







 本文深入解析特征工程核心步骤,涵盖数据预处理、特征选择、降维等关键环节,通过实例介绍标准化、区间缩放、多项式转换等技术,助力提升模型性能。
本文深入解析特征工程核心步骤,涵盖数据预处理、特征选择、降维等关键环节,通过实例介绍标准化、区间缩放、多项式转换等技术,助力提升模型性能。
资料来自http://www.cnblogs.com/jasonfreak/p/5448385.html
目录
1 特征工程是什么?
2 数据预处理
2.1 无量纲化
2.1.1 标准化
2.1.2 区间缩放法
2.1.3 标准化与归一化的区别
2.2 对定量特征二值化
2.3 对定性特征哑编码
2.4 缺失值计算
2.5 数据变换
2.6 回顾
3 特征选择
3.1 Filter
3.1.1 方差选择法
3.1.2 相关系数法
3.1.3 卡方检验
3.1.4 互信息法
3.2 Wrapper
3.2.1 递归特征消除法
3.3 Embedded
3.3.1 基于惩罚项的特征选择法
3.3.2 基于树模型的特征选择法
3.4 回顾
4 降维
4.1 主成分分析法(PCA)
4.2 线性判别分析法(LDA)
4.3 回顾
5 总结
6 参考资料
---------------------------
PolynomialFeatures可以用于扩充数据特征。
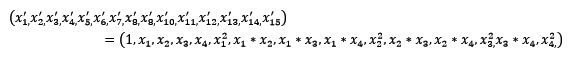
使用preproccessing库的PolynomialFeatures类对数据进行多项式转换的代码如下:
| 类 | 功能 | 说明 |
| StandardScaler | 无量纲化 | 标准化,基于特征矩阵的列,将特征值转换至服从标准正态分布 |
| MinMaxScaler | 无量纲化 | 区间缩放,基于最大最小值,将特征值转换到[0, 1]区间上 |
| Normalizer | 归一化 | 基于特征矩阵的行,将样本向量转换为“单位向量” |
| Binarizer | 二值化 | 基于给定阈值,将定量特征按阈值划分 |
| OneHotEncoder | 哑编码 | 将定性数据编码为定量数据 |
| Imputer | 缺失值计算 | 计算缺失值,缺失值可填充为均值等 |
| PolynomialFeatures | 多项式数据转换 | 多项式数据转换 |
| FunctionTransformer | 自定义单元数据转换 | 使用单变元的函数来转换数据 |

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









