后添加空格在遇到下一个单词时更好,不然会超界
② range循环中嵌套while,当while改变 i 的值时,对range循环中的 i 无影响
③ 删除多余空格后,需要删除列表中的多余元素和返回新列表的长度
卡码网:55.右旋转字符串:
看到题目后的思路:
和上一题相同,整体反转+局部反转。先反局部再反整体或者先反整体再反局部都可以,但是需要注意序号

# 先整体后局部
def right(s, k):
s_list = list(s)
s_list = s_list[::-1] # 先反整体
s_list = s_list[k - 1::-1] + s_list[:k - 1:-1] # 反局部
return "".join(s_list)
k = int(input())
s = input()
result = right(s, k)
print(result)
# 先局部后整体
def right(s, k):
s_list = list(s)
s_len = len(s_list)
s_list = s_list[s_len - k - 1::-1] + s_list[:s_len - k - 1:-1]
s_list = s_list[::-1]
return "".join(s_list)
实现过程中遇到的问题:
对于python中的步长为-1时的切片取值不熟悉。
先整体后局部:
反局部,要反的部分为0~k - 1, k ~ len - 1
不管步长为多少,只看读取元素的顺序确定start和end。第一个部分从k - 1 读到 0,因此为s_list[k - 1::-1];第二个部分从len - 1读取到k,start可以为0, end为k - 1(因为切片取不到end),第二个部分是s_list[:k - 1: -1]
LeetCode 28. 实现strStr():
题目实现思路:KMP
本题是找模式串在文本串中第一次出现的下标。
使用双指针进行匹配,暴力的思路是匹配失败后从文本串的下一个字符开始匹配。KMP则利用了前面已经匹配过的字符来进行回退。
KMP通过前缀表利用前面已经匹配过的字符串,前缀表中序号为 i 对应的值为字符串中截取到序号为 i 的最长相等前后缀的长度。(此处的前缀指包含第一个字符不包含最后一个字符的子字符串;后缀为包含最后一个字符不包含第一个字符的子字符串)
匹配过程如下:
当前匹配失败,j 进行回退,回退到前缀表下标为 j - 1对应的值。
① j 匹配失败,回退选择的前缀表的下标为 j - 1:前缀表中的值是最长相等前后缀,而当前 j 匹配失败,前面匹配成功,因此选择的是 j - 1对应的最长相等前后缀的长度
② j 为下标, 前缀表中的值为长度, j 直接等于长度:下标从0开始,长度从1开始,前缀表中的值可以理解为最长相等前后缀中前缀紧贴的下一个元素的下标,现在最长相等前后缀部分匹配成功,当然要从前缀的后一个元素开始匹配。

j 回退到相应的位置重新开始匹配

KMP的代码实现
KMP实现过程中的next数组也就是前缀表的利用,此处使用不减1也不右移的前缀表作为next数组。
① 获得next数组
使用双指针, i 遍历指向模式串, j 指向最长相等前后缀的前缀下标
i 从1开始遍历(第一个元素是固定的前缀为0,因此从第二个元素开始遍历)
当 s[i] != s[j]时,j 不断往后回退并对 s[i] 和 s[j] 进行重新判断
当 s[i] == s[j]时,j 向后移动(此时 j 的值为最长相等前后缀的长度)
最后 next[i] = j
def getNext(self, s):
len_s = len(s)
next_s = [0] * len_s
j, next_s[0] = 0, 0
for i in range(1, len_s):
while j > 0 and s[i] != s[j]: # 不相等j回退
j = next_s[j - 1]
if s[i] == s[j]:
j += 1
next_s[i] = j # 前缀表,最长相等前后缀长度
return next_s
② 模式串与文本串的匹配过程:
双指针, i 指向文本串, j 指向模式串。
当 haystack[i] != needle[j]时, j 不断向后回退
当 haystack[i] == needle[j]时, j 向后移动(i 的移动在for循环中)
最后判断是否匹配成功: j 是否等于 模式串的长度 len, 如果等于,此时 i 指向的相当于 len - 1,因此第一个匹配项的下标为 i - len + 1
def strStr(self, haystack, needle):
"""
:type haystack: str
:type needle: str
:rtype: int
"""
if len(needle) == 0:
return 0
next_n = self.getNext(needle)
len_n, j =len(needle), 0
for i in range(len(haystack)):
while j > 0 and haystack[i] != needle[j]:
j = next_n[j - 1]
if haystack[i] == needle[j]:
j += 1
if j == len_n: # 匹配成功
return i - len_n + 1
return -1
实现过程中遇到的问题:
对于next数组为前缀表 - 1的KMP还需要分析一下
LeetCode 459.重复的子字符串:
看到题目后的思路:
- 移动匹配
若S由重复的子串构成,那么S + S去除头尾字符后一定包含S
S由重复的子串构成,那么S要么是两边相等,要么两边去除中心元素后相等。
如下图,其中p不是S的最小重复子串,只是表示S的两边是否相等

class Solution(object):
def repeatedSubstringPattern(self, s):
"""
:type s: str
:rtype: bool
"""
if len(s) <= 1:
return False
ss = s[1:] + s[:-1]
#print(ss.find(s)) # 存在返回开始的索引,不存在返回-1
return ss.find(s) != -1
- KMP
最长相等前后缀不包含的部分如下图蓝色所示:
其中m为S的最小重复子串
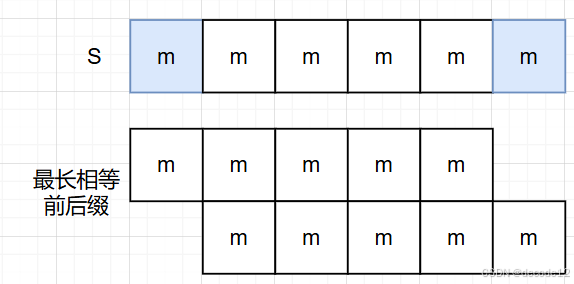
充分性:如果字符串由重复的子串构成,那么字符串中最长相等前后缀不包含的部分为最小重复子串
必要性:如果字符串中最长相等前后缀不包含的部分为最小重复子串,那么字符串一定由重复的字符串构成。
什么时候是最小重复子串:
1)若S的长度不能被最长相等前后缀不包含部分的长度整除,那么一定不是最小重复子串
2)若S的长度能被最长相等前后缀不包含部分的长度整除,那么是最小重复子串。
如下:不包含部分S[0]S[1] = t[0]t[1],又t[0]t[1] = S[2]S[3],故S[0]S[1] = S[2]S[3],
因为是相同前后缀,因此S[2]S[3] = t[2]t[3],又t[2]t[3]与S[4]S[5]是一个字符串,故S[2]S[3] = S[4]S[5]
循环得到S[4]S[5] = S[6]S[7]
因此字符串S由重复的S[1]S[2]组成,S[1]S[2]是最小重复子串

class Solution(object):
def repeatedSubstringPattern(self, s):
len_s = len(s)
if len_s <= 1:
return False
next_s = self.getNext(s, len_s)
if next_s[- 1] != 0 and len_s % (len_s - next_s[-1]) == 0:
return True
return False
def getNext(self, s, len_s):
next_s = [0] * len_s
j, next_s[0] = 0, 0
for i in range(1, len_s):
while j > 0 and s[i] != s[j]:
j = next_s[j - 1]
if s[i] == s[j]:
j += 1
next_s[i] = j
return next_s
实现过程中遇到的问题:
python中没有mod运算符,只有%,以及最后判断len_s是否能被最长相等前后缀不包含的部分的长度整除是 len_s % (len_s - next_s[-1])
学习收获:
KMP算法,python中的步数为负的切片使用,局部反转和整体反转相结合


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









