




 本文介绍了语音识别中常用的神经网络技术,包括CNN和RNN模型,以及解码器的工作原理。解码器依赖于声学模型(如GMM-HMM)、词典和语言模型。声学模型利用HMM对时序信息建模,词典用于将识别的音素映射到词汇,而语言模型则用于评估句子概率。神经网络语言模型则通过直接建模避免了统计计数。
本文介绍了语音识别中常用的神经网络技术,包括CNN和RNN模型,以及解码器的工作原理。解码器依赖于声学模型(如GMM-HMM)、词典和语言模型。声学模型利用HMM对时序信息建模,词典用于将识别的音素映射到词汇,而语言模型则用于评估句子概率。神经网络语言模型则通过直接建模避免了统计计数。
一、神经网络

当前常用的语音识别框架如下图
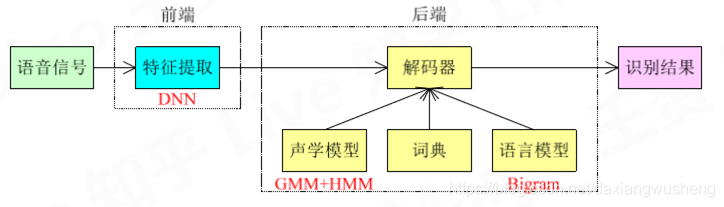
其背后的逻辑是
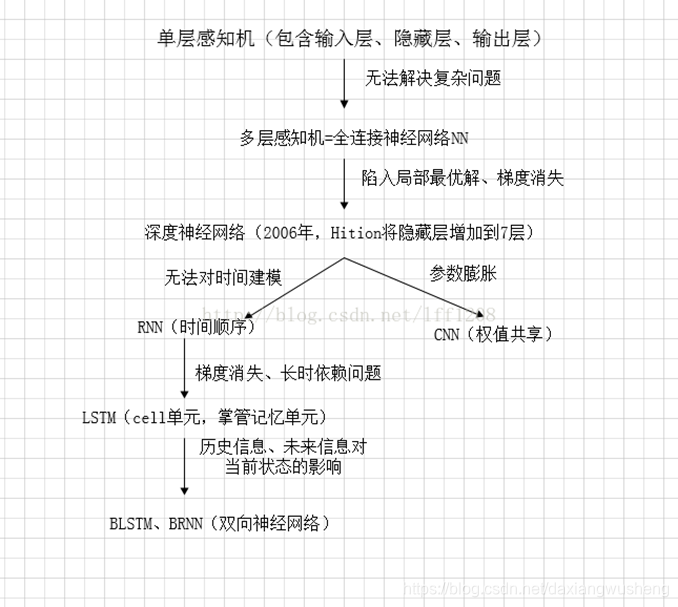
在特征提取时采用的神经网络里面的DNN技术
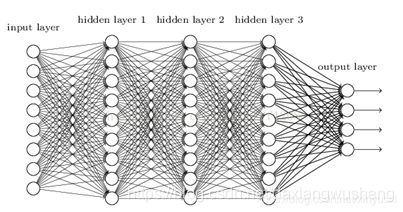
深度神经网络DNN
DNN技术可以分为两种,一种是CNN模型,一种是RNN模型
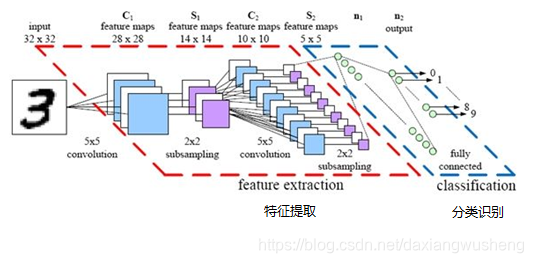 卷积神经网络 CNN模型
卷积神经网络 CNN模型
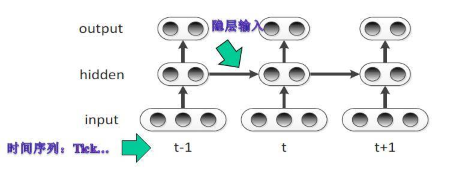
循环神经网络 RNN模型
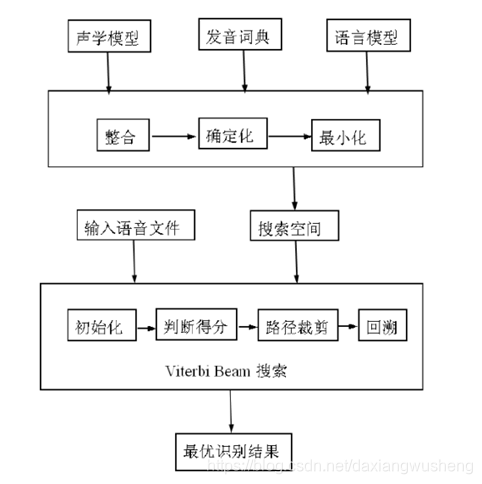
二、解码器
解码器信息来源于声学模型、词典、语言模型。框图如下:
2.1 声学模型
常用的声学模型为GMM-HMM,即混合高斯模型-隐马尔科夫模型
HMM模型对时序信息进行建模,在给定HMM的一个状态后,GMM对属于该状态的语音特征向量的概率分布进行建模。
2.2 词典
字典:就是发音字典,中文中就是拼音与汉字的对应,英文中就是音标与单词的对应
用途:
根据声学模型识别出来的音素,在字典中来找到对应的汉字(词)或者单词,用来在声学模型和语言模型建立桥梁,将两者联系起来。
比方如下词语的映射表:
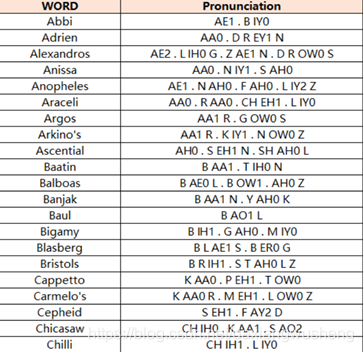
2.3 语言模型
语言模型是针对某种语言建立的概率模型,是用来计算一个句子的概率的概率模型。
划分以下两种:
2.3.1 N元统计语言模型:N-gram模型、平滑化
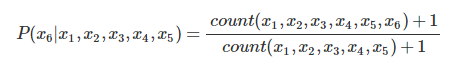
2.3.2 神经网络语言模型:
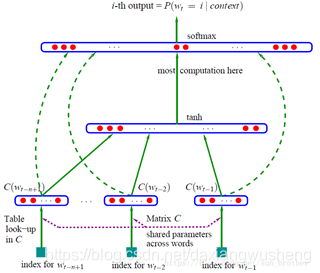
与统计语言模型不同的是,神经网络语言模型不通过计数的方法对nn元条件概率进行估计,而是直接通过一个神经网络对其建模求解。
用途:
1、决定哪一个词序列的可能性更大
2、已知若干个词,预测下一个词
例子:
1、I went to a party.
Eye went two a bar tea.
2、你现在在干什么?
你西安载感什么?




















 384
384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











