






 在SpringBoot项目中,尝试让一个应用同时消费Kafka的两个不同Topic时遇到了问题。当一个Topic使用默认消费方式,另一个指定了特定Partition时,出现提交Offset错误。经过排查,尝试了设置监听器ID、开启多线程和更改clientId,最终发现错误源于相同的groupId。通过为每个Topic分配不同的groupId,成功解决了问题,实现了正常消费。
在SpringBoot项目中,尝试让一个应用同时消费Kafka的两个不同Topic时遇到了问题。当一个Topic使用默认消费方式,另一个指定了特定Partition时,出现提交Offset错误。经过排查,尝试了设置监听器ID、开启多线程和更改clientId,最终发现错误源于相同的groupId。通过为每个Topic分配不同的groupId,成功解决了问题,实现了正常消费。
本来是个简单的问题,但是复杂了。
两个topic 消费方式不一样,一个使用过的是默认方式,不指定partition,另外一个,指定了特殊的partition。报错:
11:10:32.888 [org.springframework.kafka.KafkaListenerEndpointContainer#1-0-C-1]
ERROR o.a.k.c.c.i.ConsumerCoordinator -
[Consumer clientId=futures_deal_group-1302249340-0, groupId=deal_group]
Offset commit failed on partition topic-depth-6 at offset 1535688270: The coordinator is not aware of this member
11:10:32.888 [org.springframework.kafka.KafkaListenerEndpointContainer#1-0-C-1]
WARN o.a.k.c.c.i.ConsumerCoordinator -
[Consumer clientId=futures_deal_group-1302249340-0, groupId=deal_group]
Asynchronous auto-commit of offsets {topic-depth-6=OffsetAndMetadata{offset=1535688270, metadata=''}}
failed: Commit cannot be completed since the group has already rebalanced and assigned the partitions to another member. This means that the time between subsequent c
alls to poll() was longer than the configured max.poll.interval.ms,
which typically implies that the poll loop is spending too much time message processing.
You can address this either by increasing the session timeout or by reducing the maximum size of batches returned in poll() with max.poll.records.
大意就是提交的 offer 不是这个topic的,coordinator 不是这个topic
首先,单独跑任意一个topic 都可以正常运行,并能提交offersize 位置。
猜测一下 KafkaListenerEndpointContainer 报的错,就从他入手呗
可惜,spring-boot 里面并没有这个文件
那先找相近的来看看。从这开始,找 ConcurrentKafkaListenerContainerFactory 这个类
public KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, String>> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(new DefaultKafkaConsumerFactory<>(tickerConsumerConfigs()));
factory.setConcurrency(1);
factory.setBatchListener(true);
factory.getContainerProperties().setPollTimeout(1500);
return factory;
}
找到父类 AbstractKafkaListenerContainerFactory,这里用到了 endpoint
public C createListenerContainer(KafkaListenerEndpoint endpoint) {
C instance = createContainerInstance(endpoint);
if (endpoint.getId() != null) {
instance.setBeanName(endpoint.getId());
}
if (endpoint instanceof AbstractKafkaListenerEndpoint) {
configureEndpoint((AbstractKafkaListenerEndpoint<K, V>) endpoint);
}
endpoint.setupListenerContainer(instance, this.messageConverter);
initializeContainer(instance, endpoint);
return instance;
}
继续找,发现 KafkaListenerEndpoint 中有这样的说明,endpoint 的ID 在 factory 里面有用于区分其他的listener
public interface KafkaListenerEndpoint {
/**
* Return the id of this endpoint.
* @return the id of this endpoint. The id can be further qualified
* when the endpoint is resolved against its actual listener
* container.
* @see KafkaListenerContainerFactory#createListenerContainer
*/
String getId();
/**
* Return the groupId of this endpoint - if present, overrides the
* {@code group.id} property of the consumer factory.
* @return the group id; may be null.
* @since 1.3
*/
String getGroupId();
对于未知的错误是不是我们的两个topic 都用 KafkaListenerEndpointContainer 一个而导致的问题,加上 id
同时考虑 开始多个线程,试试能否解决
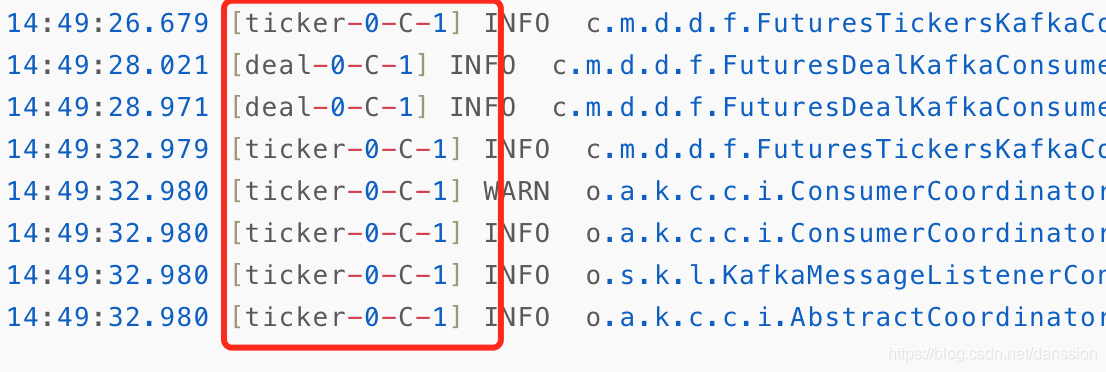
线程id 变了,还有问题。
继续寻找,在 org.springframework.kafka.listener.ConcurrentMessageListenerContainer 发现
for (int i = 0; i < this.concurrency; i++) {
KafkaMessageListenerContainer<K, V> container;
if (topicPartitions == null) {
container = new KafkaMessageListenerContainer<>(this, this.consumerFactory, containerProperties);
}
else {
container = new KafkaMessageListenerContainer<>(this, this.consumerFactory,
containerProperties, partitionSubset(containerProperties, i));
}
String beanName = getBeanName();
container.setBeanName((beanName != null ? beanName : "consumer") + "-" + i);
if (getApplicationEventPublisher() != null) {
container.setApplicationEventPublisher(getApplicationEventPublisher());
}
container.setClientIdSuffix("-" + i);
container.setGenericErrorHandler(getGenericErrorHandler());
container.setAfterRollbackProcessor(getAfterRollbackProcessor());
container.setRecordInterceptor(getRecordInterceptor());
container.setEmergencyStop(() -> {
stop(() -> {
// NOSONAR
});
publishContainerStoppedEvent();
});
if (isPaused()) {
container.pause();
}
container.start();
this.containers.add(container);
}
}
container 的生成跟clientId 有关?为每个 consumer 新增一个clientId 试试,依然报错
是不是果真如猜测的,是因为某个bean是公用的导致,提交offer 报错吗?
本地debug 时,ConcurrentKafkaListenerContainerFactory 、DefaultKafkaConsumerFactory 其实都不是一个类
在本地单独调试 topic2 时,服务器单独消费 topic1 居然又报错了,并且kafka 管理平台中观察topic1 的消费点位不变化了,与同时启动,2个consumer 的情况一样。
如此可以推断这个报错与 同时消费两个topic的 groupId 有关系。
修改代码 使用不同的 groupId,程序正常~~~~!!!

















 798
798

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









