



不可以不掌握的湖仓一体paimon
paimon 特性
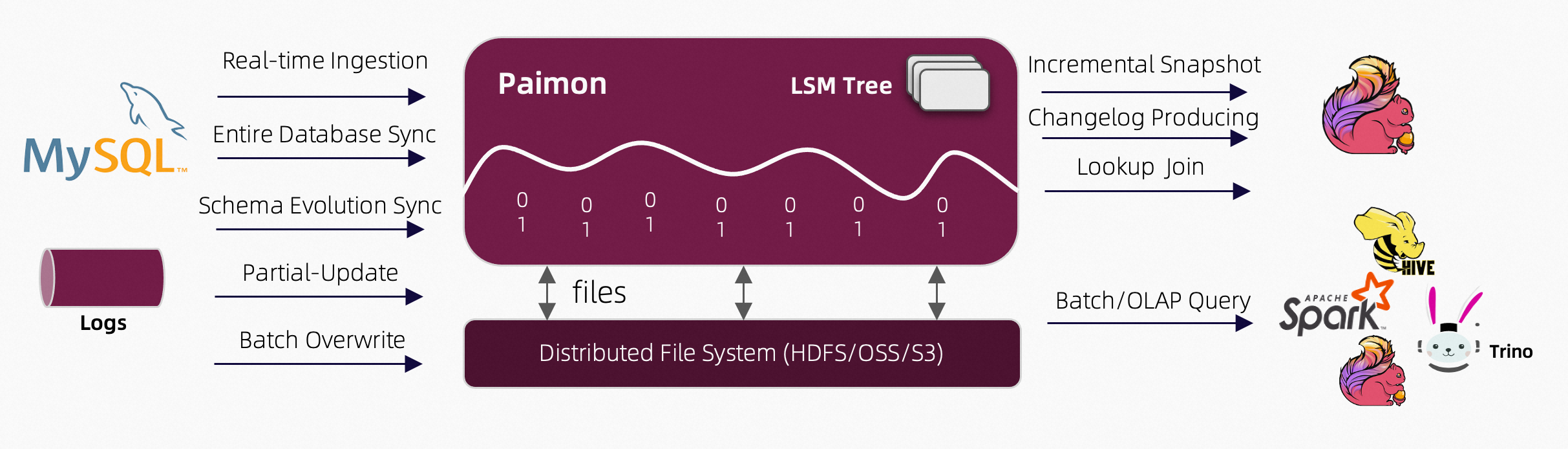
核心特性
- 统一批处理和流处理
批量写入和读取、流式更新、变更日志生成,全部支持。 - 数据湖能力
低成本、高可靠性、可扩展的元数据。 Apache Paimon 具有作为数据湖存储的所有优势。 - 各种合并引擎
按照您喜欢的方式更新记录。保留最后一条记录、进行部分更新或将记录聚合在一起,由您决定。 - 变更日志生成
Apache Paimon 可以从任何数据源生成正确且完整的变更日志,从而简化您的流分析。 - 丰富的表类型
除了主键表之外,Apache Paimon还支持append-only表,提供有序的流式读取来替代消息队列。 - 模式演化
Apache Paimon 支持完整的模式演化。您可以重命名列并重新排序。
Paimon的CATALOG
Paimon catalog 用于管理paimon表的元数据信息,目前支持四种类型的元存储:
- Filesystem Metastore (默认),它将元数据和表文件存储在文件系统中。
- hive metastore,它还将元数据存储在 Hive metastore 中。用户可以直接从 Hive 访问这些表。
- jdbc 元存储,它还将元数据存储在关系数据库(如 MySQL、Postgres 等)中。
- REST MetaStore,旨在提供一种轻量级的方式来从单个客户端访问任何目录后端。
-- Flink SQL
-- FS(HDFS)catalog
-- 上传 $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-core-(hadoop版本).jar 到$FLINK_HOME/lib
CREATE CATALOG fs_catalog WITH (
'type' = 'paimon',
'warehouse' = 'hdfs:///user/paimon/fs/'
);
-- HIVE catalog
-- 1. 上传flink-sql-connector-hive-(hive版本)-(flink版本).jar上传到到$FLINK_HOME/lib
-- 2. 启动nohup hive --service metastore &
CREATE CATALOG hive_catalog WITH (
'type' = 'paimon',
'metastore' = 'hive',
'uri' = 'thrift://hive-metastore:9083',
'hive-conf-dir' = '/opt/module/hive/conf',
'warehouse' = 'hdfs:///user/paimon/hive/'
);
-- MySQL catalog
-- flink-connector-jdbc_(flink版本).jar mysql-connector-j-(版本号).jar
CREATE CATALOG mysql_jdbc_catalog WITH (
'type' = 'paimon',
'metastore' = 'jdbc',
'uri' = 'jdbc:mysql://<host>:<port>/<databaseName>',
'jdbc.user' = 'bigdata',
'jdbc.password' = '123456',
'catalog-key'='jdbc',
'warehouse' = 'hdfs:///user/paimon/fs'
);
-- REST Catalog
-- 略,需要调用paimon java API,非flinksql
-- 使用指定CATALOG
USE CATALOG hive_catalog;
-- 查看所有CATALOG
SHOW CATALOGl;
-- 查询当前CATALOG
SHOW CURRENT CATALOG;
补充:paimon 默认使用default_catalog,基于会话内存,因此每次重开会话或会话过期,导致元数据未持久化丢失,因此需要用到持久化CATALOG。
在企业中flink-sql在启动时支持配置文件 -i 文件名
FLINK_HOME/conf下创建sql-client-init.sql文件。
-- 设置执行环境
SET 'execution.runtime-mode' = 'streaming';
SET 'parallelism.default' = 4;
SET 'state.checkpoints.dir' = 'hdfs:///flink/checkpoints';
SET 'state.backend' = 'rocksdb';
-- FS catalog
CREATE CATALOG fs_catalog WITH (
'type' = 'paimon',
'warehouse' = 'hdfs:///user/paimon/fs/'
);
-- HIVE catalog
CREATE CATALOG hive_catalog WITH (
'type' = 'paimon',
'metastore' = 'hive',
'uri' = 'thrift://hive-metastore:9083',
'hive-conf-dir' = '/opt/module/hive/conf',
'warehouse' = 'hdfs:///user/paimon/hive/'
);
-- 创建默认数据库 tmp,防止影响正常库表
USE CATALOG hive_catalog;
CREATE DATABASE IF NOT EXISTS tmp;
USE tmp;
flink sql-client.sh简化命令提交
bin/bash
# 参数检查
if [ $# -lt 1 ]; then
echo "Usage: $0 [yarn-session|prejob] [sql_file]"
exit 1
fi
MODE=$1
SQL_FILE=${2:-""}
INIT_FILE="$(dirname "$0")/../conf/sql-client-init.sql"
# YARN Session模式
function start_yarn_session() {
echo "Starting Flink SQL Client with YARN Session..."
"$(dirname "$0")/sql-client.sh" \
-s yarn-session \
-i "$INIT_FILE" \
${SQL_FILE:+-f "$SQL_FILE"}
}
# Pre-job模式
function start_prejob() {
if [ -z "$SQL_FILE" ]; then
echo "SQL file required in pre-job mode"
exit 1
fi
echo "Submitting Flink SQL Job..."
"$(dirname "$0")/sql-client.sh" \
-u yarn-per-job \
-i "$INIT_FILE" \
-f "$SQL_FILE"
}
# 模式选择
case "$MODE" in
yarn-session) start_yarn_session ;;
prejob) start_prejob ;;
*) echo "Invalid mode: $MODE" ;;
esac
paimon DDL语句
创建管理表
在 Paimon Catalog中创建的表就是Paimon的管理表,由Catalog管理。当表从Catalog中删除时,其表文件也将被删除,类似于Hive的内部表。
普通方式
-- 创建表
CREATE TABLE test (
user_id BIGINT,
name STRING,
dt STRING,
hh STRING,
PRIMARY KEY (dt, hh, user_id) NOT ENFORCED
);
-- 创建分区表 paimon表默认format orc压缩
CREATE TABLE test_p (
user_id BIGINT,
name STRING,
dt STRING,
hh STRING,
PRIMARY KEY (dt, hh, user_id) NOT ENFORCED
) PARTITIONED BY (dt, hh ,user_id)
WITH ('file.format' = 'orc');
-- 创建分区分桶表 默认根据bucket-key hash取mol
CREATE TABLE test_pb (
user_id BIGINT,
name STRING,
dt STRING,
hh STRING,
PRIMARY KEY (dt, hh, user_id) NOT ENFORCED
) PARTITIONED BY (dt, hh ,user_id)
WITH (
'bucket' = '2',
'bucket-key' = 'user_id'
);
CREATE TABLE tab_name AS SELECT (CTAS)方式建表
CREATE TABLE test2 AS SELECT * FROM test;
-- 指定分区
CREATE TABLE test2_p WITH ('partition' = 'dt') AS SELECT * FROM test_p;
-- 指定配置
CREATE TABLE test3 WITH ('file.format' = 'parquet') AS SELECT * FROM test_p;
-- 指定主键
CREATE TABLE test_4 WITH ('primary-key' = 'dt,hh') AS SELECT * FROM test;
-- 指定主键和分区
CREATE TABLE test_5 WITH ('primary-key' = 'dt,hh', 'partition' = 'dt') AS SELECT * FROM test_p;
CREATE TABLE tab_name LIKE (CTL)方式建表
-- 创建与另一个表具有相同schema、分区和表属性的表。
CREATE TABLE test_ctl LIKE test;

















 1016
1016

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









