




 本文详细介绍了如何在Azure Data Factory (ADF) 中使用数据流进行数据转换。从创建源(如Blob Storage)到配置数据流,包括派生列和SQL DB目标,以及调试和实际运行数据流的步骤。ADF数据流提供了一种无需编码的可视化工具,底层利用Databricks集群,使得数据处理更高效和友好。通过实例展示了如何将txt文件拆分为两列并存储到SQL DB中。
本文详细介绍了如何在Azure Data Factory (ADF) 中使用数据流进行数据转换。从创建源(如Blob Storage)到配置数据流,包括派生列和SQL DB目标,以及调试和实际运行数据流的步骤。ADF数据流提供了一种无需编码的可视化工具,底层利用Databricks集群,使得数据处理更高效和友好。通过实例展示了如何将txt文件拆分为两列并存储到SQL DB中。
本文属于【Azure Data Platform】系列。
接上文:【【Azure Data Platform】ETL工具(10)——ADF 集成运行时(Integration Runtimes,IR)
本文介绍ADF 的数据流
前言
跟【Azure Data Platform】ETL工具(5)——使用Azure Data Factory数据流转换数据不同,前面说的是快速搭建一个Data Flow并做一些简单的操作,本文尝试进行一些深入的介绍。
Azure 提供了一个叫Databricks的服务,是一个对数据进行统一和分析的平台。但是Databricks需要一定程度的编码。与之相比,ADF 的Data flow是一个code-free的可视化工具。同时底层使用着Databricks集群,这比直接使用Databricks更加友好和高效(在某些方面)。
可以把Dataflow作为一个常规的pipeline活动来运行。上一文介绍过的IR就可以用来运行这些Data flow。 可以使用默认的“AutoResolveIntegrationRuntime”,也可以自己创建一个新的IR。
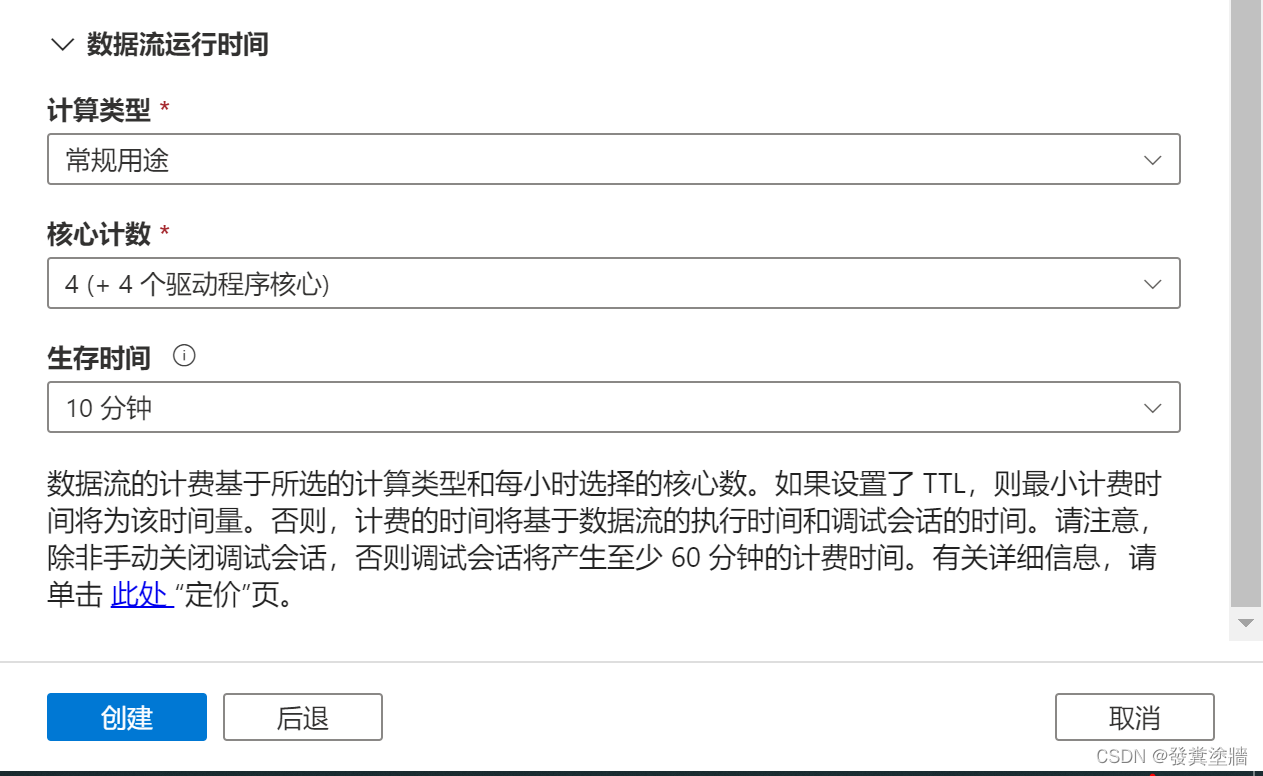
选择创建新的IR,一方面可以保障数据合规性,另外一方面可以自定义一些配置,比如集群大小(最小8个核心), 生存时间(用来指定data flow运行完毕只有,最长保留多久,时间越久费用越高)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2389
2389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









