 Python列表技巧
Python列表技巧





 本文深入浅出地介绍了Python中列表的索引、切片及遍历等核心操作技巧,通过实例帮助读者快速掌握列表的基本用法。
本文深入浅出地介绍了Python中列表的索引、切片及遍历等核心操作技巧,通过实例帮助读者快速掌握列表的基本用法。
5分钟带你了解Python中的容器型数据类型–列表2
这里,我们主要介绍的是列表的遍历、列表的索引和切片、列表的经典例题,想要了解更基础的知识,请前往《5分钟带你了解Python中的容器型数据类型–列表1》,废话不多说,直接进入正题
1.列表的索引和切片
这部分内容很简单,不管你是不是搞计算机的,但是既然你点到了这里,相信,你或多或少听说过索引这个词儿,如果还真没听说过,那你听过检索这个吧,现实生活中,检索的目的是查找并取出满足要求的东西,那么,其实索引和检索的过程是很像的,也就是去查找并将需要的东西取出来,而这里在列表中检索便叫做索引(我是这样理解的),那么既然索引就是这样简单的操作,想想是不是就觉得它会简单了。
- 列表的索引
对一个列表做索引操作,语法是
列表名[元素下标]
例如:
fruits = ['香蕉', '西瓜', '梨子', '火龙果', '苹果', '蓝莓']
print(fruits[1]) # 取出列表中的'西瓜'
执行结果如下
西瓜
在《5分钟带你了解Python中的容器型数据类型–列表1》也讲过,列表中的元素是有下标的,如下这样
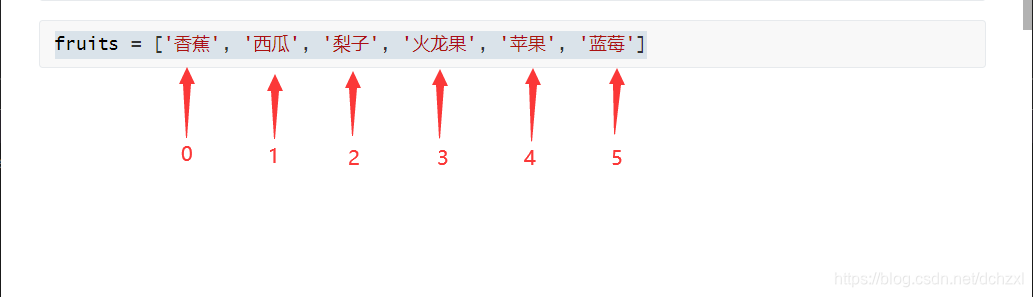
那么,同理,我们想取fruits中的其他元素,更改一下下标就可以,这里不再举例
值得注意的是,不但可以对列表进行正向索引,还可以对它进行逆向索引,也就是说,列表中的元素不但在正向上有下标(从前到后的顺序,从0开始编号),在逆方向上仍然是有下标的,用刚刚的fruits列表举例,它的下标是这样的
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NMAGyx9f-1627315365972)(C:\Users\86158\AppData\Roaming\Typora\typora-user-images\image-20210726223942680.png)]](https://i-blog.csdnimg.cn/blog_migrate/b96273f02fd5da03255e4b1abc083613.png)
于是,如果我们这样取
fruits = ['香蕉', '西瓜', '梨子', '火龙果', '苹果', '蓝莓']
print(fruits[-5]) # 取出列表中的'西瓜'
同样可以得到列表里面的’西瓜’
索引只是在列表中找出相应的元素,而不会对列表本身作任何修改,但是在对索引的元素值进行修改时,列表中的对应元素值也被修改
如:
fruits = ['香蕉', '西瓜', '梨子', '火龙果', '苹果', '蓝莓']
print(fruits[-5]) # 取出列表中的'西瓜'
print(fruits)
输出:
['香蕉', '西瓜', '梨子', '火龙果', '苹果', '蓝莓'] # 原并没有改变列表
而如果
fruits = ['香蕉', '西瓜', '梨子', '火龙果', '苹果', '蓝莓','杨梅'] # 定义一个列表\
fruits[0] = '西瓜' # 将第一个元素改成'西瓜'
print(fruits)
输出:
['西瓜', '西瓜', '梨子', '火龙果', '苹果', '蓝莓', '杨梅'] # 第一个元素已经更改成“西瓜"
掌握了列表的索引,那下面我们再看看什么是列表的切片呢?
- 列表的切片
从字面上来看,对一个东西切片,那就是将这个物品切成一片儿一片儿的,那么,其实列表的切片和这个意思也是很像的。在一个列表中,根据列表的下标将元素“切”下来列表的一部分生成另一个列表,那么,这个过程就叫做对列表的切片。这里的“切”只是一个形象的说法,而它不像是真的在列表上切,而只是像索引那样,查找到相应的元素,不同的是,切片出来的元素会是一个新的列表,而列表本身不会被修改,而索引出来的元素是一个某种数据类型的单个数据
对一个列表做切片操作,语法是
列表名[开始下标:结束下标:步长] # 步长在之前讲for循环时range()函数的使用已经讲过
# 取不到结束下标对应的元素,只能取到它的上一个
例如:
fruits = ['香蕉', '西瓜', '梨子', '火龙果', '苹果', '蓝莓'] # 定义一个列表
fruits1 = fruits[1:4:1] # 切片得到的列表复制给一个新列表fruits1,
#步长为1,可以省略即fruits1 = fruits[1:4]
print(f"fruits1 = {fruits1}")
print(f"fruits = {fruits}")
输出结果
fruits1 = ['西瓜', '梨子', '火龙果']
fruits = ['香蕉', '西瓜', '梨子', '火龙果', '苹果', '蓝莓']
可以知道原本的列表是没有被修改的
如果我们想从第一个元素到最后一个元素进行切片,并且想“跳着”取,就是想取到一个、隔一个再取一个,那么可以这样做:
fruits = ['香蕉', '西瓜', '梨子', '火龙果', '苹果', '蓝莓','杨梅'] # 定义一个列表
fruits1 = fruits[::2] # 从第一个开始可以省略,到最后一个结束也可以省略
print(fruits1)
输出结果
['香蕉', '梨子', '苹果', '杨梅']
由于是从第一个开始到最后一个(在整个列表中查找,所以可以取到最后一个元素)
在上面,我们知道列表有正向索引,还有逆向索引,那么,切片是不是也有逆向切片呢?没错,是的,同样我们可以采用逆向索引,例如
fruits = ['香蕉', '西瓜', '梨子', '火龙果', '苹果', '蓝莓','杨梅'] # 定义一个列表
fruits1 = fruits[-1::-1] # 从最后一个开始反向查找全部,步长为-1
print(fruits1)
输出结果
['杨梅', '蓝莓', '苹果', '火龙果', '梨子', '西瓜', '香蕉'] # 得到一个反向的列表
其他相关操作自己赶紧试试,比如看看下列操作能得到是什么样的结果
fruits = ['香蕉', '西瓜', '梨子', '火龙果', '苹果', '蓝莓','杨梅'] # 定义一个列表
fruits1 = fruits[-2:-6:-2]
print(fruits1)
#或者
print(fruits[-1::-3] )
不但可以正向下标和反向下标切片,还可以用正向和反向下标混合进行切片(但只能向一个方向进行切片),如:
fruits = ['香蕉', '西瓜', '梨子', '火龙果', '苹果', '蓝莓','杨梅'] # 定义一个列表
print(fruits[-5:5])
输出结果
['梨子', '火龙果', '苹果']
赶紧自己试试其它的
2.列表的遍历
对于一个列表,如果我们想看一下它里面的所有元素有哪些,那么这个将所有元素输出来的过程就叫列表的遍历。常用用for循环的遍历方法共三种:
例1
nums = [1, 4, 3, 6, 5, 2, 7]
for i in range(len(nums)): # 可读可写操作
print(nums[i], end=' ')
输出结果
1 4 3 6 5 2 7
例2
for num in nums: # 只读操作,不能加序号,实在要加,加上enumerate(枚举)函数,如例3
print(num, end=' ')
输出结果
1 4 3 6 5 2 7
例3
for num in enumerate(nums): # 加上enumerate(枚举)函数可得到索引和值
print(num)
输出结果
(0, 1) (1, 4) (2, 3) (3, 6) (4, 5) (5, 2) (6, 7)
如果对你有帮助,不要帮助点赞、评论、关注加收藏哦!
例3
```python
for num in enumerate(nums): # 加上enumerate(枚举)函数可得到索引和值
print(num)
输出结果
(0, 1) (1, 4) (2, 3) (3, 6) (4, 5) (5, 2) (6, 7)
如果对你有帮助,不要帮助点赞、评论、关注加收藏哦!


















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











