




 本文深入解析CART算法,包括其采用的二分递归分割技术,适用于连续型和离散型变量的特点,以及如何通过基尼指数进行决策树构建。同时,文章详细介绍了CART分类树和回归树的工作原理。
本文深入解析CART算法,包括其采用的二分递归分割技术,适用于连续型和离散型变量的特点,以及如何通过基尼指数进行决策树构建。同时,文章详细介绍了CART分类树和回归树的工作原理。
CART简介
CART算法采用二分递归分割的技术将当前样本集分为两个子样本集,使得生成的每个非叶子节点都有两个分支。非叶子节点的特征取值为True和False,左分支取值为True,右分支取值为False,因此CART算法生成的决策树是结构简洁的二叉树。CART可以处理连续型变量和离散型变量,利用训练数据递归的划分特征空间进行建树,用验证数据进行剪枝。
- 如果待预测分类是离散型数据,则CART生成分类决策树。
- 如果待预测分类是连续性数据,则CART生成回归决策树。
CART分类树
描述不确定性可以使用熵也可以使用基尼指数。同熵,基尼指数越大,样本集合的不确定性越大。
假设有
K
K
K个类,样本点属于第
k
k
k个类的概率为
p
k
p_k
pk,则概率分布的基尼指数定义为
G
i
n
i
(
p
)
=
∑
k
=
1
K
p
k
(
1
−
p
k
)
=
1
−
∑
k
=
1
K
p
k
2
Gini(p)=\sum_{k=1}^Kp_k(1-p_k)=1-\sum_{k=1}^Kp_k^2
Gini(p)=k=1∑Kpk(1−pk)=1−k=1∑Kpk2
根据基尼指数定义,可以得到样本集合
D
D
D的基尼指数,其中
C
k
C_k
Ck表示数据集
D
D
D中属于第
k
k
k类的样本子集。
G
i
n
i
(
D
)
=
=
1
−
∑
k
=
1
K
(
∣
C
k
∣
∣
D
∣
)
2
Gini(D)==1-\sum_{k=1}^K\left(\frac{|C_k|}{|D|}\right)^2
Gini(D)==1−k=1∑K(∣D∣∣Ck∣)2
如果数据集
D
D
D根据特征
A
A
A在某一取值
a
a
a上进行分割,得到
D
1
,
D
2
D1,D2
D1,D2两部分后,那么在特征
A
A
A下集合
D
D
D的基尼系数如下所示。
G
i
n
i
(
D
,
A
)
=
∣
D
1
∣
D
G
i
n
i
(
D
1
)
+
∣
D
2
∣
D
G
i
n
i
(
D
2
)
Gini(D,A)=\frac{|D1|}{D}Gini(D1)+\frac{|D2|}{D}Gini(D2)
Gini(D,A)=D∣D1∣Gini(D1)+D∣D2∣Gini(D2)
其中基尼系数
G
i
n
i
(
D
)
Gini(D)
Gini(D)表示集合
D
D
D的不确定性,基尼系数
G
i
n
i
(
D
,
A
)
Gini(D,A)
Gini(D,A)表示
A
=
a
A=a
A=a分割后集合
D
D
D的不确定性。
依据信息增益,决策树构建应该是选择最大的信息增益,首先选择最优分割点,即
m
a
x
a
∈
A
(
G
i
n
i
(
D
)
−
G
i
n
i
(
D
,
A
)
)
\underset{a\in A}{max} (Gini(D)-Gini(D,A))
a∈Amax(Gini(D)−Gini(D,A))
再然后,选择最优分割属性
m
a
x
A
∈
A
t
t
r
i
b
u
t
e
(
m
a
x
a
∈
A
(
G
i
n
i
(
D
)
−
G
i
n
i
(
D
,
A
)
)
)
\underset{A\in Attribute}{max}(\underset{a\in A}{max} (Gini(D)-Gini(D,A)))
A∈Attributemax(a∈Amax(Gini(D)−Gini(D,A)))
由于针对当前步计算时Gini(D)为固定值,所以以上可以改写为
m
i
n
a
∈
A
G
i
n
i
(
D
,
A
)
m
i
n
A
∈
A
t
t
r
i
b
u
t
e
(
m
i
n
a
∈
A
G
i
n
i
(
D
,
A
)
)
\underset{a\in A}{min} \ Gini(D,A)\\ \underset{A\in Attribute}{min}(\underset{a\in A}{min} \ Gini(D,A))
a∈Amin Gini(D,A)A∈Attributemin(a∈Amin Gini(D,A))
实例参考:https://blog.youkuaiyun.com/ExtraMan/article/details/41744003
CART回归树
CART回归树预测回归连续型数据,假设
X
X
X与
Y
Y
Y分别是输入和输出变量,并且
Y
Y
Y是连续变量。即
D
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
⋯
,
(
x
n
,
y
n
)
}
D = \{(x_1,y_1),(x_2,y_2),\cdots,(x_n,y_n)\}
D={(x1,y1),(x2,y2),⋯,(xn,yn)}
- 在训练数据集所在的输入空间中,递归的将每个区域划分为两个子区域并决定每个子区域上的输出值,构建二叉决策树。
- 选择最优切分变量
j
j
j(属性)与切分点
s
s
s(值):遍历变量
j
j
j,对规定的切分变量
j
j
j扫描切分点
s
s
s,选择使下式得到最小值时的
(
j
,
s
)
(j,s)
(j,s)对。其中
R
R
R是被划分的输入空间,
c
c
c是空间
R
R
R对应的固定输出值。
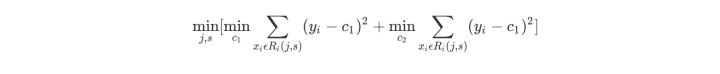
对于 G i n i ( D , A ) Gini(D,A) Gini(D,A)当分布较均匀时(或数据稳定时),值会小,类比于上式的方差(方差也是描述数据的稳定性) - 用选定的
(
j
,
s
)
(j,s)
(j,s)对,划分区域并决定相应的输出值
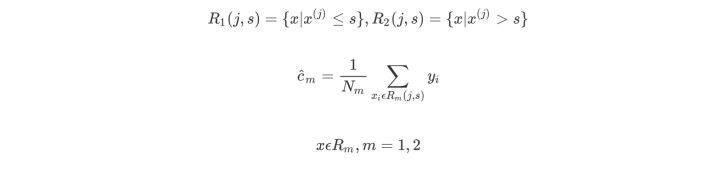
- 继续对两个子区域调用上述步骤,将输入空间划分为
M
M
M(为树的叶子节点数)个区域
R
1
,
R
2
,
⋯
,
R
M
R_1,R_2,\cdots,R_M
R1,R2,⋯,RM,生成决策树,
I
I
I返回0或1。(某个输入只能对应到一个叶子节点,这个地方的理解可能有问题)
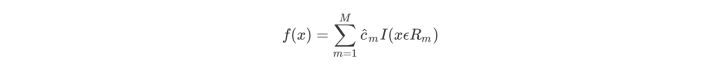
实例参考:
1.https://www.cnblogs.com/limingqi/p/12421960.html
2.https://blog.youkuaiyun.com/huahuaxiaoshao/article/details/86183738

















 5003
5003

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









