







 本文探讨了细粒度动作识别领域的挑战,特别是环境偏见问题,提出了利用多模态自监督和模态对抗训练的解决方案。通过引入一种新的数据集,文章强调了未来工作在音频模态上的潜在研究方向。
本文探讨了细粒度动作识别领域的挑战,特别是环境偏见问题,提出了利用多模态自监督和模态对抗训练的解决方案。通过引入一种新的数据集,文章强调了未来工作在音频模态上的潜在研究方向。

Abstract
Fine-grained action recognition datasets exhibit environmental bias, where multiple video sequences are captured from a limited number of environments. Multi-modal nature of video(视频的多模态性),提出的方法一个是multi-modal self-supervision,还有一个是adversarial training per modality
Introduction
fine-grained action recognition,

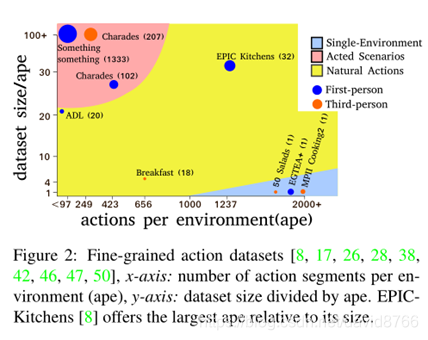
Few works have attempted deep UDA for video data《Temporal attentive alignment for large-scale video domain adaptation, ICCV2019》《Deep domain adaptation in action space, BMVC2018》
Conclusion
modality指的是两种信息(optical flow和RGB信息),future work包含audio
Key points: Motivation很好; 提出的新数据集


















 1766
1766

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









