




 本文详细介绍如何在三节点集群上安装和配置Spark分布式环境,包括节点规划、免密码登录配置、JDK安装、Spark下载与解压、环境变量设置、集群启动及验证。
本文详细介绍如何在三节点集群上安装和配置Spark分布式环境,包括节点规划、免密码登录配置、JDK安装、Spark下载与解压、环境变量设置、集群启动及验证。
文章目录
Spark分布式安装
规划
| 节点IP | 节点名称 | 节点备注 |
|---|---|---|
| 192.168.206.128 | bigdata01 | Master节点 |
| 192.168.206.129 | bigdata02 | Worker节点 |
| 192.168.206.130 | bigdata03 | Worker节点 |
-
配置集群节点间免密码登录。见《完全分布式 Hadoop配置》
-
在集群节点上安装JDK8,设置JAVA-HOME环境变量。
-
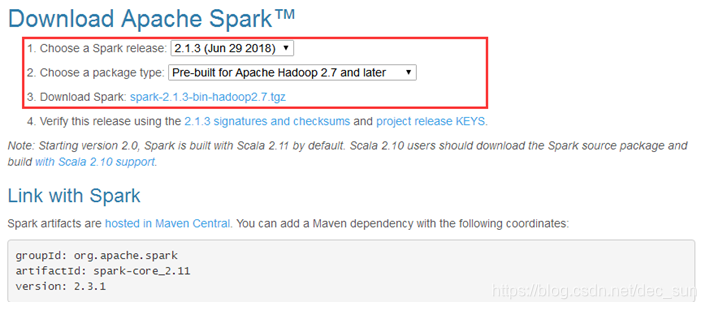
访问Spark官方网站http://spark.apache.org/,点击Download Spark按钮。选择Spark版本2.1.3以及对应的Hadoop版本2.7,点击spark-2.1.3-bin-hadoop2.7.tgz链接,下载Spark。
-
上传spark-2.1.3-bin-hadoop2.7.tgz到Master节点的/opt目录下。
-
解压spark-2.1.3-bin-hadoop2.7.tgz到当前目录,并将解压后的目录重命名为spark213,减少目录名的长度,方便后续路径配置。
[root@bigdata01 opt]# tar -zxvf spark-2.1.3-bin-hadoop2.7.tgz
[root@bigdata01 opt]# mv spark-2.1.3-bin-hadoop2.7 spark213
- 进入/opt/spark213/conf目录,拷贝目录中的slaves.template文件,并重命名为slaves。
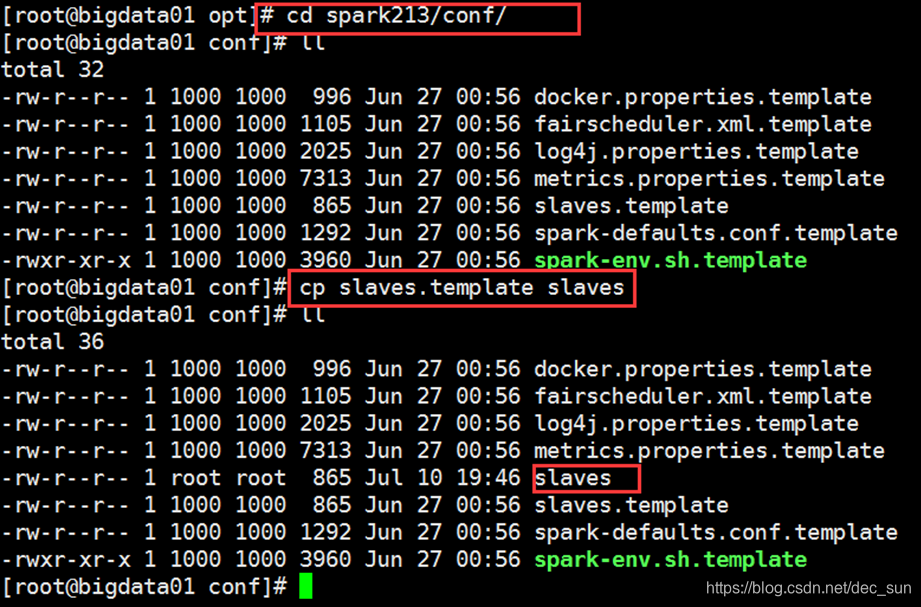
- 编辑slaves文件,在slaves文件中,注释localhost行,增加集群规划中的Worker节点主机名。每行一个主机名。保存退出。

- 分别拷贝spark213目录到Worker节点中的/opt目录。
[root@bigdata01 conf]# scp -r /opt/spark213 bigdata02:/opt/
[root@bigdata01 conf]# scp -r /opt/spark213 bigdata03:/opt/
-
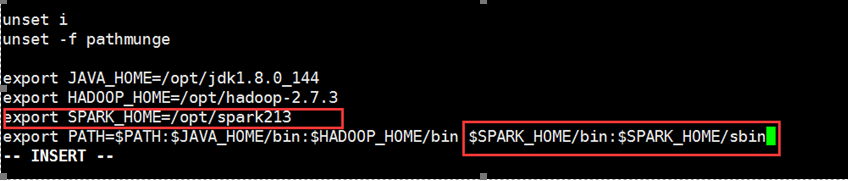
在3个集群节点中,分别设置SPARK_HOME环境变量。并运行source命令,使环境变量生效。
-
启动Spark。在Master节点,进入/opt/spark213/sbin目录,运行./start-all.sh命令:

-
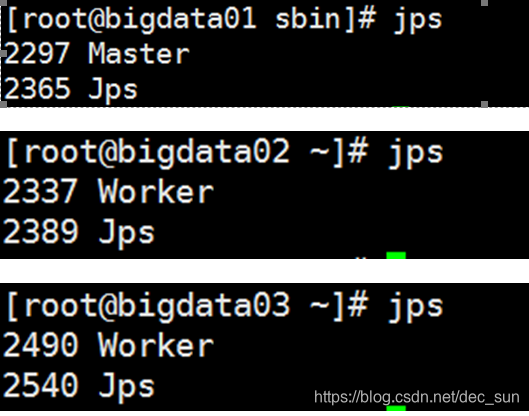
使用jps命令验证Spark是否启动成功。如果在Master节点,有master进程,在Worker节点,有worker进程,说明Spark启动成功。
-
访问Spark UI界面,地址为:http://master节点IP:8080
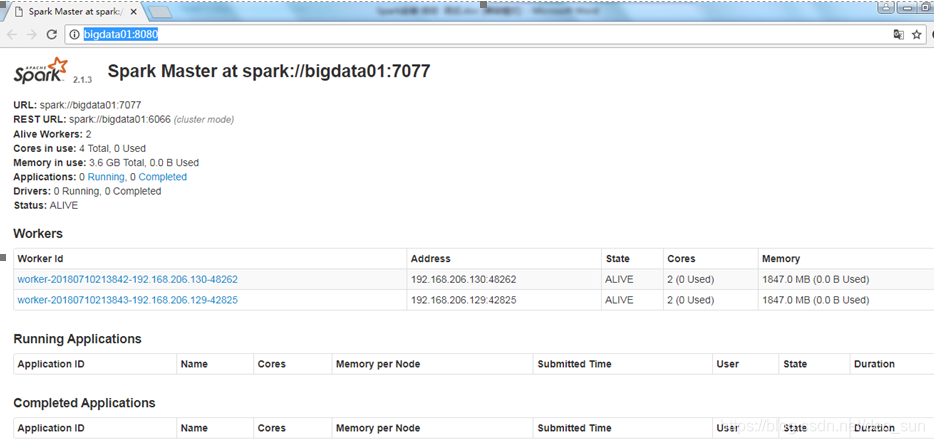
-
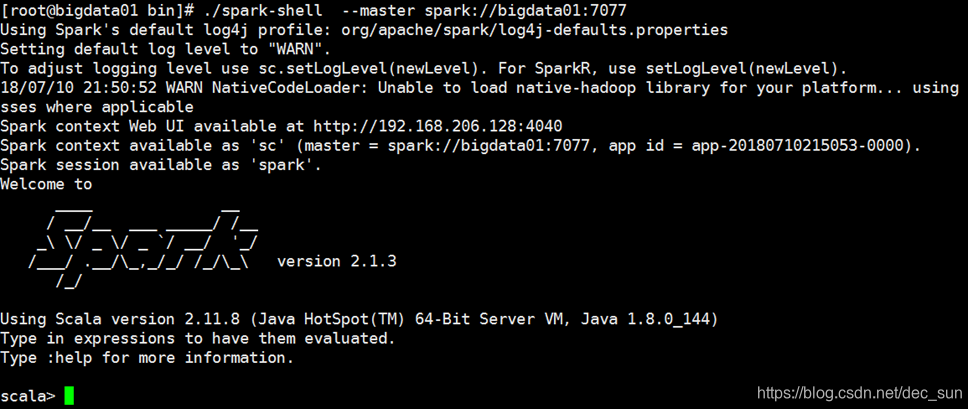
运行Spark交互式控制台—spark-shell:运行/opt/spark213/bin目录中的./spark-shell --master spark://bigdata01:7077命令:

















 1542
1542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









