




 本文探讨了Azure Databricks作为Azure Data Platform的一部分,它与Azure Data Factory(ADF)的区别。Databricks是基于Spark的云服务,专注于数据处理和机器学习,而ADF更侧重于数据集成。在选择使用时,ADF适合数据集成和定时任务,而Databricks适合需要实时处理和高级功能的场景。
本文探讨了Azure Databricks作为Azure Data Platform的一部分,它与Azure Data Factory(ADF)的区别。Databricks是基于Spark的云服务,专注于数据处理和机器学习,而ADF更侧重于数据集成。在选择使用时,ADF适合数据集成和定时任务,而Databricks适合需要实时处理和高级功能的场景。
本文属于【Azure Data Platform】系列。
接上文:【Azure Data Platform】ETL工具(18)——ADF 迭代和条件活动(2)
这次来聊聊Azure Databricks
前言
之所以突然停下ADF的介绍转而向Azure Databricks, 是因为最近公司的项目已经呈现出ADF与Databricks的组合趋势。为了更好地运维公司的项目,有必要了解一下Databricks。并且大概介绍一下Azure Data Factory和Azure Databricks的关系。
什么是Databricks
今时今日,大数据已经不是新鲜事,也已经被大范围地使用。大数据中有一个开源引擎Spark用来支持大规模数据分析。主要通过集群,并行地进行数据处理,从而提高数据处理性能。
Databricks简单来说,就是Azure上的Spark。 它可以很容易地与Blob storage, ADLS, SQL DB, PowerBI 等工具集成
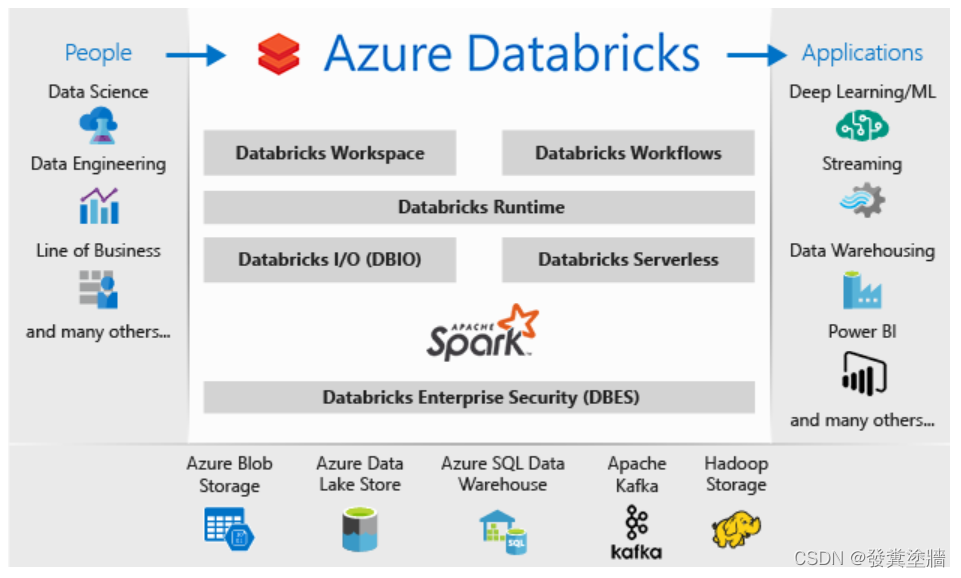
- Databricks Workspace:一个交互式的工作区,用户(主要是数据的消费者)可以通过这个工作区进行合作。
- Databricks Runtime : 用于支持运行,提高性能。
- Databricks File System (DBFS):类似于DataBricks的存储,但是对用户来说是一个抽象层。
它与ADF的区别
ADF主要用于从多个大规模的数据源中进行数据
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2005
2005

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









