




项目背景
项目来源于Kesci平台:提供银行精准营销解决方案
项目简介
本练习赛的数据,选自UCI机器学习库中的「银行营销数据集(Bank Marketing Data Set)」
这些数据与葡萄牙银行机构的营销活动相关。这些营销活动以电话为基础,一般,银行的客服人员需要联系客户至少一次,以此确认客户是否将认购该银行的产品(定期存款)。
因此,与该数据集对应的任务是「分类任务」,「分类目标」是预测客户是(’ 1 ‘)或者否(’ 0 ')购买该银行的产品。
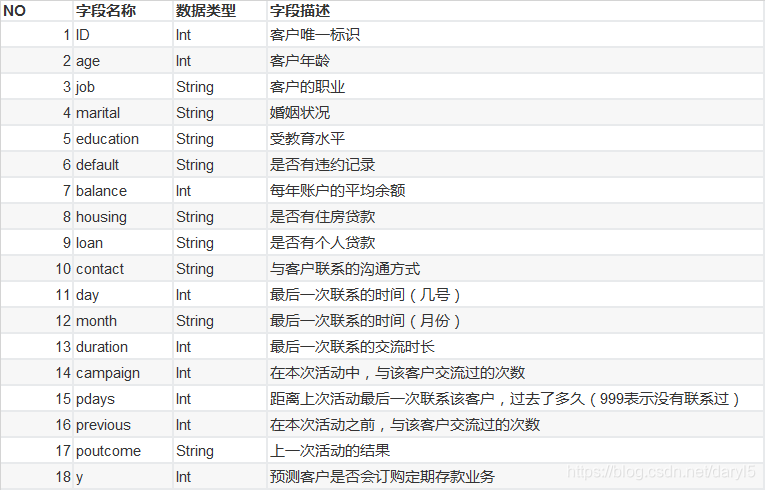
数据字段说明
本次测评算法为: AUC(Area Under the Curve)
本项目的数据集比较简单,不用过多的预处理。因样本存在严重的不平衡问题,本文借此探索在样本不平衡情况下的一些简单处理方案。
数据导入及探索
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
train=pd.read_csv(r'E:\date\kesci\train_set.csv')
test=pd.read_csv(r'E:\date\kesci\test_set.csv')
train.shape
#out:(25317, 18)
test.shape
#out:(10852, 17)
train.isnull().sum() #不存在缺失值
train.duplicated().sum() #不存在重复值
train.describe() #无异常值
train['y'].value_counts()[1]/train['y'].value_counts().sum()
#out:0.11695698542481336
#样本存在严重的不均衡问题,正样本数只占11.7%
由上述探索可发现,数据集比较规范,就是样本不平衡问题比较严重。
数据预处理
从上述探索数据的过程中发行,特征中有连续型数值特征,二值型描述特征,离散型特征。
下面需要对不同特征进行分别处理:
连续型数值特征:数据标准化(下面建模要用到逻辑回归)
二值型描述特征:二值化
离散型特征:one-hot编码
#需要进行数据无量纲化处理的列
standard_scaler_list=['age','balance','duration','campaign','pdays','previous']
#需要转换为0-1二值编码的列
set_01_list=['default','housing','loan']
#需要进行one-hot编码的列
one_hot_list=['job','marital','education','contact','day','month','poutcome']
#1.0-1编码
#训练集
from sklearn.preprocessing import OrdinalEncoder
train_done=train.copy()
encoder=OrdinalEncoder()
encoder.fit(train_done.loc[:,set_01_list])
train_done.loc[:,set_01_list]=encoder.transform(train_done.loc[:,set_01_list])
#测试集
test_done=test.copy()
test_done.loc[:,set_01_list]=encoder.transform(test_done.loc[:,set_01_list])
#2.one-hot编码
#训练集
train_onehot=train[one_hot_list]
for i in one_hot_list:
a=pd.get_dummies(train_onehot[i],columns=[i],prefix=i)
train_done=pd.concat([train_done,a],axis=1)
train_done.drop(one_hot_list,axis=1,inplace=True)
#测试集
test_onehot=test[one_hot_list]
for i in one_hot_list:
a=pd.get_dummies(test_onehot[i],columns=[i],prefix=i)
test_done=pd.concat([test_done,a],axis=1)
test_done.drop(one_hot_list,axis=1,inplace=True)
#3.数据无量纲化
#训练集
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
scaler.fit(train_done.loc[:,standard_scaler_list])
train_done.loc[:,standard_scaler_list]=scaler.transform(train_done.loc[:,standard_scaler_list])
#测试集
test_done< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2895
2895



 到【灌水乐园】发言
到【灌水乐园】发言







