




 通过对2017-2018年巴西Olist电商数据的分析,发现交易金额和订单量逐年上升,尤其2018年增长显著。用户主要在工作日和特定时间段活跃,且集中在SP、PR、MG洲。产品类别、支付方式分布均匀,但SP洲的sao paulo市交易额最高。RFM模型显示,流失用户和重要深耕用户值得关注。
通过对2017-2018年巴西Olist电商数据的分析,发现交易金额和订单量逐年上升,尤其2018年增长显著。用户主要在工作日和特定时间段活跃,且集中在SP、PR、MG洲。产品类别、支付方式分布均匀,但SP洲的sao paulo市交易额最高。RFM模型显示,流失用户和重要深耕用户值得关注。
作者:Dake
1. 分析背景
这是一份巴西Olist(2016年8月-2018年8月)电商数据平台的数据。这里只筛选了2017-2018年的数据来进行分析。
分析该数据可以看出近两年的销售业绩,店铺的经营状况,客户的区域分布,客户的购买偏好,以改善现有的状况,提升业绩。
数据链接:https://www.kaggle.com/jainaashish/orders-merged
数据解读:
2. 分析框架
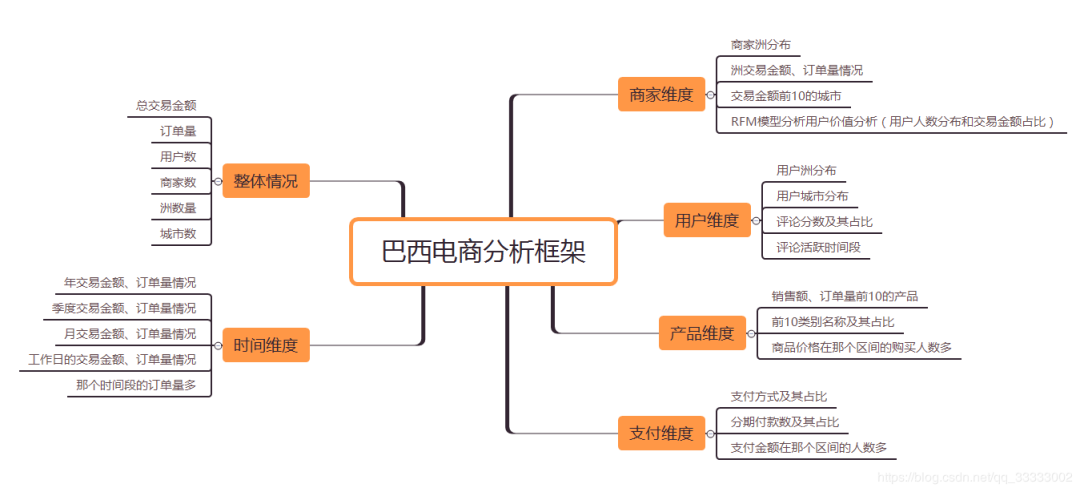
3. 可视化+分析
3.1 整体情况
笔单价 = 总交易金额 / 订单量
近两年的总交易金额:15124382,订单量:96211,笔单价:157.20。
客单价 = 总交易金额 / 用户数
用户数:93104,客单价:162.45。

3.2 时间维度
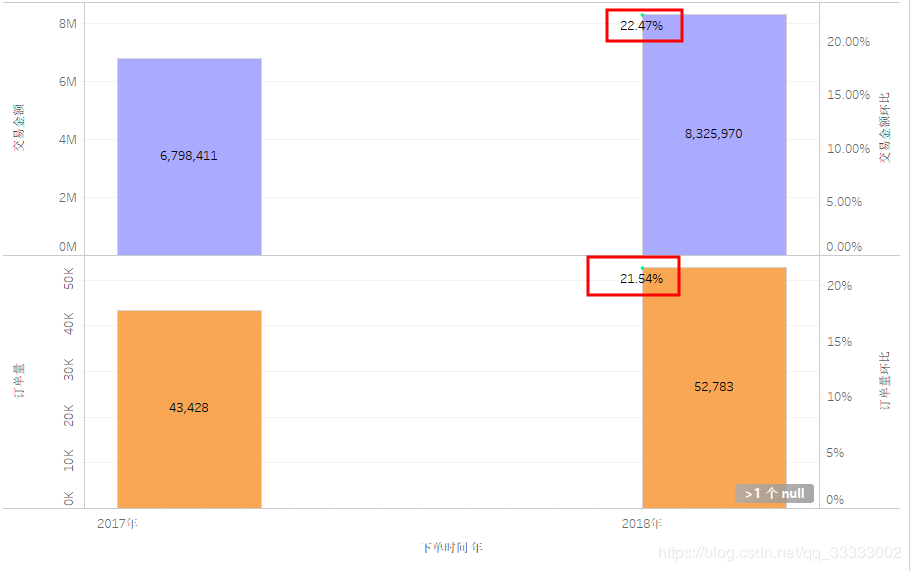
3.2.1 年交易金额、订单量情况
2017年交易金额:6798411,2018年交易金额:8325970,环比2017年增长22.47%。
2017订单量:43428,2018年订单量:52783,环比2017年增长21.54%。
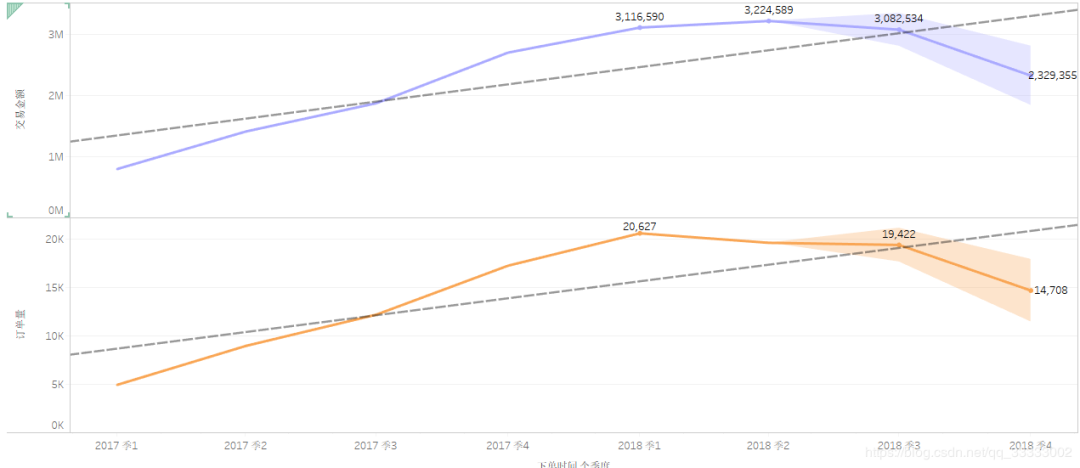
3.2.2 季度交易金额、订单量情况
各季度交易金额、订单量总体上呈现上升趋势。
预测2018第三季度交易金额:308W左右,订单量:19000。
预测2018第四季度交易金额:233W,订单量:14000。
预测2018年总交易额突破1000W。
3.2.3 月交易金额情况
交易金额整体上有逐渐上升的趋势。2017年11月达到峰值:1138353,环比增加54.11%。
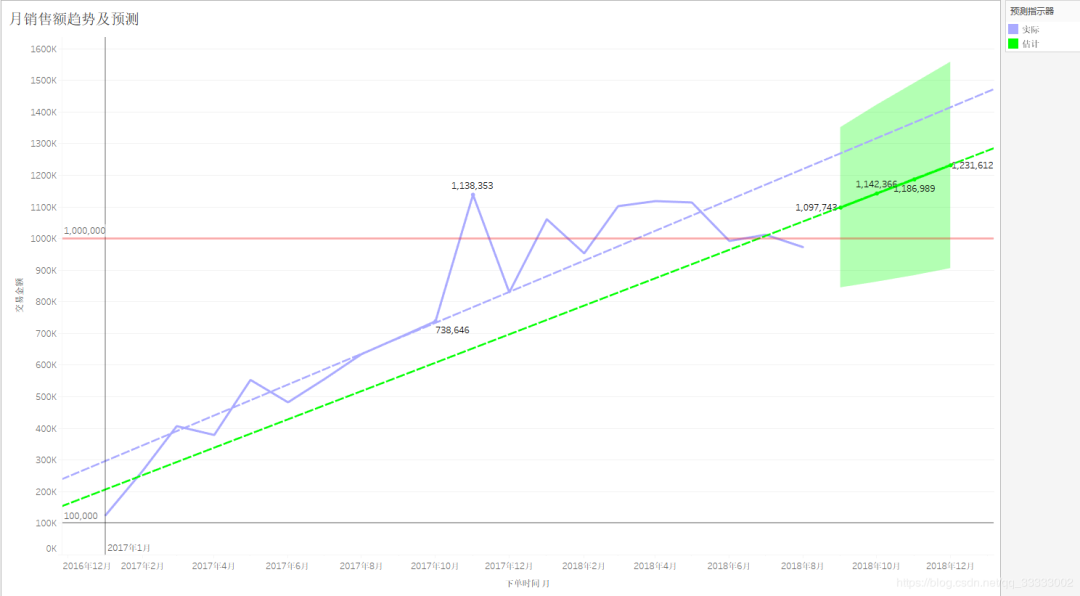
这里针对2017年11月交易金额达到峰值问题下钻。
查看2017年10月-12月的交易金额、订单量情况。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 828
828

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











