




 本文通过实战案例,介绍如何利用Python的sklearn库构建决策树模型,并对模型进行可视化展示。通过调整min_samples_leaf参数,观察决策树结构的变化及其对模型准确性的影响。
本文通过实战案例,介绍如何利用Python的sklearn库构建决策树模型,并对模型进行可视化展示。通过调整min_samples_leaf参数,观察决策树结构的变化及其对模型准确性的影响。
实验目标
- 基于iris_data.csv数据,建立决策树模型,评估模型表现
- 可视化决策树结构
- 修改min_samples_leaf参数,对比模型结果
数据集:百度云盘链接,提取码:fp8s
使用到的第三方库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn import tree
from sklearn.metrics import accuracy_score
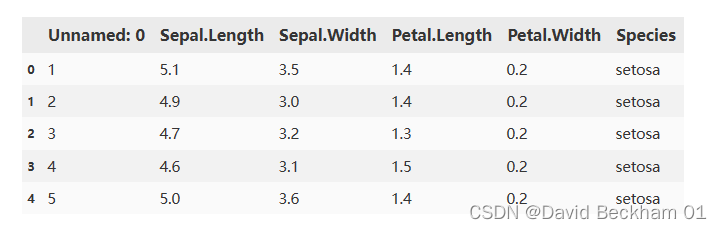
导入数据
# 导入数据
data = pd.read_csv("./dataset/iris_data.csv")
data.head()
使用 sklearn 自带的数据集
本次实验使用的数据集已经在 sklean 中包含了,可以直接使用,使用方法如下
# 导入数据集,scikit-learn 中已经包含了当前数据集
from sklearn.datasets import load_iris
iris = load_iris()
# pd.DataFrame(iris.data).head()
print(iris)
建立决策树模型
我们使用从本地导入数据的方式建立决策树模型,使用 sklearn 自带的数据集导入方式可以自行探索
# 建立决策树模型
dc_tree = tree.DecisionTreeClassifier(criterion='entropy', min_samples_leaf=5)
dc_tree.fit(x, y)
# 查看预测的准确性
accuracy = accuracy_score(y,dc_tree.predict(x))
print(f"模型预测的准确性为 >>> {accuracy}")

通过实验我们可以知道,决策树的预测准确性为:97.34%
参数解释:
- min_samples_leaf:叶子节点所需最少样本数,默认为1。如果达不到这个阈值,则同一父节点的所有叶子节点均被剪枝,
- criterion:选择使用什么算法作为结点分裂的依据。默认:gini。可选gini(基尼系数)或者entropy(信息增益)。
决策树模型 sklearn.tree.DecisionTreeClassifier 中还有很多默认参数,具体的可以参考官方文档
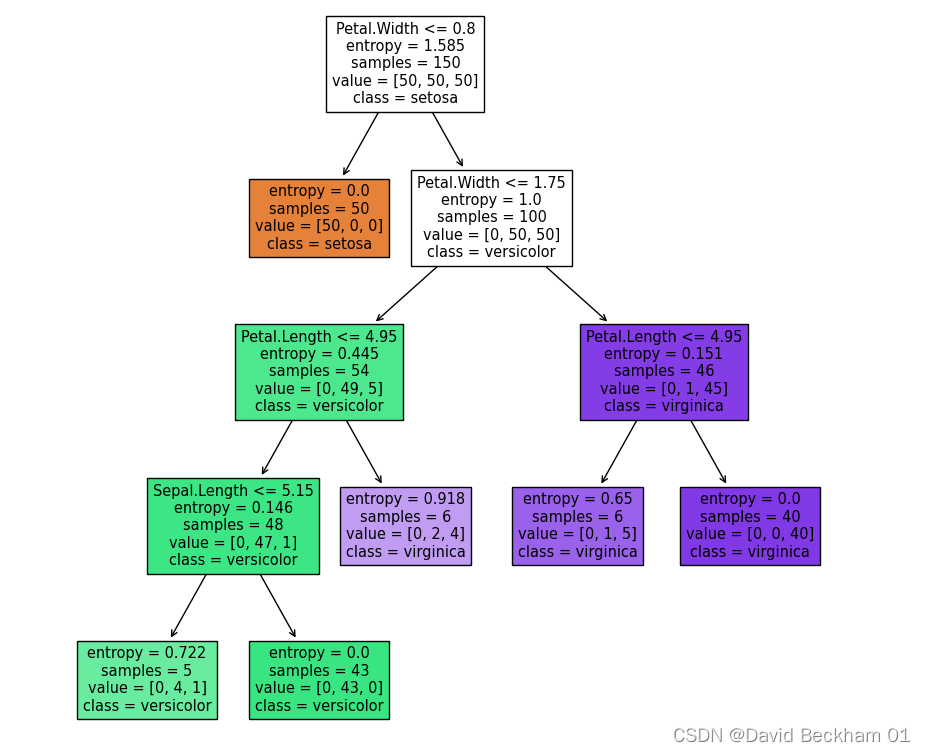
决策树可视化
# 可视化决策树
fig = plt.figure(figsize=(10,10))
tree.plot_tree(
dc_tree,
feature_names=['Sepal.Length', 'Sepal.Width', 'Petal.Length', 'Petal.Width'],
class_names=['setosa', 'versicolor', 'virginica'],
filled=True
)
sklearn.tree.plot_tree 具体的参数解释,参考官方文档
修改建立决策树模型参数后再次可视化决策树
# 建立决策树模型
dc_tree = tree.DecisionTreeClassifier(criterion='entropy', min_samples_leaf=1)
dc_tree.fit(x, y)
# 可视化决策树
fig = plt.figure(figsize=(15,15))
tree.plot_tree(
dc_tree,
feature_names=['Sepal.Length', 'Sepal.Width', 'Petal.Length', 'Petal.Width'],
class_names=['setosa', 'versicolor', 'virginica'],
filled=True
)
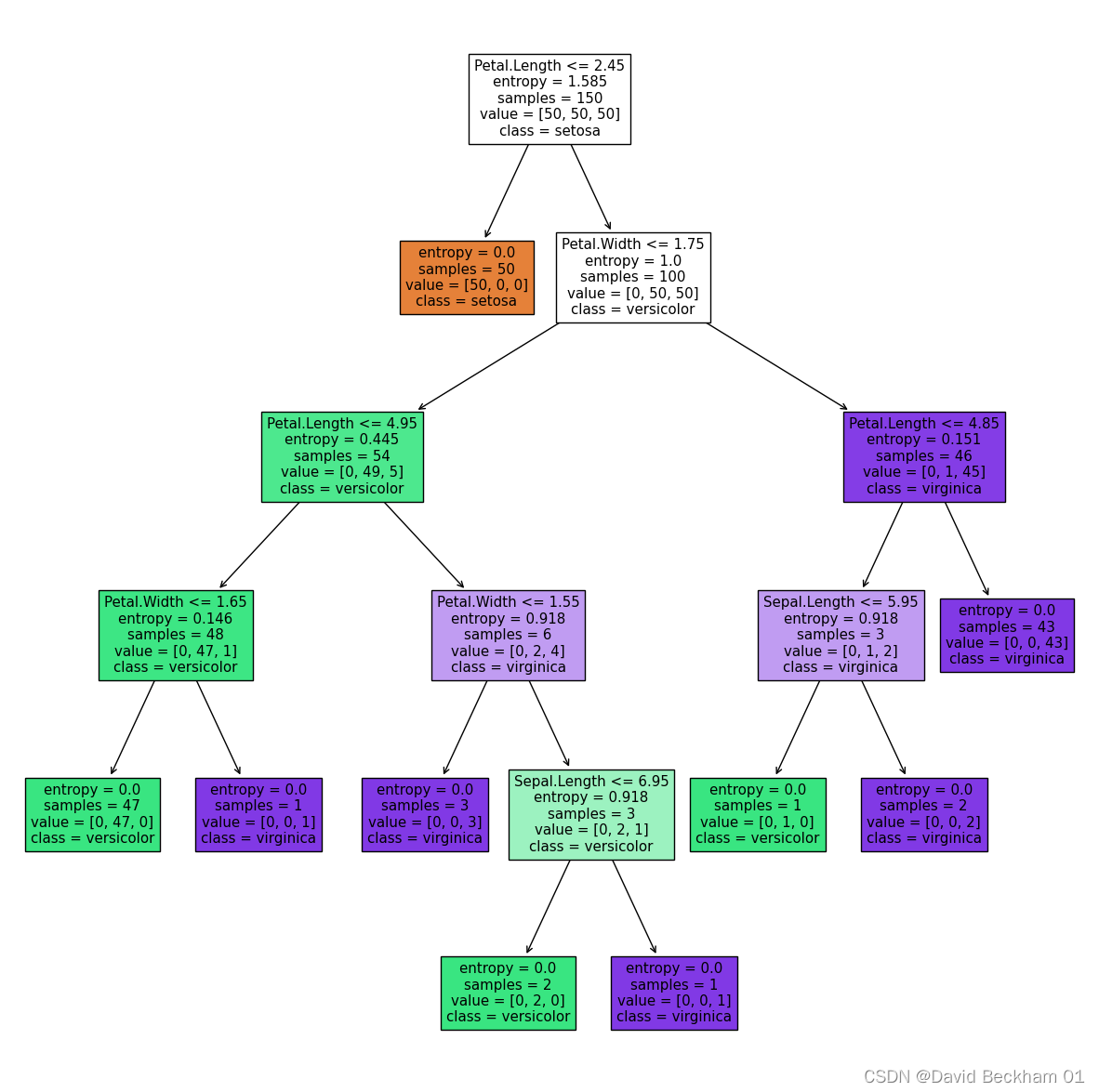
我们将决策树模型建立时叶子结点所需的最小样本数量改为1之后,(即:min_samples_leaf=1),决策树的深度相较之前加深了 1 ,结点数量也增加了。
通过实验我们可以知道,修改 min_samples_leaf 参数可以使模型的更加 "匹配" 训练集合,但是 min_samples_leaf 设置的过小,可能会导致过拟合的情况,从而使得模型的预测准确性下降。
总结
- 本次实验通过建立决策树,实现对标签数据的有效分类;
- 通过修改叶子节点最少样本数对应参数
min_samples_leaf,可调控制树的分支深度; - 决策树是一种比较简单的分类方法,具有容易理解、容易处理分类特征等优点,但是也存在容易出现过拟合的问题。
- 核心算法参考链接:sklearn.tree.DecisionTreeClassifier




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









