




 本文详细介绍了如何部署分布式ELK日志分析系统,包括Filebeat的安装配置,Apache节点上的Logstash配置,以及系统的启动。重点讲解了Logstash的Filter插件,如grok的正则捕获,自定义表达式,数据修改插件mutate的使用,multiline插件的安装和应用,以及date时间处理插件的配置,帮助理解如何处理和分析日志数据。
本文详细介绍了如何部署分布式ELK日志分析系统,包括Filebeat的安装配置,Apache节点上的Logstash配置,以及系统的启动。重点讲解了Logstash的Filter插件,如grok的正则捕获,自定义表达式,数据修改插件mutate的使用,multiline插件的安装和应用,以及date时间处理插件的配置,帮助理解如何处理和分析日志数据。
一、Filebeat+ELK 部署
1. 环境部署
Node1节点(2C/4G) node1/192.168.145.15 Elasticsearch
Node2节点(2C/4G) node2/192.168.145.30 Elasticsearch
Apache节点 apache/192.168.145.45 Logstash Kibana Apache
Filebeat节点 filebeat/192.168.145.60 Filebeat
2. 在 Filebeat 节点上操作
2.1 安装 Filebeat
#上传软件包 filebeat-6.7.2-linux-x86_64.tar.gz 到/opt目录
tar zxvf filebeat-6.7.2-linux-x86_64.tar.gz
mv filebeat-6.7.2-linux-x86_64/ /usr/local/filebeat

2.2 设置 filebeat 的主配置文件
cd /usr/local/filebeat
cp filebeat.yml{
,.bak} #添加备份文件
vim filebeat.yml
filebeat.inputs:
- type: log #指定 log 类型,从日志文件中读取消息
enabled: true
paths:
- /var/log/messages #指定监控的日志文件
- /var/log/*.log
tags: ["sys"] #31行添加,设置索引标签
fields: #46行取消注释,可以使用 fields 配置选项设置一些参数字段添加到 output 中
service_name: filebeat
log_type: syslog
from: 192.168.145.60
--------------Elasticsearch output-------------------
(全部注释掉)
----------------Logstash output---------------------
output.logstash:
hosts: ["192.168.145.45:5044"] #指定 logstash 的 IP 和端口

3. 在 Apache 节点上操作
3.1 在 Logstash 组件所在节点上新建一个 Logstash 配置文件
cd /etc/logstash/conf.d
vim filebeat.conf
input {
beats {
port => "5044"
}
}
output {
elasticsearch {
hosts => ["192.168.145.15:9200","192.168.145.30:9200"]
index => "%{[fields][service_name]}-%{+YYYY.MM.dd}"
}
stdout {
codec => rubydebug
}
}

3. 启动
3.1 在Logstash 组件所在节点启动
#启动 filebeat
cd /usr/local/filebeat
nohup ./filebeat -e -c filebeat.yml > filebeat.out &
#-e:输出到标准输出,禁用syslog/文件输出
#-c:指定配置文件
#nohup:在系统后台不挂断地运行命令,退出终端不会影响程序的运行

3.2 在 Filebeat 节点 启动
#启动 logstash
logstash -f filebeat.conf

4. 浏览器访问
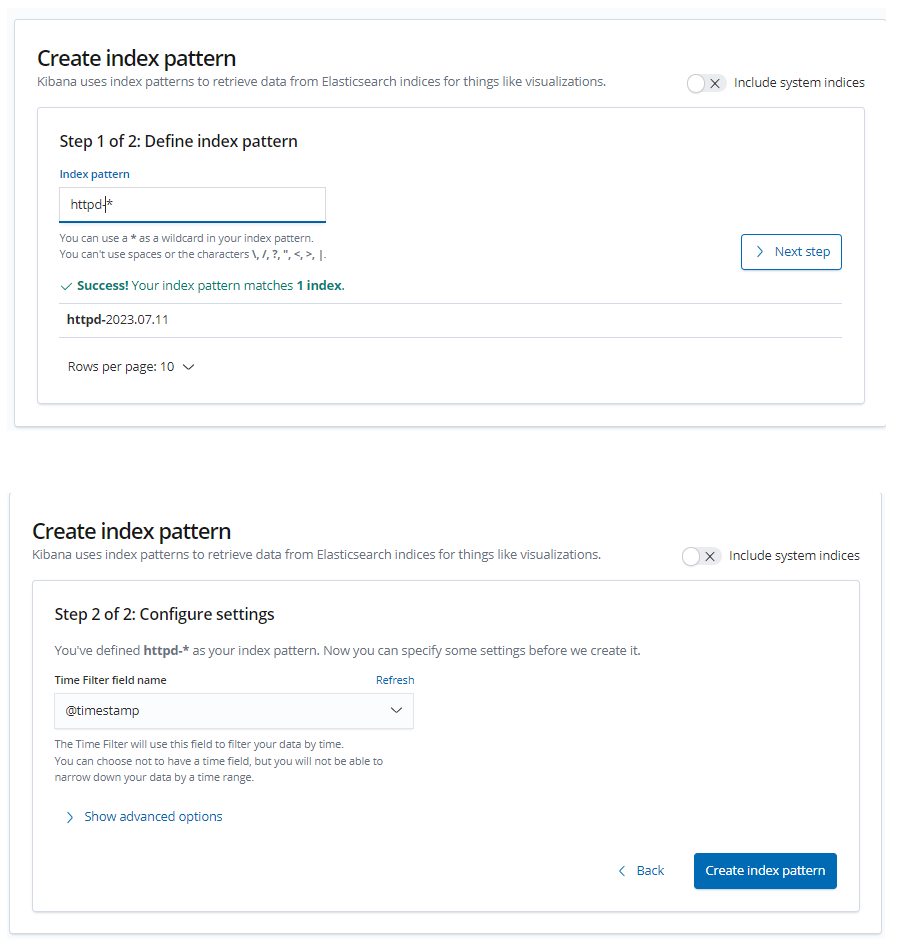
浏览器访问 http://192.168.145.45:5601 登录 Kibana,单击“Create Index Pattern”按钮添加索引“httpd-*”,单击 “create” 按钮创建,单击 “Discover” 按钮可查看图表信息及日志信息。

#若网页的索引显示%{[fields][service_name]},则可以删除之前运行的instance的缓冲数据
#保存在path.data里面有.lock文件中,查找到.lock文件的保存位置,删除该缓存文件。
cd /var/lib/
ll -A
rm -rf .lock
二、Filter 插件
1. grok 正则捕获插件
grok 使用文本片段切分的方式来切分日志事件。
1.1 内置正则表达式调用
#内置正则语法
%{SYNTAX:SEMANTIC}
#SYNTAX代表匹配值的类型,例如,0.11可以NUMBER类型所匹配,10.222.22.25可以使用IP匹配。
#SEMANTIC表示存储该值的一个变量声明,它会存储在elasticsearch当中方便kibana做字段搜索和统计,你可以将一个IP定义为客户端IP地址client_ip_address,如%{IP:client_ip_address},所匹配到的值就会存储到client_ip_address这个字段里边,类似数据库的列名,也可以把 event log 中的数字当成数字类型存储在一个指定的变量当中,比如响应时间http_response_time,假设event log record如下:
可以使用如下grok pattern来匹配这种记录
%{IP:client_id_address} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:http_response_time}

filter.conf 文件正则则取ip地址
在logstash conf.d文件夹下面创建filter.conf文件,内容如下
# /etc/logstash/conf.d/filter.conf
filter {
grok {
match => { "message" => "%{IP:client_id_address} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:http_response_time}" }
}
}
以下是filter结果
client_id_address: 192.168.145.15
method: GET
request: /index.html
bytes: 15824
http_response_time: 0.043
官方定义的内置正则表达式
logstash 官方也给了一些常用的常量来表达那些正则表达式,可以到这个 Github 地址查看有哪些常用的常量:
https://github.com/logstash-plugins/logstash-patterns-core/blob/main/patterns/ecs-v1/grok-patterns
grok-patterns文件内容如下
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











