




 Spark Shell是用于学习和测试Spark程序的交互式命令行工具,它可以在local模式下模拟spark集群运行。在集群上启动Spark Shell需要指定master地址,如`spark://hdp02:7077,hdp01:7077`,并配置executor内存和核心数。在集群环境中,不指定调度资源可能导致问题。通过启动Hadoop集群,将文件上传到HDFS,可以进行如wordcount等操作。"
122821750,8756923,YBTOJ进阶挑战:递推解f函数,"['递推算法', '动态规划', '编程挑战', 'c++编程', '算法题解']
Spark Shell是用于学习和测试Spark程序的交互式命令行工具,它可以在local模式下模拟spark集群运行。在集群上启动Spark Shell需要指定master地址,如`spark://hdp02:7077,hdp01:7077`,并配置executor内存和核心数。在集群环境中,不指定调度资源可能导致问题。通过启动Hadoop集群,将文件上传到HDFS,可以进行如wordcount等操作。"
122821750,8756923,YBTOJ进阶挑战:递推解f函数,"['递推算法', '动态规划', '编程挑战', 'c++编程', '算法题解']
定于:Spark Shell(是一个交互式的命令行,里面可以写spark程序,方便学习和测试,他也是一个客户端,用于提交spark应用程序)
启动(本地单机版-非集群):
./bin/spark-shell
上面的方式没有指定master的地址,即用的是spark的local模式运行的(模拟的spark集群用心的过程)
./bin/spark-shell --master spark://hdp02:7077,hdp01:7077 –executor-memory 512mb --total-executor-cores 5
第二个指定了master 在集群上运行
这里需要注意,集群上运行spark shell 也必须指定调度资源,不然可能会出现下图,cup0的情况

启动hadoop集群:star-dfs.sh
vi一个work.txt,放到hds上,等会做workcount的基础数据
vi work.txt
hello guowei
hello yjz
hello rzp
hello zxb
hello word
#把work.txt放到hdfs上,创建一个文件夹,把他移动到文件夹下
hadoop fs -put /home/hdp01/work.txt /
hadoop fs -mkdir /sparktest
hadoop fs -mv /work.txt /sparktest
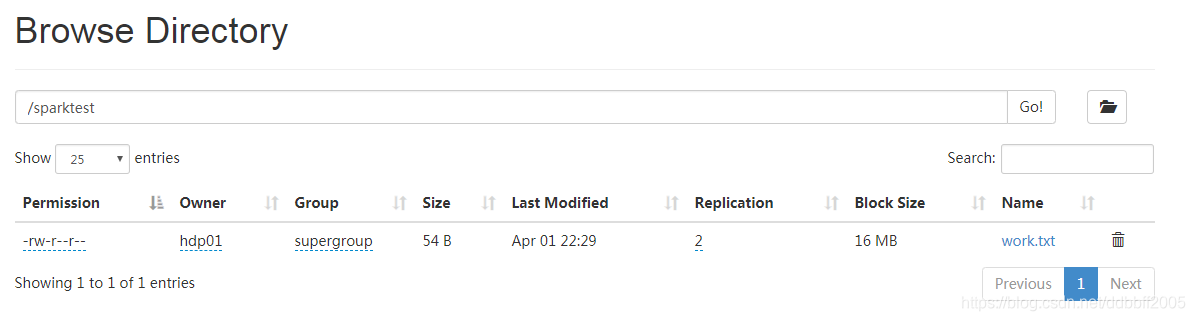
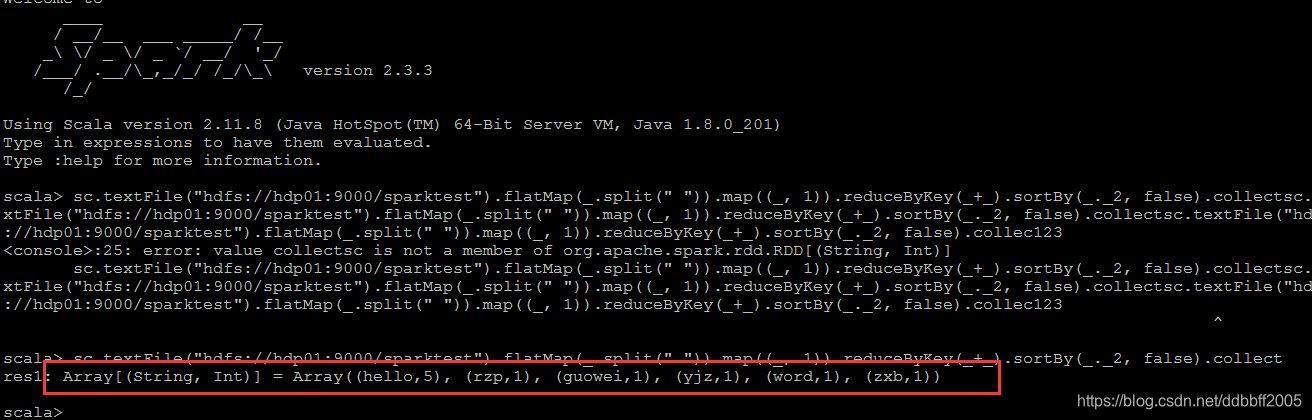
执行wordcount,计算
sc.textFile("hdfs://hdp01:9000/sparktest").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).sortBy(_._2, false).collect

















 543
543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









