




主要贡献
- 提出一个新的关系分类模型,它有实体选择器与关系分类器构成。它能够在句子级别提取关系。
- 将实体选择问题转换成强化学习问题,这使得不需要实体选择的标签,而只需要关系分类器的弱监督的回馈就能进行实体选择。
摘要
现在的关系分类方法都是依赖拍距离监督假设(distance supervision assume)的,它假设一系列提到一对实体的句子,都是在描述这对实体的一种关系。类似于这种思想的方法,其实都是一组句子层面的分类,无法学习出关系与句子之间的映射,并且这种方法对噪声很敏感。
在这篇论文中,作者提出了一种新的模型,它能够在句子层面进行关系分类,并且对噪声的容忍度很强。这个模型主要分为两个模块:实体选择器和关系分类器。实体选择器通过强化学习选出高质量的句子,然后喂给关系分类器;
关系分类器能够进行句子级别的关系预测,并给实体选择器提供反馈。这两个模块会联合训练,从而不断优化整个模型。
实验结果显示,这个模型能够减少噪声的影响,在句子层面获得更好的分类结果。
引言
为了解决噪声标签的问题,之前的研究都是采用多实体学习的方式来考虑实体的噪声。在这种方式中,训练以及测试都是在一组句子级别的,噪声会比较大。因此,之前的研究都有以下两种缺陷:
1. 无法在句子级别进行预测。
2. 对一组句子中的噪声非常敏感。在这篇文章中,为了解决上述两种缺陷,作者提出了一种新的关系分类模型。通过实体选择器,从一组句子中选出高质量的句子,然后通过句子级别的关系分类器来选择关系。
为了解决第二种缺陷,如果一整个包的句子标签都是错误的,那么句子选择器将会过滤掉整个包。
在这里,一个主要的问题是如何联合训练上述两个模块,特别是当实体选择器一开始不知道哪些句子的标签是不正确的。
尽管我们无法用监督的方式来进行实体选择,但是我们可以从整体上来度量选出的句子。实体选择的过程有一下两个属性:
1. 试错搜索(trial-and-error-search)。实体选择器试图找出一些句子,这些句子在关系选择的时候会获得reward。
2. 只有当完成实体选择之后,关系分类器才会把反馈给实体选择器,也就是delayed。
相关论文
神经网络被广泛用于关系分类,其中包括CNN(1,2),RNN,LSTM(1,2)。Wang提出用两层Attention从异构环境中为关系分类辨别模式。
一般来说,训练神经网络需要大量的标签数据,而标签数据又非常稀缺。为了解决这个问题,Mintz提出远程监督,但是这个方法还是无法解决噪声数据干扰问题。Lin 2016,Ji 2017,Tianyu Liu and Sui 2017等人提出了多实体下的句子级别的Attention机制,它能够降低错误句子的权重。但是这些方法只能在一组句子级别找关系,无法在句子级别找关系。Narasimhan, Yala, and Barzilay 2016提出使用强化学习来改善信息提取。
问题定义
- 实体选择问题
将<句子,关系标签>对表示为 X={(x1,r1),(x2,r2),⋯,(xn,rn)} X = { ( x 1 , r 1 ) , ( x 2 , r 2 ) , ⋯ , ( x n , r n ) } ,其中 xi x i 是与一句话有关的两个实体 (hi,ti) ( h i , t i ) , ri r i 是远程监督生成的关系。目的是找出关系正确的句子。
- 关系分类问题
给出一句句子 xi x i 以及这句句子提到的一对实体 (hi,ti) ( h i , t i ) ,目标是预测 ri r i 。概率公式为 PΦ(ri|xi,hi,ti) P Φ ( r i | x i , h i , t i ) 。
在实体选择阶段,每个句子 xi x i 会绑定一个 action ai a i ,来表示 xi x i 是否被选作训练实体。状态 si s i 用当前句子 xi x i 来表示。实体选择器根据随机策略对给定当前状态的动作进行采样。关系分类器采用一个卷集架构来得出一对实体的语义关系。下图体现了这个框架的架构图。
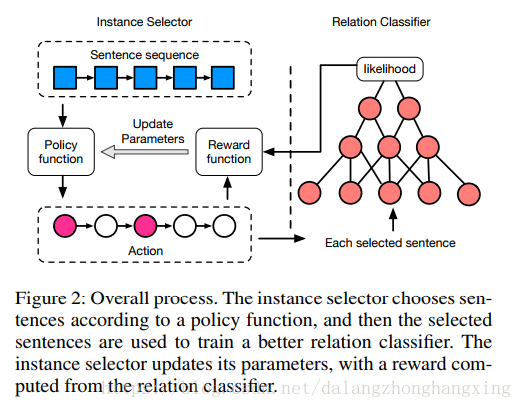
实体选择器(Instance Selector)
对于实体选择器而言,它的主要任务是根据Policy函数,来决定在某种State(包含当前句子,已选出的句子集合,实体对)下,应该采取哪种Action(选或不选)。然后接收从关系分类器传来反馈。
如果我们按照前面说的,当选出了所有的高质量句子之后,再接收关系分类器给出的延迟奖励,然后更新Policy函数的参数,这种方式是低效的。
为了获得更多的反馈,使得训练过程更加有效,作者将训练集分词N组 B={B1,B2,⋯,BN} B = { B 1 , B 2 , ⋯ , B N } ,每一组完成句子选择之后,就会获得Reward。每一组的实体对都是不同的,但是它们的关系标签都是相同的, Bk={xk1,xk2,⋯,xk|Bk|} B k = { x 1 k , x 2 k , ⋯ , x | B k | k } 都具有相同的标签 rk r k 。当训练集中的句子都训练完成之后,会将每一组中选出的句子合并,统一进行关系分类。
状态(State)
状态 si s i 主要包含当前句子,已经选出的句子以及实体对。作者使用一个连续函数 F(si) F ( s i ) 来表示状态,它将输出一个Vector。
1. 当前句子的Vector表示是从用于关系分类的CNN的非线性层中获得。
2. 已选出句子集合的Vector表示是每句句子Vector的平均值。
3. 一对实体的Vector表示是从预训练的knowledge graph embedding中获得。
动作(Action)
动作 ai a i 的的取值是{0,1},表示是否选取一句句子。 ai a i 根据Policy函数 πθ(si,ai) π θ ( s i , a i ) 获得,其中 θ θ 是需要学习的参数。
其中 F(si) F ( s i ) 就是状态特征Vector, θ={W,b} θ = { W , b } 。
奖励\回馈(Reward)
Reward的作用的反映选出句子的有用程度。作者假设这个模型完成所有的选择之后,会有一个最奖励,因此只需要在最终状态 s|B|+1 s | B | + 1 接收一个delayed reward,其他状态的奖励都是0。因此Reward函数定义如下:
其中 Bˆ B ^ 是选出的句子集合, r r 是当前句子组的关系标签,是关系分类器,它由CNN模型构成。对于 Bˆ B ^ 是空集的情况,其奖励为训练集中所有句子得分的平均值,这能是实体选择器更有效地消除噪声影响。
注意,关系分类器 p(r|x) p ( r | x ) 是作用在每句句子上的,而Reward是在一组句子的基础上计算的,因此Reward能够全面评估Policy函数选出的句子的有用性。它通过弱监督的方式来最大化选出句子的平均似然估计,从而使得实体选择器的目标函数与关系分类器一致。
优化
对于每组句子 B B ,目标是最大化Reward,目标函数如下:
其中 ai∼πθ(si,ai) a i ∼ π θ ( s i , a i ) , si+1∼P(si+1|si,ai) s i + 1 ∼ P ( s i + 1 | s i , a i ) 。转移方程 P(si+1|si,ai) P ( s i + 1 | s i , a i ) 等于 πθ(si+1,ai+1) π θ ( s i + 1 , a i + 1 ) ,因为 si+1 s i + 1 的值可以被 si s i 与 ai a i 确定。那么梯度按照如下方式计算:
1. 对于每组句子,根据Policy函数计算每个句子的state以及action,得到 {s1,a1,s2,a2,⋯,s|B|,a|B|,s|B+1|} { s 1 , a 1 , s 2 , a 2 , ⋯ , s | B | , a | B | , s | B + 1 | } 。
2. 将选出的句子喂给关系分类器,根据结果得到reward r(s|B|+1|B) r ( s | B | + 1 | B ) 。
3. 按照 θ←θ+α∑|B|i=1vi▽θlogπθ(si,ai) θ ← θ + α ∑ i = 1 | B | v i ▽ θ l o g π θ ( s i , a i ) 的规则去更新 θ θ 。
关系分类器(Relation Classifier)
在关系分类器中,使用CNN来预测关系,它由一个输入层,一个卷积层,一个max poolling层,一个非线性层组成。
输入层
对于每个句子 x x ,我们将它表示成一系列向量。每个向量由两部分组成:word embedding和pisition embedding。word embedding用word2Vec实现,维度为 dw d w 。position embedding是按照当前单词到开头和结束的相对位置来计算的,维度为 dp d p 。然后将word embedding和pisition embedding进行组合,得到新的向量 wi w i ,维度为 dw+2∗dp d w + 2 ∗ d p 。
CNN
为了得到更高级、更抽象的句子表示,作者使用了CNN来得到新的特征L:
L=CNN(x) L = C N N ( x )
其中 x x 就是输入层的输入,是一个 ds d s 维的矩阵,作者取230。因此卷积的参数 Wf∈Rds∗3d,bf∈Rds W f ∈ R d s ∗ 3 d , b f ∈ R d s 。然后关系预测的概率为 p(r|x;Φ)=softmax(Wr∗tanh(L)+br) p ( r | x ; Φ ) = s o f t m a x ( W r ∗ t a n h ( L ) + b r ) ,其中 Wr∈Rds∗nr,br∈Rnr W r ∈ R d s ∗ n r , b r ∈ R n r , nr n r 是关系总数。
损失函数(Loss Function)
给出选出的句子集合 {Xˆ} { X ^ } ,我们使用交叉熵作为损失函数。

















 8343
8343

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









