




 探讨Java对象序列化机制,包括序列化目标、作用及其实现方式。解释如何通过实现Serializable或Externalizable接口使对象可序列化,以及序列化和反序列化的过程。
探讨Java对象序列化机制,包括序列化目标、作用及其实现方式。解释如何通过实现Serializable或Externalizable接口使对象可序列化,以及序列化和反序列化的过程。
对象序列化机制和作用
对象序列化的目标是将对象保存到磁盘中,或允许在网络中直接传输对象,对象序列化机制允许把内存中的Java对象转换成平台无关的二进制流,从而允许吧这种二进制流持久的保存在磁盘上,通过网络将这种二进制流传输到另一个网络节点,其他程序一旦获得了这种二进制流,无论是从磁盘中获取还是从网络中获取,都可以将这种二进制流回复称原来的Java对象
- 序列化机制允许将实现序列化的Java对象转换成字节序列,这些字节序列可以保存在磁盘上,或通过网络传输,以备以后重新恢复成原来的对象,序列化机制使得对象可以脱离程序的运行而独立存在
- 对象的序列化(Serialize)是指将一个Java对象写入IO流中,与此对应的是,对象的反序列化(Deserialize)则指从IO流中恢复该Java对象
- Java9之后增强了对象序列化机制,它允许对读入的序列化数据进行过滤,这种过滤可在反序列化之前对数据执行校验,从而提高安全性和健壮性
- 如果要让某个对象支持序列化机制,则必须让它的类是可序列化的(serializable)的,要让这个类是可序列化的,该类必须实现如下两个接口之一
- Serializable
- Externalizable
- Java的很多类已经实现了Serializable,该接口是一个标记接口,实现该接口无需实现任何方法,它只是表明该类的实例是可序列化的
- 所有可能在网络上传输的对象的类都应该是可序列化的,否则程序将会出现异常,例如RMI(Remote Method Invoke,远程方法调用) 过程中的参数和返回值,所有需要保存到磁盘里的对象的类都必须可序列化,例如Web应用中需要保存到HttpSession或ServletContext属性的Java对象
- 序列化是RMI过程的参数和返回值都必须实现的机制,而所有分布式应用常常需要跨平台、跨网络,所以要求所有传递的参数、返回值必须实现序列化,通常情况下程序创建的每个JavaBean类都应该实现Serializable
使用对象流实现序列化
如果需要将某个对象保存到磁盘上或者通过网络传输,则这个类应该实现Serializable接口或者Externalizable接口,而使用Serializable来实现序列化非常简单,只要让目标泪实现Serializable接口即可,无需实现任何方法。
当一个类实现了Serializable接口后,其对象就是可序列化的,程序可以通过如下两个步骤来序列化该对象
- 创建一个ObjectOutputStream,这个输出流是一个处理流,所以必须建立在其他节点流的基础之上
// 创建个ObjectOutputStream输出流
ObjectOutputStream oos = ObjectOutputStream(new FileOutputStream("object.txt"));
- 调用ObjectOutputStream对象的writeObject()方法输出可序列化对象
//将一个Person对象输出到输出流中
oos.writeObject(per);
public class Person
implements java.io.Serializable
{
private String name;
private int age;
// 注意此处没有提供无参数的构造器!
public Person(String name, int age)
{
System.out.println("有参数的构造器");
this.name = name;
this.age = age;
}
// 省略name与age的setter和getter方法
// name的setter和getter方法
public void setName(String name)
{
this.name = name;
}
public String getName()
{
return this.name;
}
// age的setter和getter方法
public void setAge(int age)
{
this.age = age;
}
public int getAge()
{
return this.age;
}
}
定义了一个Person类,且实现了Serializable接口,于是Person类可序列化,然后使用ObjectOutputStream将一个Person对象写入磁盘文件
import java.io.*;
public class WriteObject
{
public static void main(String[] args)
{
try (
// 创建一个ObjectOutputStream输出流
var oos = new ObjectOutputStream(new FileOutputStream("object.txt")))
{
var per = new Person("孙悟空", 500);
// 将per对象写入输出流
oos.writeObject(per);
}
catch (IOException ex)
{
ex.printStackTrace();
}
}
}
如果要在二进制流中恢复Java对象,则需要使用反序列化,反序列化的实现分为两步:
- 创建一个ObjectInputStream输入流,这个输入流是一个处理流,所以必须建立在其他节点流的基础上
// 创建一个ObjectInputStream输入流
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("object.txt"));
- 调用ObjectInputStream对象的readObject()方法读取流中的对象,该方法返回一个Object类型的Java对象,如果程序知道该Java对象的类型,则可以将该对象强制类型转换成其真实的类型
// 从输入流中读取一个Java对象,并将其强制类型转换为Person类
Person p = (Person)ois.readObject();
import java.io.*;
public class ReadObject
{
public static void main(String[] args)
{
try (
// 创建一个ObjectInputStream输入流
var ois = new ObjectInputStream(new FileInputStream("object.txt")))
{
// 从输入流中读取一个Java对象,并将其强制类型转换为Person类
var p = (Person) ois.readObject();
System.out.println("名字为:" + p.getName()
+ "\n年龄为:" + p.getAge());
}
catch (Exception ex)
{
ex.printStackTrace();
}
}
}
反序列化读取的仅仅是Java对象的数据,而不是Java类,因此采用反序列化恢复Java对象时,必须提供该Java对象所属类的class文件,否则将会抛ClassNotFoundException异常
- 如果使用序列化机制向文件中写入了多个Java对象,使用反序列化机制恢复对象时必须按实际写入的顺序读取
- 当一个可序列化类有多个父类时(包括直接父类和间接父类),这些父类要么有无参数的构造器,要么也是可序列化的,否则反序列化时将抛出InvalidClassException,并且如果父类是不可序列化的,只是带有无参数的构造器,则该父类中定义的成员变量值不会序列化到二进制流中
对象引用的序列化
前面的Person类的两个成员变量分别是String类型和int类型,如果某个类的成员变量的类型不是基本类型或者String类型,而是另一个引用类型,那么这个引用类型必须是可序列化的,否则拥有该类型成员变量的类也不不可序列化的
如下代码所示,Teacher类持有一个Person类的引用,只有Person类是可序列化的,Teacher类才是可序列化的,如果Person类不可序列化,则无论Teacher类是否实现Serilizable、Externalizable接口,Teacher类都是不可序列化的
public class Teacher
implements java.io.Serializable
{
private String name;
private Person student;
public Teacher(String name, Person student)
{
this.name = name;
this.student = student;
}
// 此处省略了name和student的setter和getter方法
// name的setter和getter方法
public void setName(String name)
{
this.name = name;
}
public String getName()
{
return this.name;
}
// student的setter和getter方法
public void setStudent(Person student)
{
this.student = student;
}
public Person getStudent()
{
return this.student;
}
}
Person per = new Person("孙子", 500);
Teacher t1 = new Teacher("孙贼", per);
Teacher t2 = new Teacher("孙砸", per);
创建了两个Teacher对象和一个Person对象,这3个对象在内存中如图所示:
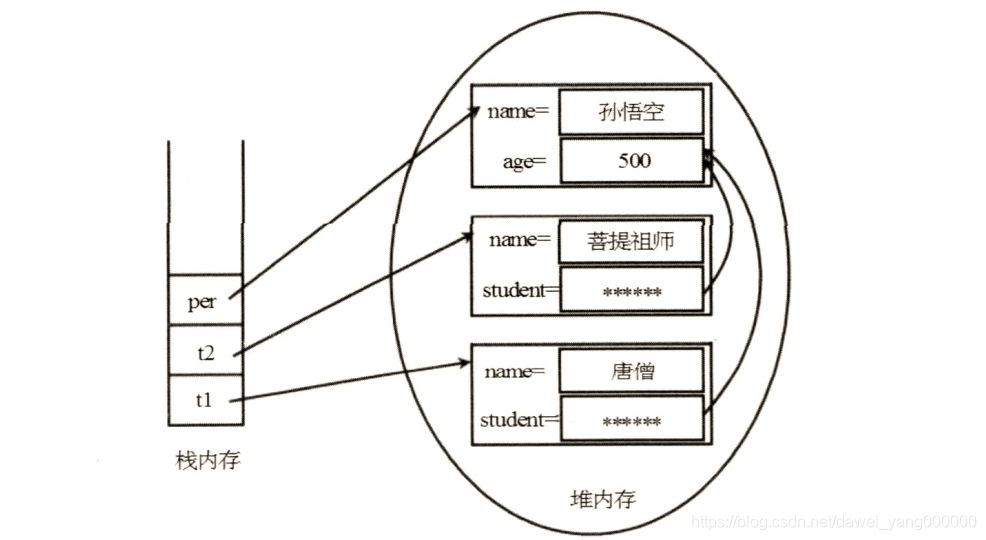
那么问题就来了:
- 如果先序列化t1对象,则系统将该t1对象所引用的Person对象一起序列化
- 如果先序列化t2对象,则系统将该t2对象所引用的Person对象一起序列化
- 如果先序列化per对象,则系统将再次序列化该Person对象
如果系统向输出流中写入了三个Person对象,那么当程序从输入流中反序列化这些对象时,将会得到3个Person对象,这显然违背了Java序列化机制的初衷
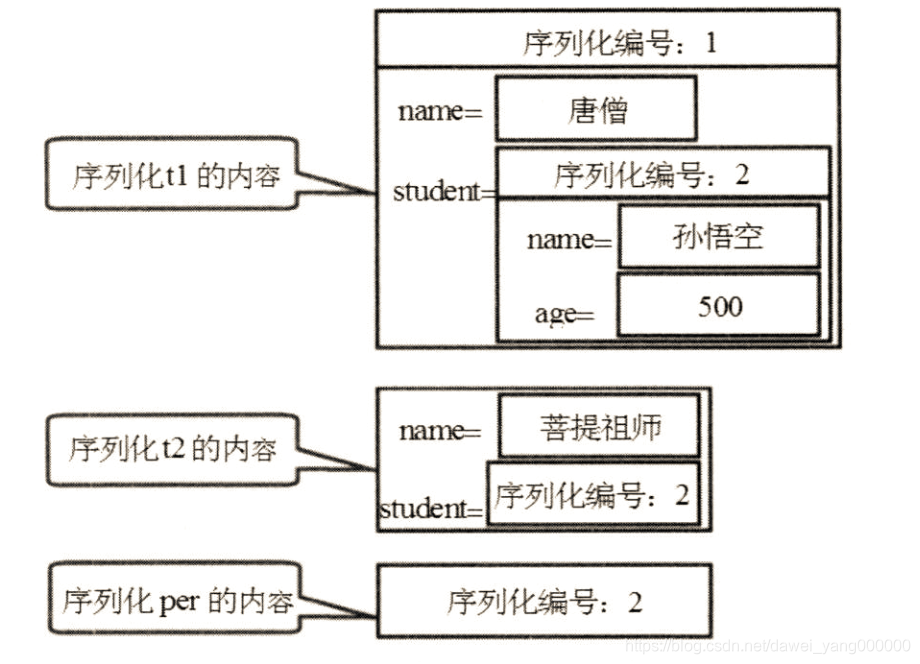
解决问题(Java序列化机制采用了一种特殊的序列化算法):
- 所有保存到磁盘中的对象都有一个序列化编号
- 当程序视图序列化一个对象时,程序将先检查该对象是否已经被序列化过,只有该对象从未(在当前JVM中)被序列化过,系统才会将该对象转换成字节序列并输出
- 如果某个对象已经序列化过,程序将只是直接输出一个序列化编号,而不是再次重新序列化该对象
假设用如下顺序的序列化代码:
oos.writeObject(t1);
oos.writeObject(t2);
oos.writeObject(per);
则序列化后磁盘文件的存储示意图如图所示
import java.io.*;
public class WriteTeacher
{
public static void main(String[] args)
{
try (
// 创建一个ObjectOutputStream输出流
var oos = new ObjectOutputStream(new FileOutputStream("teacher.txt")))
{
var per = new Person("孙悟空", 500);
var t1 = new Teacher("唐僧", per);
var t2 = new Teacher("菩提祖师", per);
// 依次将四个对象写入输出流
oos.writeObject(t1);
oos.writeObject(t2);
oos.writeObject(per);
oos.writeObject(t2);
}
catch (IOException ex)
{
ex.printStackTrace();
}
}
}
import java.io.*;
public class ReadTeacher
{
public static void main(String[] args)
{
try (
// 创建一个ObjectInputStream输出流
var ois = new ObjectInputStream(new FileInputStream("teacher.txt")))
{
// 依次读取ObjectInputStream输入流中的四个对象
var t1 = (Teacher) ois.readObject();
var t2 = (Teacher) ois.readObject();
var p = (Person) ois.readObject();
var t3 = (Teacher) ois.readObject();
// 输出true
System.out.println("t1的student引用和p是否相同:"
+ (t1.getStudent() == p));
// 输出true
System.out.println("t2的student引用和p是否相同:"
+ (t2.getStudent() == p));
// 输出true
System.out.println("t2和t3是否是同一个对象:"
+ (t2 == t3));
}
catch (Exception ex)
{
ex.printStackTrace();
}
}
}
那么问题又来了:只有第一次使用writeObject()方法输出时才会将该对象转换成字节序列,之后再调用只是返回序列化编号,那么如果这个对象是可变对象,当他在被序列化后发生了变化的情况下,就不会再次序列化输出
import java.io.*;
public class SerializeMutable
{
public static void main(String[] args)
{
try (
// 创建一个ObjectOutputStream输入流
var oos = new ObjectOutputStream(new FileOutputStream("mutable.txt"));
// 创建一个ObjectInputStream输入流
var ois = new ObjectInputStream(new FileInputStream("mutable.txt")))
{
var per = new Person("孙悟空", 500);
// 系统会per对象转换字节序列并输出
oos.writeObject(per);
// 改变per对象的name实例变量
per.setName("猪八戒");
// 系统只是输出序列化编号,所以改变后的name不会被序列化
oos.writeObject(per);
var p1 = (Person) ois.readObject(); // ①
var p2 = (Person) ois.readObject(); // ②
// 下面输出true,即反序列化后p1等于p2
System.out.println(p1 == p2);
// 下面依然看到输出"孙悟空",即改变后的实例变量没有被序列化
System.out.println(p2.getName());
}
catch (Exception ex)
{
ex.printStackTrace();
}
}
}



















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











