




 博客介绍了Hadoop MapReduce中如何实现map和reduce任务的重叠执行,特别是shuffle阶段的细节。在原始论文中,reduce工作在所有map完成后开始,但在Hadoop中,reduce的shuffle阶段可以提前启动,当map达到一定比例时就开始拉取数据,通过参数`mapreduce.reduce.shuffle.merge.percent`进行配置。然而,真正的reduce执行仍需等待所有依赖的map任务完成。这种优化提高了整体作业的效率,尤其是在大型数据处理中。
博客介绍了Hadoop MapReduce中如何实现map和reduce任务的重叠执行,特别是shuffle阶段的细节。在原始论文中,reduce工作在所有map完成后开始,但在Hadoop中,reduce的shuffle阶段可以提前启动,当map达到一定比例时就开始拉取数据,通过参数`mapreduce.reduce.shuffle.merge.percent`进行配置。然而,真正的reduce执行仍需等待所有依赖的map任务完成。这种优化提高了整体作业的效率,尤其是在大型数据处理中。
在mapreduce原始论文中,原型是等map worker运行完后,master再通知reduce worker去拉取数据,去运行。
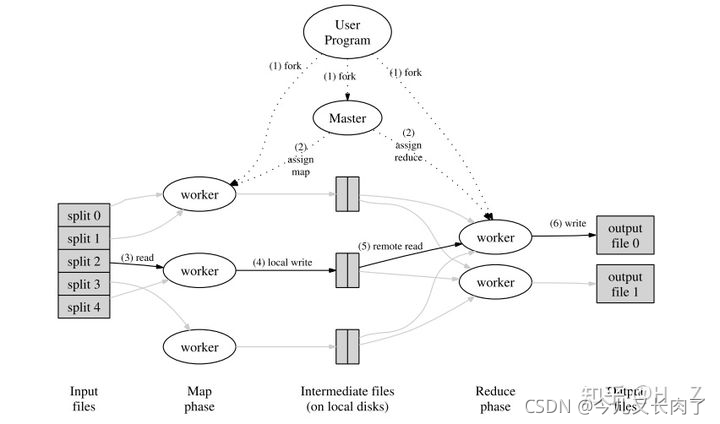
然而,在hadoop中,map-reduce阶段可以设置为重叠。也就是说,Reduce分为了两个阶段,一个是shuffle,一个是reduce。也就是分为从map那拉取数据,以及运行用户定义的reduce程序两个阶段。而我们所说的重叠,就是指reduce从map那拉取数据这个阶段。并且在同一个job中,reduce会等它所有分配的map执行完后才开始执行,map的输出是reduce的输入,但是reduce可以在map执行占比到某个阀值时就可以开始拷数据了,可以通过mapreduce.reduce.shuffle.merge.percent这个参数设置,具体可以看官网[1]说明。但真正的执行也得等拉取到所有依赖的map结果后才开始执行。不同的job中,互不影响都是可以并行的。
Hadoop中的reduce会等待所有mapper执行后才执行吗,还是会和mapper一起混合执行?
最新推荐文章于 2024-12-10 20:17:41 发布

















 4565
4565

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









