



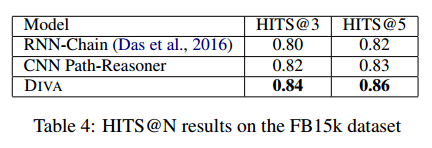
 该文关注知识图谱推理中的路径寻找和路径推理问题,通过变分自编码器模型增强两者之间的交互,提高模型的鲁棒性。研究者提出了一种新的框架,将路径作为潜在变量,关系作为可观察变量,利用近似后验模块和路径推理模块进行推理。实验表明,该方法在处理大型知识图谱的多跳链接预测中表现优秀。
该文关注知识图谱推理中的路径寻找和路径推理问题,通过变分自编码器模型增强两者之间的交互,提高模型的鲁棒性。研究者提出了一种新的框架,将路径作为潜在变量,关系作为可观察变量,利用近似后验模块和路径推理模块进行推理。实验表明,该方法在处理大型知识图谱的多跳链接预测中表现优秀。
来源
Wenhu Chen, Wenhan Xiong, Xifeng Yan, William Yang Wang
Department of Computer Science
University of California, Santa Barbara
Santa Barbara, CA 93106
fwenhuchen,xwhan,xyan,williamg@cs.ucsb.edu
背景
大规模的知识图谱在下游的自然处理应用中有很重要的支撑作用,例如在问答系统、响应生成。然而大型的知识图谱中很多事实是缺失的,因此自动推理以及从观察证据做出新的推断的能力引起了很多学者的关注。大型知识图谱的实体以及链接给传统的基于符号的推理算法造成很大的挑战。为了解决多跳链接预测问题,全球学者提出很多有重要意义的方法。例如PRA算法利用深度有界的随机游走方法获得路径,最近的DeepPath 和MINERVA将路径寻找问题建模为马尔科夫随机过程,通过强化学习的方法最大化奖励。 另外一些链式推理和组合推理的方法利用PRA
算法得到的路径作为输入,进而推断关系。
motivation
本文将知识图谱推理问题归结为两步:路径寻找和路径推理。目前的方法大部分注意力在其中一步中,缺少两步之间的交互。这对理解多样化的输入造成阻碍,使得模型对噪声的影响十分敏感。为了增加模型的鲁棒性,处理增加复杂的环境,本文期望提高两个步骤的交互,将这个问题建模为潜在变量图模型,将路径作为潜在的变量,关系作为给定实体对后可以观察的变量,因此将路径寻找模块作为一个先验分布来推断潜在的链接,路径推理模块作为一个似然分布,将潜在链接分为多个类别。基于上面的建设,引入一个近似后验模块并设计一个变分自编码器(VAE)。
补充知识
变分自编码器是一个非常流行的算法,在大规模场景中进行近似后验推断。参见论文()
变分知识图谱推断
首先将关系分类问题定义为一个目标函数:
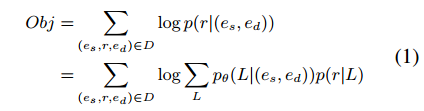
L
L
L是潜在的链接路径,证据概率
p
(
r
∣
e
s
,
e
d
)
p(r|e_s,e_d)
p(r∣es,ed)在潜在空间中写成两个部分的乘积的形式。最大化变分下界:
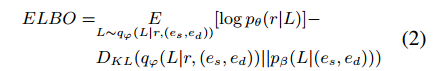
路径推理模块
路径推理模块采用了卷积神经网络和前馈网络,模型将路径序列
L
(
a
1
,
e
1
,
.
.
.
.
,
a
i
,
e
i
,
.
.
.
.
,
a
n
.
e
n
)
L(a_1,e_1,....,a_i,e_i,....,a_n.e_n)
L(a1,e1,....,ai,ei,....,an.en)作为输入,然后输出关系的概率分布。框架图:
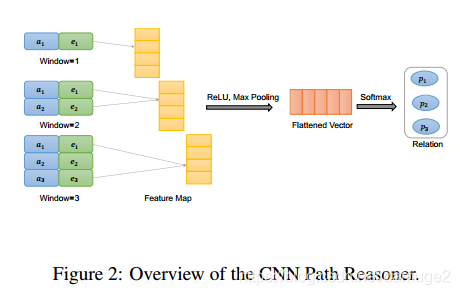
本文里将关系的embedding和实体的embedding连接在一起
(
f
1
,
f
2
,
,
.
.
.
,
f
n
)
(f_1,f_2,,...,f_n)
(f1,f2,,...,fn), 将embedding 序列的长度填充为长度
N
N
N,设计三层卷积神经网络,窗口大小分别是
(
1
×
2
E
)
(1\times 2E)
(1×2E)、
(
2
×
2
E
)
(2\times 2E)
(2×2E)、
(
3
×
2
E
)
(3\times 2E)
(3×2E)。输入通道为1,过滤器大小
D
D
D,在卷积层后使用
(
N
×
1
)
,
(
(
N
−
1
)
×
1
)
,
(
(
N
−
2
)
×
1
)
(N \times 1), ((N-1) \times 1),((N-2) \times 1)
(N×1),((N−1)×1),((N−2)×1), 最大池化,然后连接在一起组成一个向量
F
∈
R
3
D
F \in R^{3D}
F∈R3D, 使用一个双层感知机模型,输出关系的概率分布
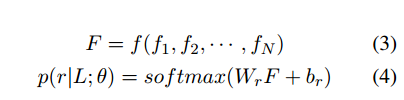
路径寻找模块
将路径寻找问题
p
(
L
∣
e
s
,
e
d
)
p(L|e_s,e_d)
p(L∣es,ed)建模为马尔科夫决策过程,基于历史,递归的预测动作,即一条边
(
a
,
e
)
(a,e)
(a,e)。
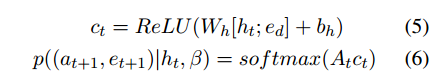
隐藏状态的计算是使用一个lstm神经网络:
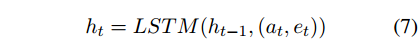
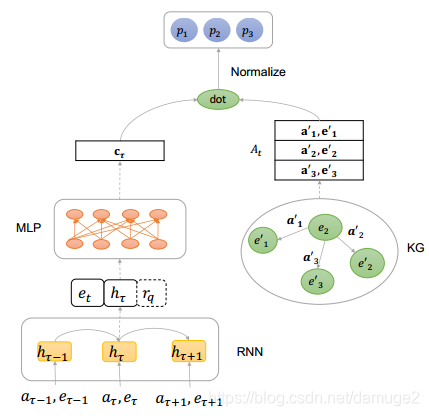
近似后验模型
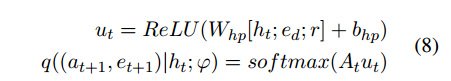
近似后验模块和先验分布模块的不同点在于,近似后验模块知道关系
r
r
r可以做出更相关的决策。
优化
为了最大化与上述神经网络相关的变分下界,接下来从变分编码的角度来解释负的变分下界(ELBO)作为两部分损失,使用梯度下降算法最小化负的变分下界。
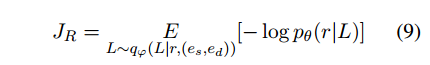
这个函数重建关系R,从近似后验模块采样路径
L
L
L,根据
L
L
L重构关系
R
R
R,优化这个损失函数使得近似后验模块可以获得特定关系
r
r
r的路径,并且帮助路径推理模块在多跳路径上推理预测真正的关系
r
r
r.
KL散度:
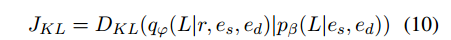
优化这个损失函数的目的是让先验分布向后验分布逼近,原因是实体对已经暗含这种关系了,因此我们让路径查找模块尽可能接近后验分布模块。在测试的时候,因为不知道关系
r
r
r,因此使用路径查找模块代替后验分布。
训练

实验
数据集:
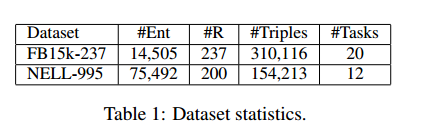
负采样引入一个随机的n/a关系,分解
(
e
q
,
r
q
,
[
e
1
−
,
e
2
−
,
.
.
.
,
e
n
+
]
)
(e_q,r_q,[e^-_1,e^-_2,...,e^+_n])
(eq,rq,[e1−,e2−,...,en+])为一系列的三元组
(
e
q
,
r
q
′
,
e
i
)
(e_q,r^{\prime}_q,e_i)
(eq,rq′,ei)
对于正例来说,
r
q
′
=
r
q
r^{\prime}_q = r_q
rq′=rq, 对于负样例,
r
q
′
=
r
q
r^{\prime}_q = r_q
rq′=rq。 训练时采用SGD算法更新三个模块的参数,在测试时,在路径寻找模块使用束搜索排名靠前的路径,这个打分来源于路径推理模块。
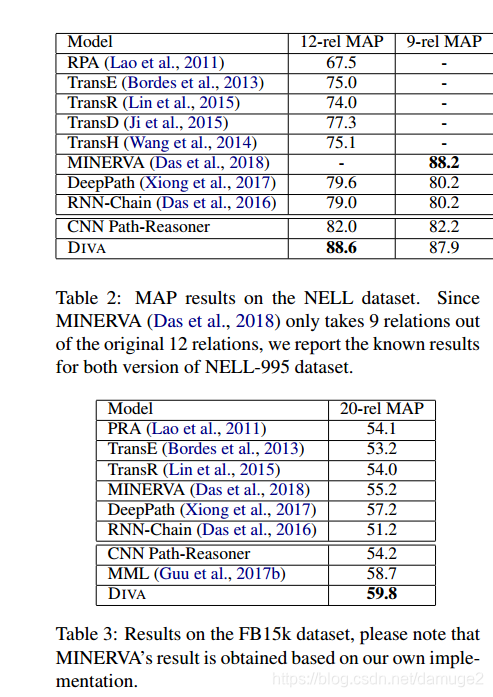
考察beam size的影响:
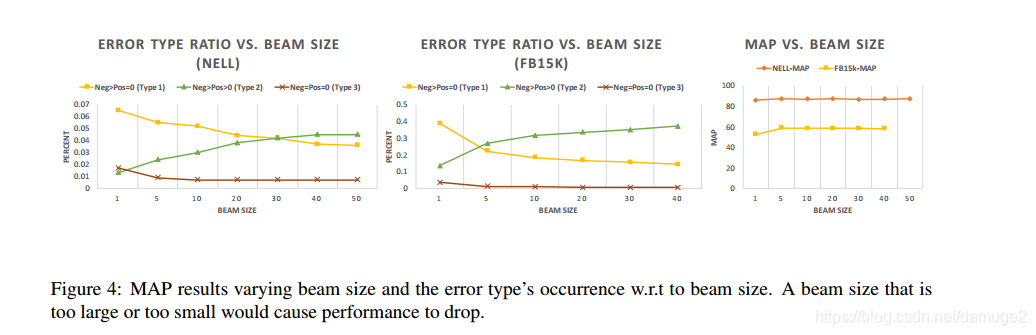
beam_size 较大,路径寻找模块可以获得更多的链接路径,但同时会引入更多的噪音给路径推理模块带来挑战。使用较小的beam_size,路径寻找模块受限于找到连接两个正实体的路径,但是同时也较少了噪音的情况。通过实验表明 本文中beam_size 取5的情况比较合适。
错误分析:


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









