



一,指针
1.指针一
1)内存和地址
内存:
在讲内存之前,我先列举一个生活中的案例,就是道友们都会有点外卖的时候吧,但是你点外卖最重要的一个环节是填收货地址,比如xxx小区,xxx栋,xxx单元,xxx门牌号,不然骑手怎么能把你的外卖送到你手里,有了具体的地址,骑手就可以快速的找到你,把你的外卖送给你,如果我们把这个例子对照到计算机中,又是怎样的呢?
我们知道计算机CPU(中央处理器)在处理数据的时候,需要的数据是在内存中读取的,处理后的数据也会放回内存中,那么在我们买电脑的时候,电脑上的内存是8G/16G/32G等,有个问题就是我怎么知道CPU要处理的数据在哪一块内存中存放?那这么大的内存空间如何高效的去管理呢?
其实是把内存划分为一个个的内存单元,每个内存单元的大小取一个字节。
计算机中常见的单位:
一个比特位可以储存一个2进制的位1或者0
| bit - 比特位 1Byte = 8bit |
|
Byte - 字节 1KB = 1024Byte |
| KB 1MB = 1024KB |
| MB 1GB = 1024MB |
| GB 1TB = 1024GB |
| TB 1PB = 1024TB |
其中,每个内存单元,相当于一个学生宿舍,一个字节空间里面能放8个比特位,就好比一个宿舍是八人寝,每个人就是一个比特位。
当然,每个内存单元也都有一个编号(这个编号就相当于宿舍房间的门牌号),有了这个内存单元的编号,CPU就可以快速找到一个内存空间。
生活中我们把门牌号叫地址,在计算机中我们把内存单元的编号也叫地址,那么在C语言中,给地址起了一个新的名字叫:指针,所以我们可以理解为:内存单元的编号==地址==指针
2)指针变量和地址
取地址操作符(&):
在C语言中,创建变量的过程其实就是向内存申请空间,比如:
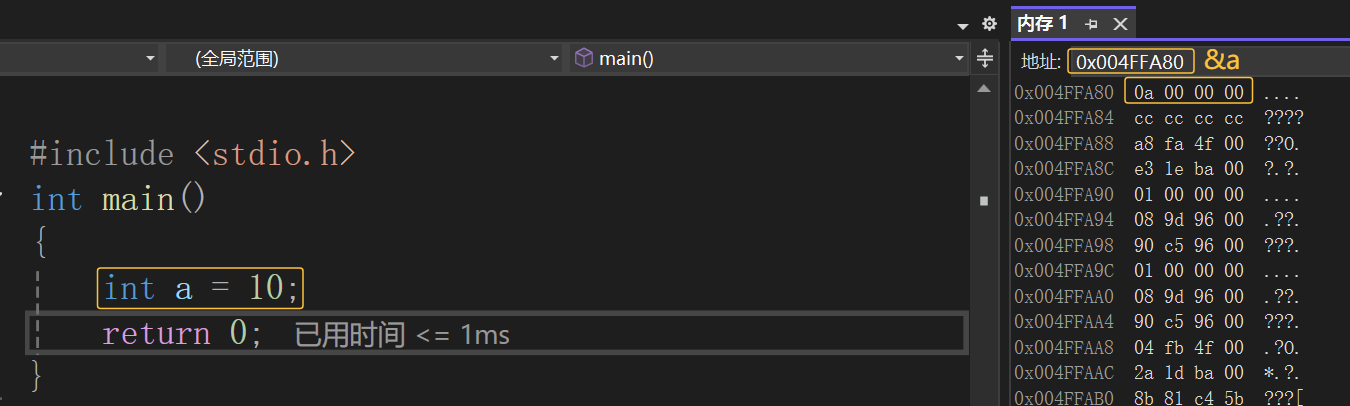
上述代码就是创建了整型变量a,内存中申请4个字节,用于存放整数10,有很多道友疑惑的点是为什么&a存放的是0a 00 00 00,是因为1个16进制位对应4个2进制位,那么16进制中的10转换成对应的2进制就是0000 0000 0000 0000 0000 0000 0000 1010对应的16进制就是00 00 00 0a,倒过来存放就是0a 00 00 00
上面只是在内存中观察了a的地址,那么如何得到a的地址呢?
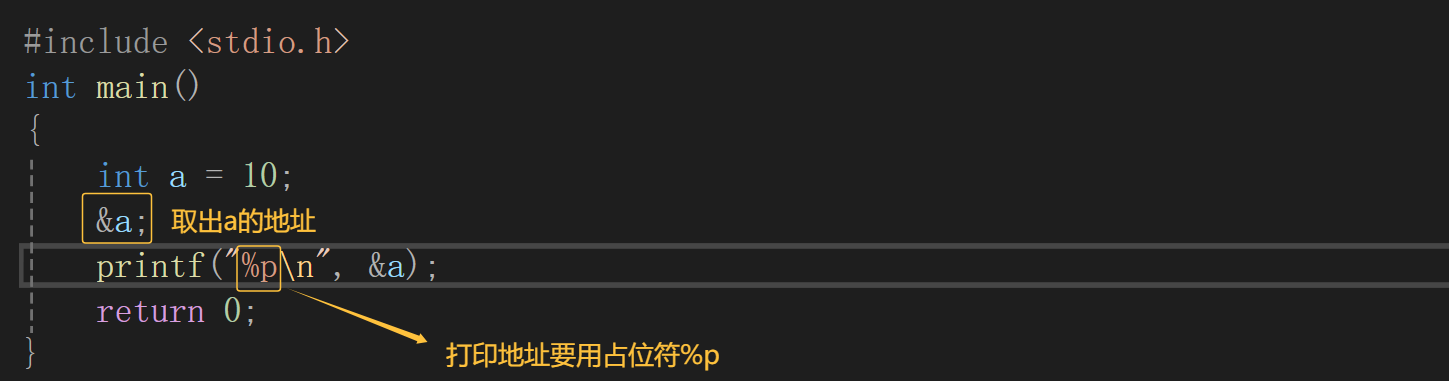
这样就能得到a的地址。
指针变量:
那我们通过取地址操作符(&)拿到的地址是一个数值,比如0x004DD5F6,这个数值有时候也需要存储起来,方便后期再使用的,那我们把这样的地址存放在哪里呢?答案是:指针变量中
#inclued <stdio.h>
int main()
{
int a = 10;
int * pa = &a;//取出a的地址并存储到指针变量pa中
return 0;
}
指针变量也是变量。这种变量就是用来存放地址的,存放在指针变量中的值都会理解为地址
如何拆解指针类型:
我们看到pa的类型是int *,我们该如何理解指针的类型呢?
int a = 10;
int * pa = &a;
这里pa的左边写的是int *,*是在说明pa是指针变量,而前面的int是在说明pa指向的是整型(int)类型的对象
那如果有一个char类型的变量ch,ch的变量要放在什么类型的指针变量中呢?
char ch = 'c';
char * pc = &ch;
解引用操作符(*):
我们将地址存起来,之后是要使用的,那怎么使用呢?
在现实生活中,比如说我们使用地址找到一个房间,在这个房间里可以拿去或者存放物品,那么在C语言中也是一样的,我们只要拿到了地址(指针),就可以通过地址(指针)找到地址(指针)指向的对象,那么就要用到解引用操作符(*)。
#include <stdio.h>
int main()
{
int a = 10;
int* pa = &a;
*pa = 0; //这段代码就使用了解引用操作符
return 0;
}
*pa的意思就是通过pa中存放的地址,找到指向空间,*pa其实就是a变量了,所以*pa = 0;这个操作符是把a改成了0,相当于a = 0,也就是说*pa是等价于a的。
各位道友会不会觉得这样有点麻烦,我为啥不直接改a的值,直接写a = 0;不就完了,还要绕个弯用指针来改a的值,其实这里是把a的修改交给了pa来操作,这样对a的修改,就多了一种途径,写代码就会更加灵活,后期就会慢慢了解了。
那我给大家举个例子,会更好理解一下,为啥不直接改a的值,还要绕个弯用指针来改a的值,想必各位道友都看过狂飙这个电视剧吧,里面有个大佬是强哥,他有一个得力干将是老默,那你不可能所有的事情都交给强哥去处理吧,那强哥都能处理的话,他还要小弟干什么对吧,比如说强哥想要干一件事,但他不方便出手,他就会说,老默我想吃鱼了,这时候老默就会去干这件事,这样的话,会不会更好的去理解呢?
指针变量的大小:
指针变量的大小取决于地址的大小,32位平台下的地址是32个bit位(4个字节),64位平台下的地址是64个bit位(8个字节):
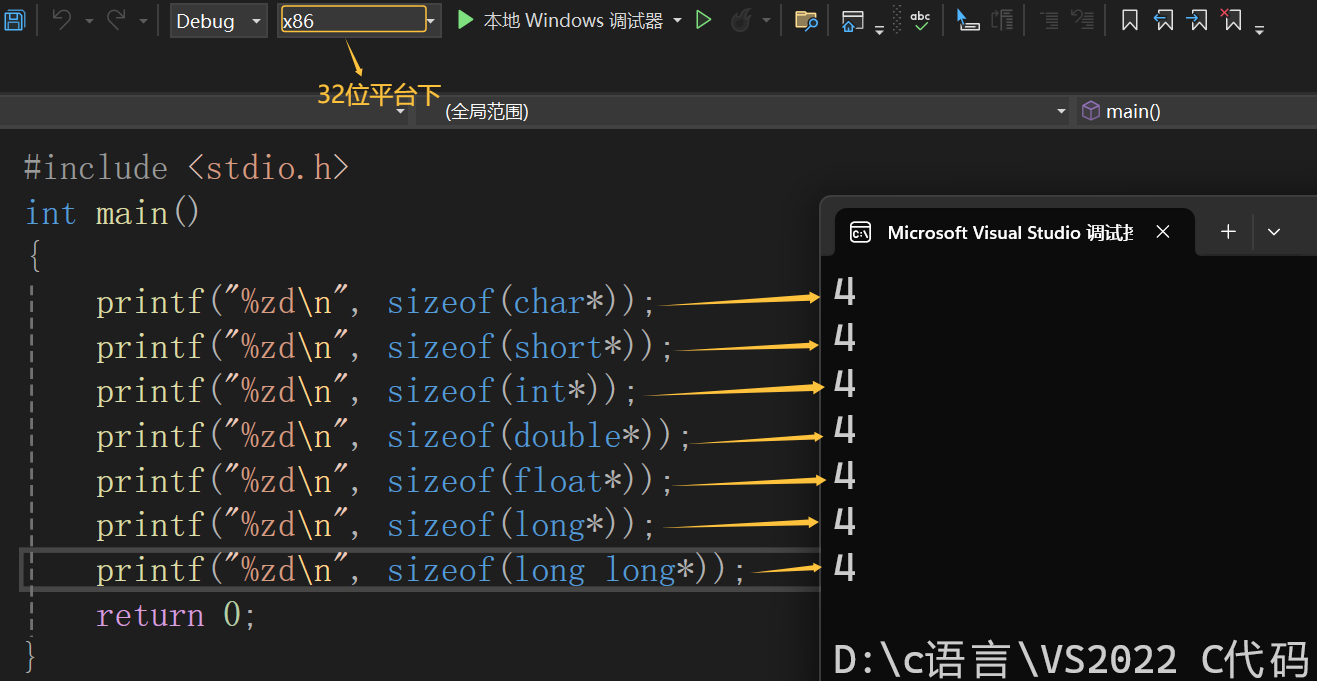
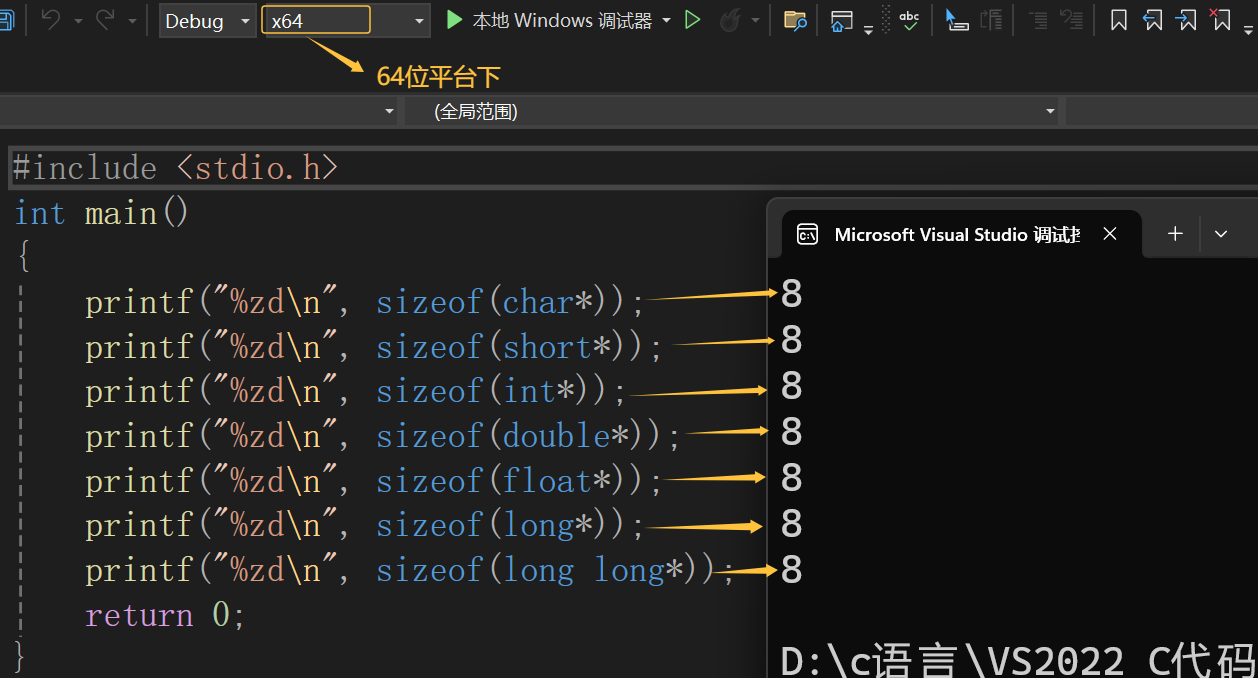
注意的是:指针变量的大小与类型是无关的,只要是指针类型的变量,在相同的平台下,大小都是相同的。
3)指针变量类型的意义
上面说到,指针变量的大小与类型是无关的,只要是指针类型的变量,在相同的平台下,大小都是相同的,那么为什么还要有各种各样的指针类型呢?
其实指针类型是有特殊意义的,我通过下面两段代码来进行解释:
代码1:
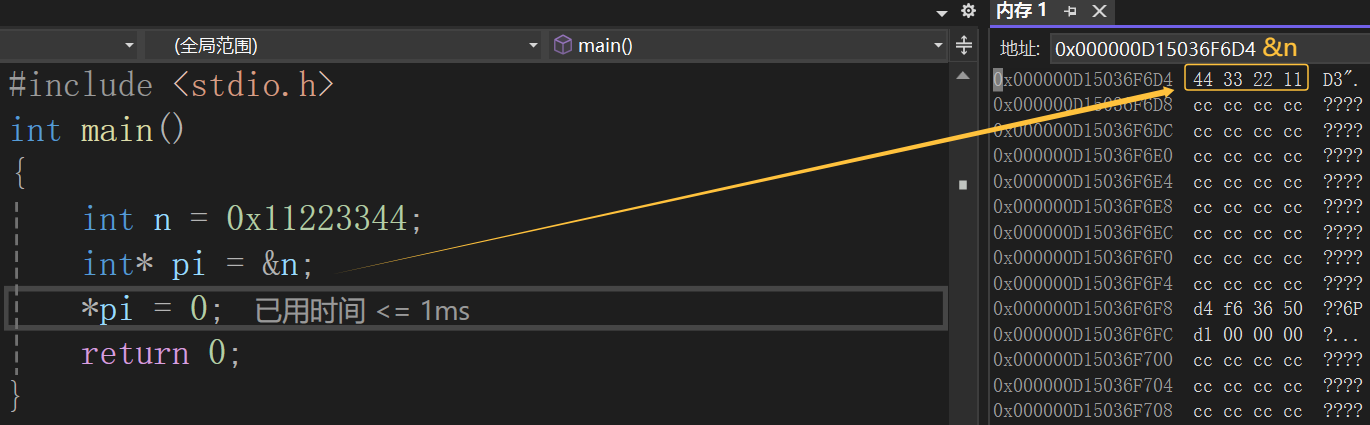
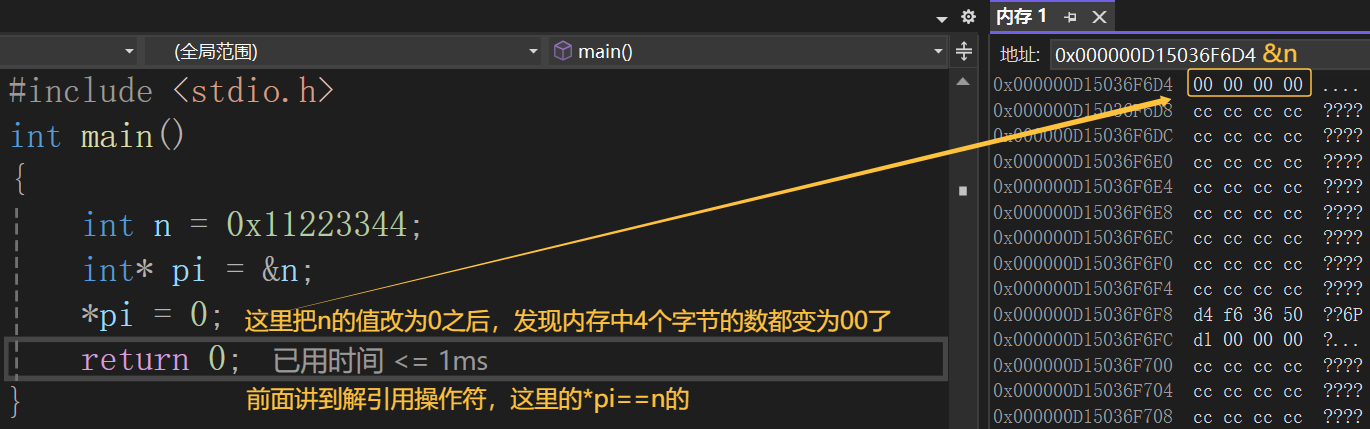
代码2:
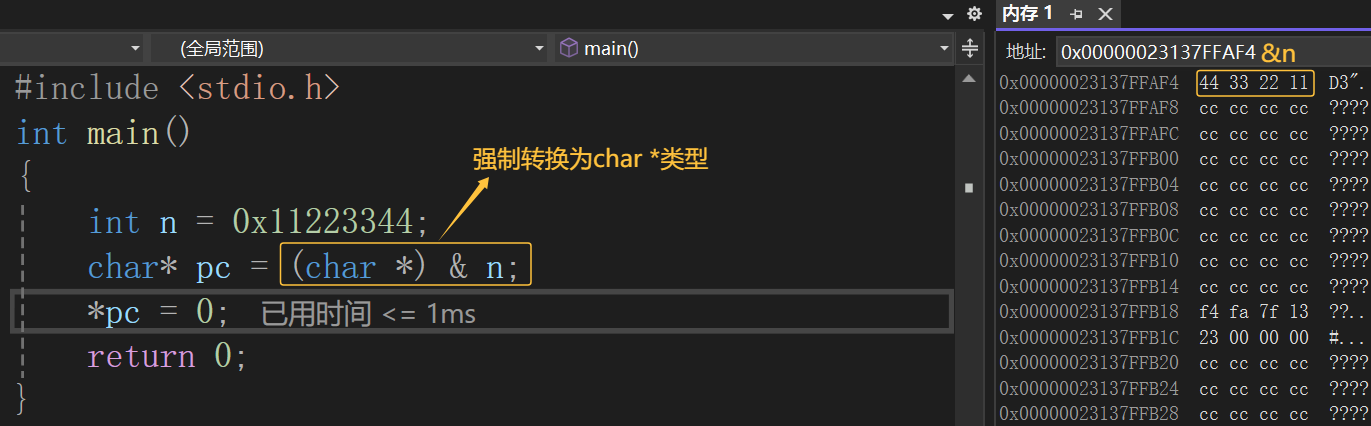
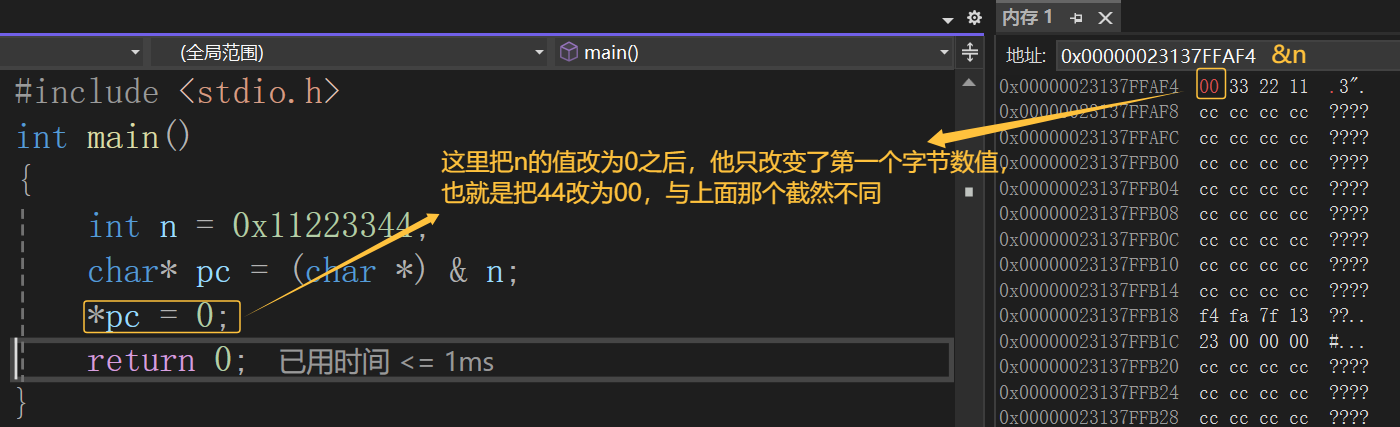
对上面两个代码调试之后,我们可以看到,代码1会将n的4个字节全部改为0,但是代码2只是将n的第一个字节改为0,所以我们得到的结论是:指针的类型决定了,对指针解引用的时候有多大的权限(也就是一次能操作几个字节)
比如:cahr*的指针解引用就只能访问一个字节,而int*的指针的解引用就能访问四个字节。
指针 + - 整数:
通过一段代码,调试观察地址的变化:
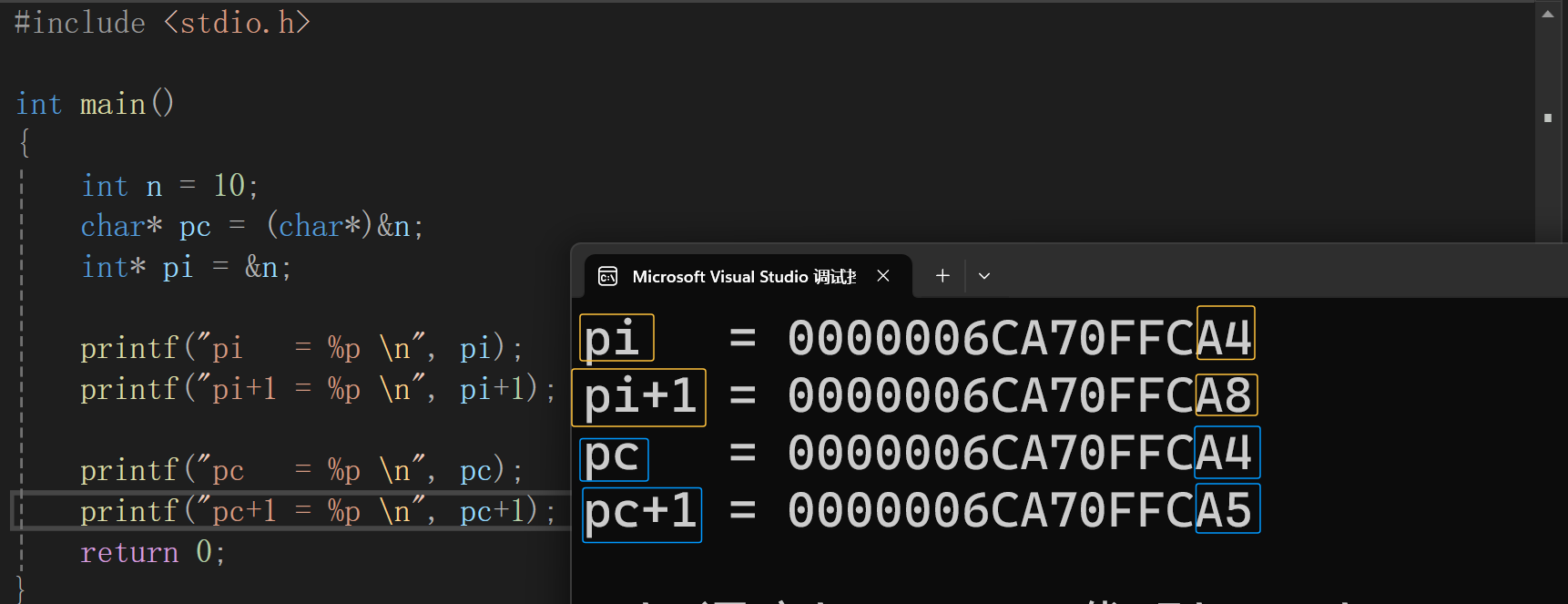
我们可以看出,char*类型的指针变量+1跳过1个字节,int*类型的指针变量+1跳过了4个字节,这就是指针变量的类型差异带来的变化。
void*指针:
在指针类型中有一种特殊的类型是void*类型的,可以理解为无具体类型的指针(或者叫泛型指针),这种类型的指针可以用来接受任意类型地址,但是也有局限性,void*类型的指针不能直接进行指针的+ - 整数和解引用的运算。
使用void*类型的指针接受指针地址:
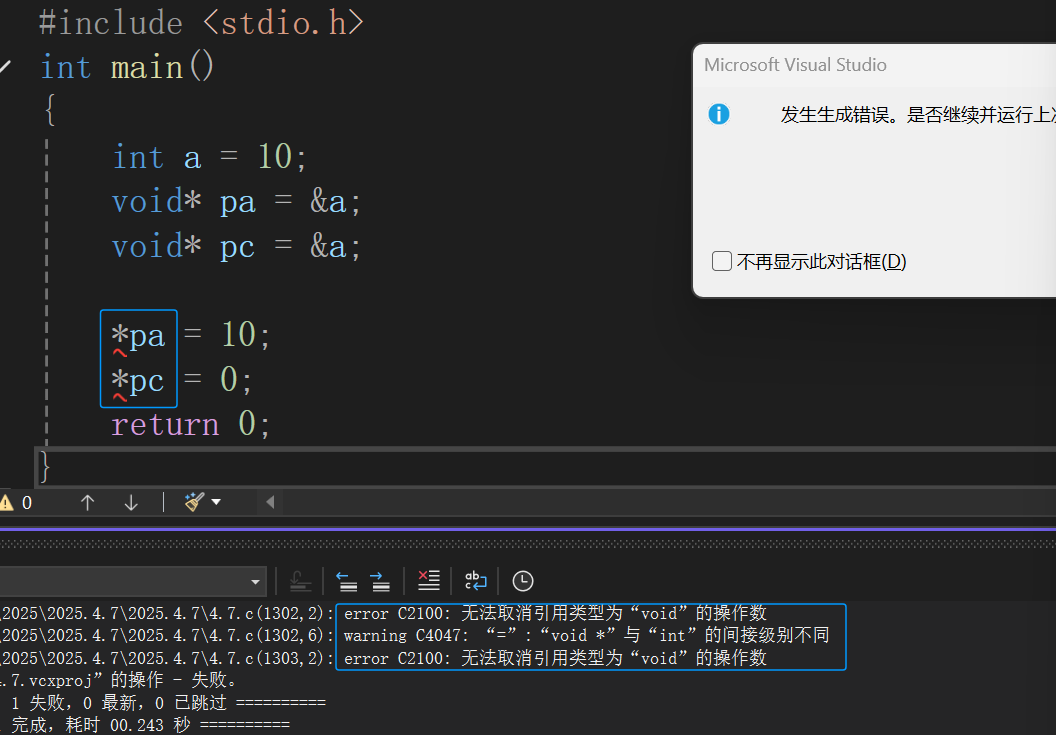
这里我们就可以看到,void*类型的指针可以接受不同类型的地址,但是无法直接进行指针运算。那么void*类型指针到底有什么作用呢?
一般void*类型的指针是使用在函数参数部分,用来接收不同类型数据的地址,这样设计可以实现泛型编程的效果,使得一个函数来处理多种类型的数据,这里先简单铺垫一下void*指针这个概念,后面会详细讲解。
4)指针运算
指针的基本运算有三种,分别是:
- 指针 + - 整数:
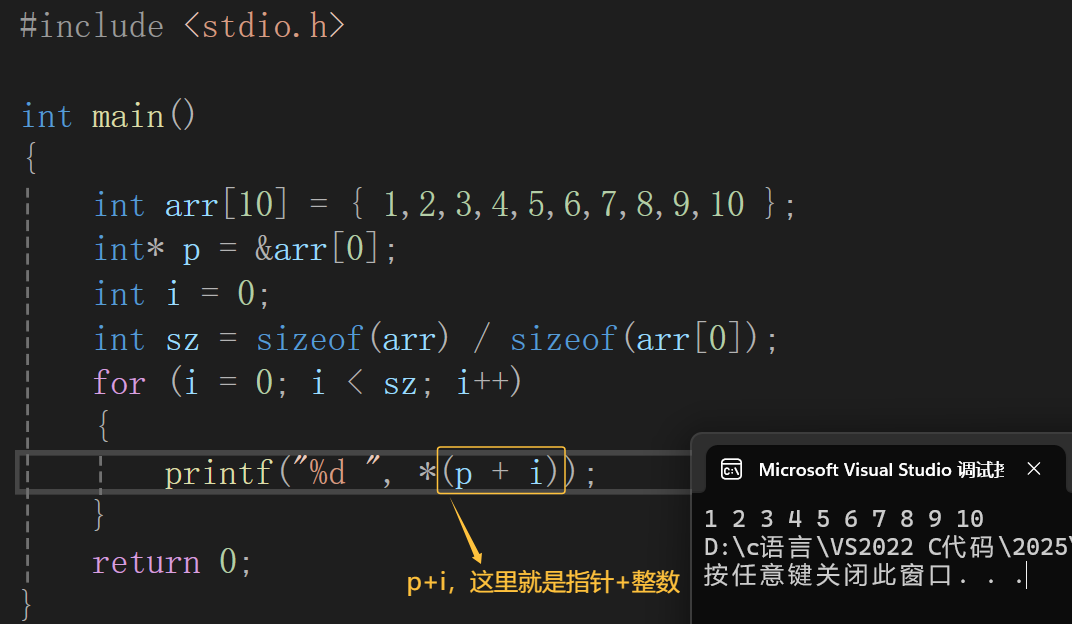
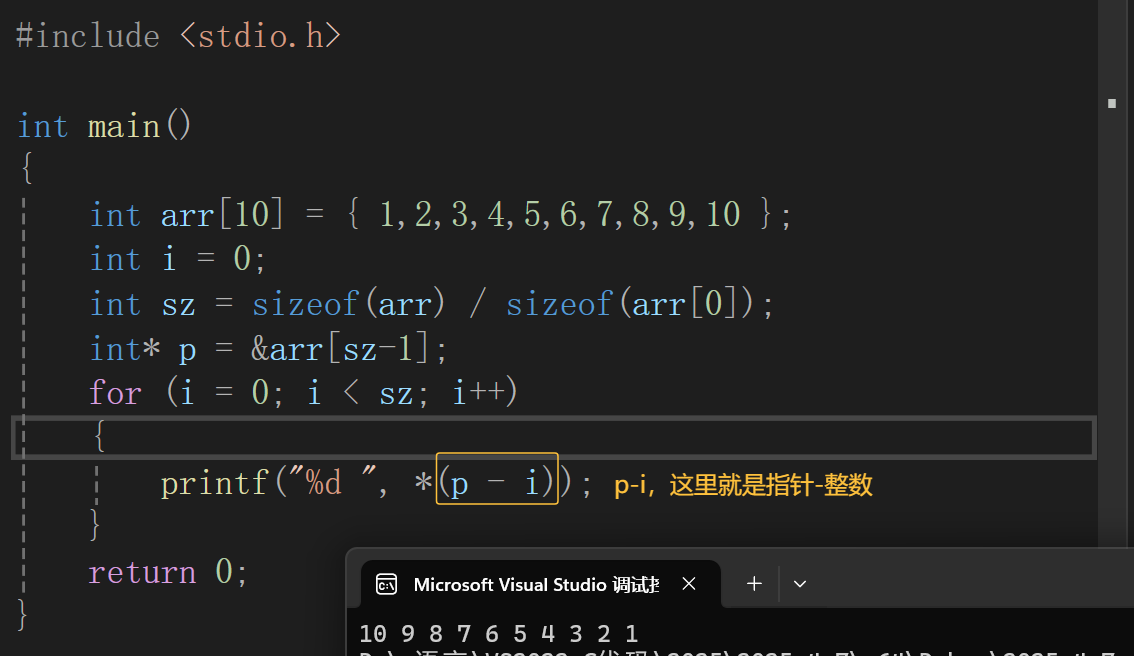
通过这两个代码想必各位道友也理解了指针+ - 整数的运算。
- 指针 - 指针:(前提是两个指针指向了同一块空间,否则不能相减)

从这个代码中,可以得出一个结论是:|指针-指针|(指针-指针的绝对值):得到的是两个指针之间的元素个数。
通过一个练习题:写一个函数,求字符串的长度:
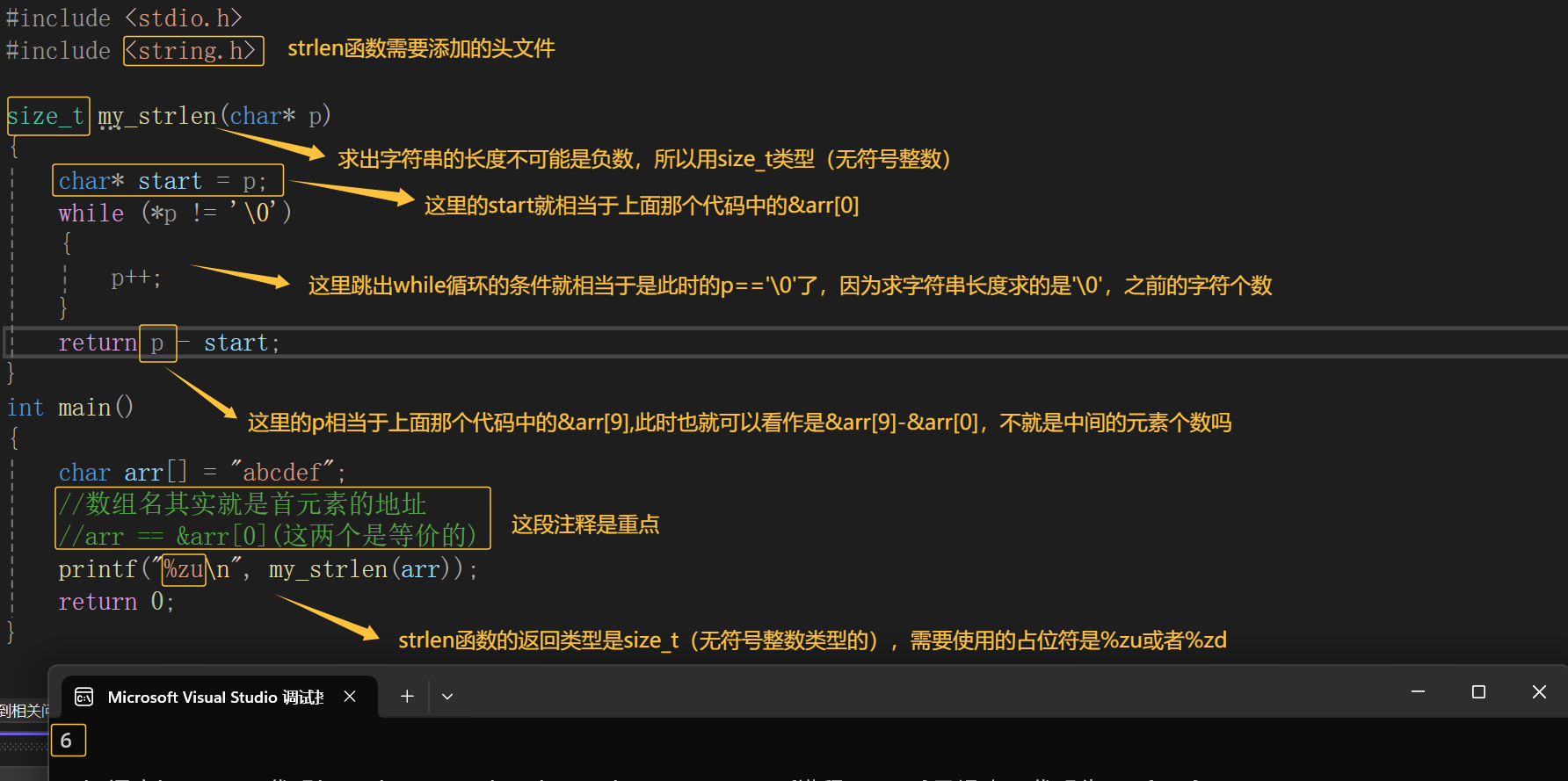
当然,这个自定义函数里的代码逻辑也可以使用指针+ - 整数运算去完成,也会更好理解,道友们可以试着编写一下代码哈,但我这里也是为了讲指针-指针运算,那么此时我也相信各位道友理解了指针-指针的运算。
- 指针的关系运算:
还是通过一段代码来讲解,我们来看一下哈:
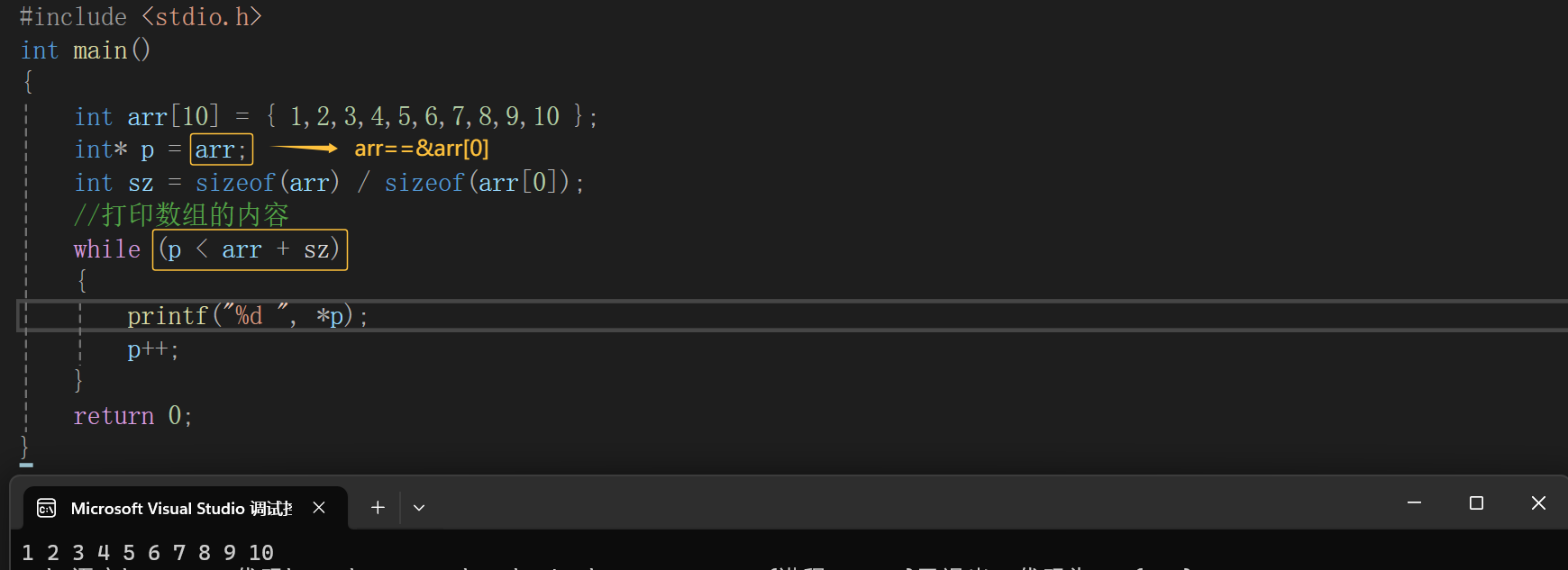
代码中p<arr+sz,就是指针大小的比较。
5)const修饰指针
const修饰变量:
变量是可以修改的,如果把变量的地址交给一个指针变量,通过对指针变量解引用也可以修改这个变量,但是如果我们希望一个变量加上一些限制,不能被修改,这时候就要用到const这个关键字了。
#include <stdio.h>
int main()
{
int m = 0;
m = 20; //这里的m是可以修改的
const int n = 0;
n = 10; //这里的n就不能被修改了
return 0;
}
上面这个代码中的n是不能被修改的,其实n的本质是变量,只不过被const修饰后,在语法上加了限制,只要我们在代码中对n进行修改,就不符合语法规则,编译器就会报错,致使没法直接修改n。
但是我们如果绕过n,使用n的地址,去修改n就能做到了,虽然这样是在打破语法规则。
#include <stdio.h>
int main()
{
const int n =0;
int* p = &n;
*p = 20; //这样就可以对n进行修改了
return 0;
}
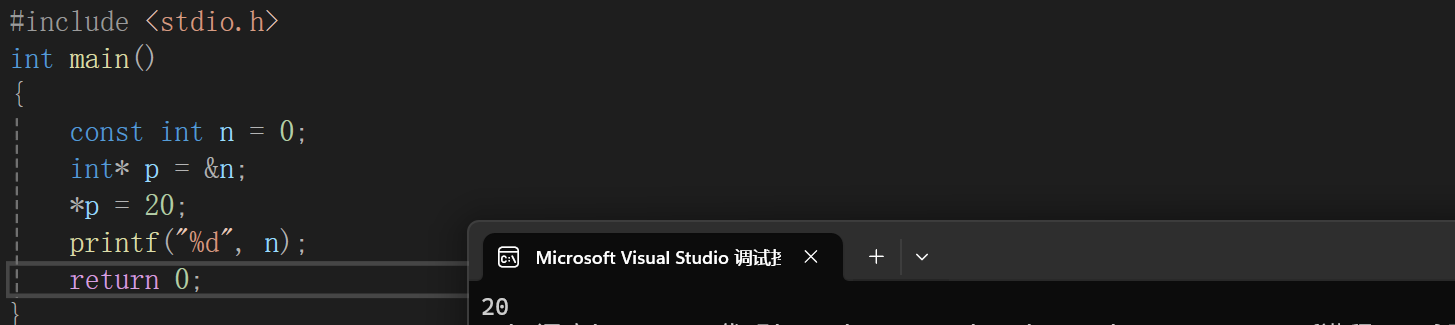 这里的n确实被修改了,但是我们要清楚为什么要让n被const修饰呢?目的就是为了让n不能被修改,如果p拿到n的地址就能修改n,这样就打破了const的的限制,这是不合理的,所以应该让p拿到了n的地址也不能修改n,那要怎么做呢?我们就要讲到const修饰指针变量
这里的n确实被修改了,但是我们要清楚为什么要让n被const修饰呢?目的就是为了让n不能被修改,如果p拿到n的地址就能修改n,这样就打破了const的的限制,这是不合理的,所以应该让p拿到了n的地址也不能修改n,那要怎么做呢?我们就要讲到const修饰指针变量
const修饰指针变量:
const修饰指针变量,有两种情况,一种是放在*的左边,另一种是放在*的右边,意义是不一样的。
int* p; //没有const修饰
const int* p;或者int const* p;(这两种是一样的) //const放在*左边做修饰
int* const p; //const放在*右边做修饰
我们看下面代码来具体分析:

这段代码我是把const放在*左边,我来把代码解读一下,首先,pa是一个指针变量,pa中目前存放的是a的地址,但是pa也可以存放其他变量的地址,比如我存放了b的地址,这是没有问题的,但是此时发现a的值是修改不了的,说明const放在*左边修饰的是* pa,但不会限制pa。
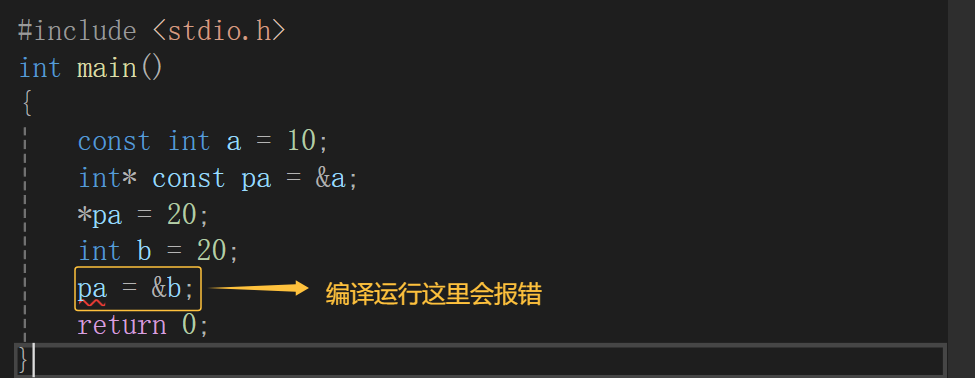
而这段代码我是把const放在*右边,与上面不同的是,此时,a的值可以修改了,但是pa不可以存放其他变量的地址了,说明const放在*右边修饰的是pa,但不会限制* pa。
那如果既不想让pa被修改,也不想让* pa被修改,就需要在*左右两边都加const修饰,如下:
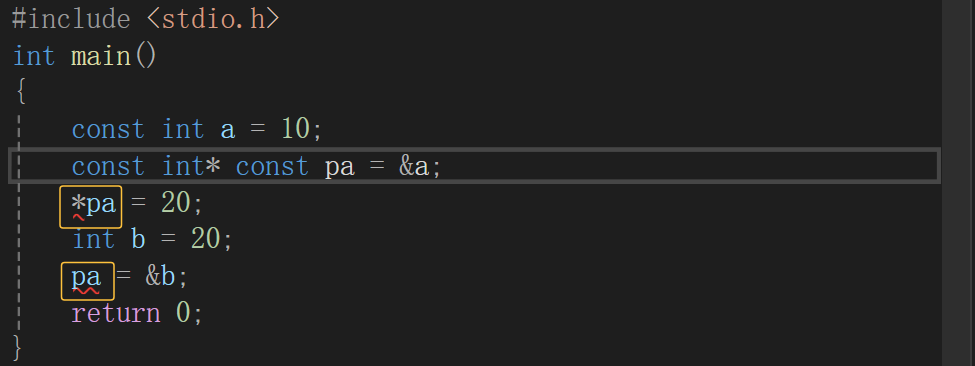
这就是const修饰指针变量,也相信道友们可以理解了哈。
6)野指针
什么是野指针呢?野指针就是指针指向的位置是不可知的(随机的,不正确的,没有明确限制的),也就是说,指针指向的空间是不属于当前程序的。
野指针成因:
- 指针未初始化:
#include <stdio.h>
int main()
{
int* p; //局部变量指针未初始化,默认为随机值
*p = 20;
return 0;
}
pa是一个局部变量,局部变量不初始化,他里边存放的是一个随机值,那么既然我们不知道pa里面存放的是什么值,我们对pa里面存放的地址解引用一下想找到它这样的一个空间,那么*pa具体找到的空间一定是属于pa的吗?不一定吧,所以说,指针未初始化就会造成野指针。
- 指针越界访问:
#include <stdio.h>
int main()
{
int arr[10] = {0};
int* p = &arr[0];
int i = 0;
int sz = sizeof(arr)/sizeof(arr[0]);
for(i = 0; i<=sz; i++)
{
//当前指针指向的范围超出数组arr的范围时,p就是野指针
printf("%d ",*p);
p++;
}
return 0;
}
arr数组的大小是10,for循环中的i是从0开始的,i<=10;相当于是循环了11次,而arr数组中只有10个元素,这样的话就造成了指针越界访问。
- 指针指向的空间释放
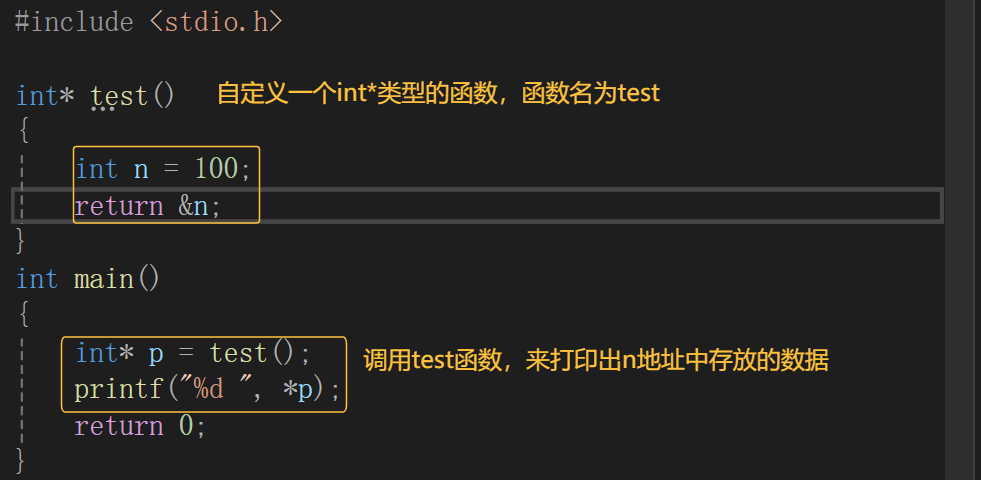
这样也会造成野指针,原因是n是test函数中的一个局部变量,它出了test函数范围它的生命周期也就结束了,但是它的地址还是存在的,但它地址中存放的数据被销毁了,尽管在main函数中调用这个函数可以找到n的地址,但是n地址里面的数据已经被销毁了。
就相当于你在图书馆里面借了一本书,然后有一天你用完这本书了,你就去把它归还给图书馆了,但是你的好朋友也想看这本书,于是它就去图书馆借了,但是这本书已经被其他人借走了,他就没有借到这本书。
但是有道友好奇说这个代码运行之后会不会是100呢,那我就运行一下,来看结果:
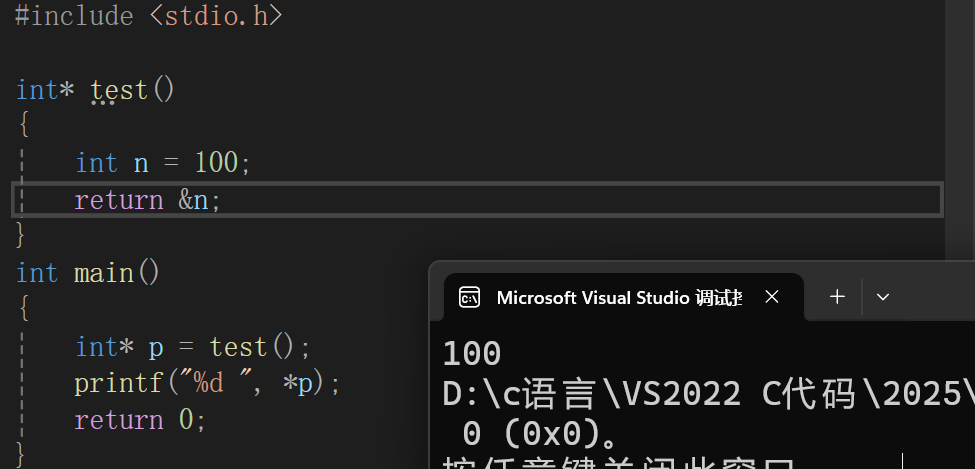
发现运行之后确实是100,原因就是这是一个巧合,就还是上面那个例子,你的好朋友去图书馆要是借到你说的那本书了,说明你归还完这本书之后,在你好朋友去借这本书期间,它没有被人借走,就是这本书还在图书馆。
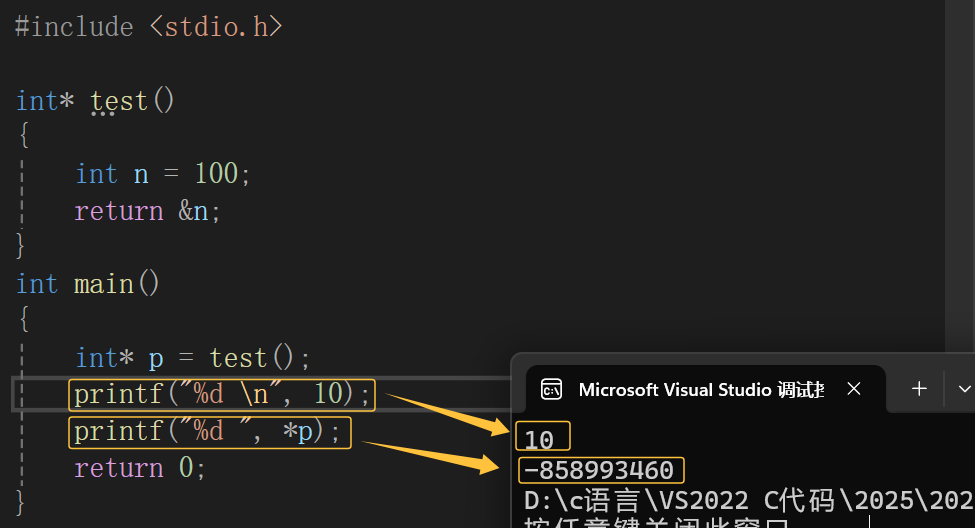 所以说就是一个巧合哈,n地址里存放的100确实被销毁了,这里它就是一个随机值。
所以说就是一个巧合哈,n地址里存放的100确实被销毁了,这里它就是一个随机值。
那如果就想要找到这个n地址中的数据呢?也就是100,前一篇文章中讲过哈,用static修饰一下变量n就好,这里就不多说了哈。
当然野指针成因还有很多,我就不一一列举了哈,各位道友可以自己探索一番。
如何规避野指针呢?
我们可以把野指针当作一条疯狗,各位道友觉得疯狗危险吗?如果一只疯狗在大街上,要是它乱咬人怎么办?这样是不是就很危险,一但指针变成了野指针,对程序也有较大的风险,所以我们在使用指针的时候就要避免野指针。
- 指针要初始化
如果明确知道指针指向哪里就直接赋值地址,如果不知道指针指向哪里,可以给指针赋值NULL,NULL是C语言中定义的一个标识符常量,值是0,0也是地址,但是这个地址是无法使用的,读写该地址就会报错。
#include <stdio.h>
int main()
{
int num = 10;
int* p1 = num;
int* p2 = NULL;
return 0
}
这就是指针的初始化。
- 防止指针越界
#include <stdio.h>
int main()
{
int arr[10] = {0};
int* p = &arr[0];
int i = 0;
int sz = sizeof(arr)/sizeof(arr[0]);
for(i = 0; i<sz; i++)
{
//当前指针指向的范围超出数组arr的范围时,p就是野指针
printf("%d ",*p);
p++;
}
return 0;
}
这就是上边那个代码,把for循环中的 i <= sz;改为 i < sz;防止它越界就避免了指针越界访问。
- 指针变量不再使用时,及时置NULL,指针使用之前检查有效性
当指针变量指向一块区域的时候,我们可以通过指针访问该区域,后期不再使用这个指针访问空间的时候,我们可以把该指针置为NULL。
上面说到,我们可以把野指针当作是一条疯狗,疯狗放任不管是很危险的,所以我们就可以找一棵树给它拴起来,就相对安全了,给指针变量即使赋值为NULL,其实就是类似把疯狗拴起来,但即使我们把疯狗拴起来,也要绕着它走,不要去挑逗它,会比较危险,对于指针也是,在使用之前,我们也要判断是否为NULL,如果不是我们再去使用。
#include <stdio.h>
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int *p = &arr[0];
int i = 0;
for(i=0; i<10; i++)
{
*(p++) = i;
}
//此时p已经越界了,可以把p置为NULL
p = NULL;
//下次使⽤的时候,判断p不为NULL的时候再使⽤
p = &arr[0]; //重新让p获得地址
if(p != NULL) //判断
{
//...
}
return 0;
}
7)assert断言
assert.h头文件中定义了宏assert(),用于在运行时确保程序符合指定条件,如果不符合,就报错终止运行,这个宏常常被称为“断言”。
aeesrt(p != NULL);
如果程序中写了这一句代码,那么程序在运行到这一语句时,就会验证指针变量是否等于NULL,如果确实不等于NULL,程序就会继续运行,否则就会终止运行,并且给出报错信息提示。
assert() 的使用对程序员是非常友好的,使用assert() 有几个好处:它不仅能自动标识文件和 出问题的行号,还有一种无需更改代码就能开启或关闭 assert() 的机制。如果已经确认程序没有问 题,不需要再做断言,就在 #include <assert.h> 语句的前面,定义一个宏 NDEBUG 。
#define NDEBUG
#include <assert.h>
然后,重新编译程序,编译器就会禁用文件中所有的assert()语句,如果程序由出了问题,可以移除这条 #define NDEBUG指令,或者把他注释掉,再次编译,这样就重新启用了assert()语句。
8)指针的传值调用和传址调用
我们学习指针的目的就是用指针解决问题,那什么问题,非指针不可呢?
例如:写一个函数,交换两个整型变量的值:
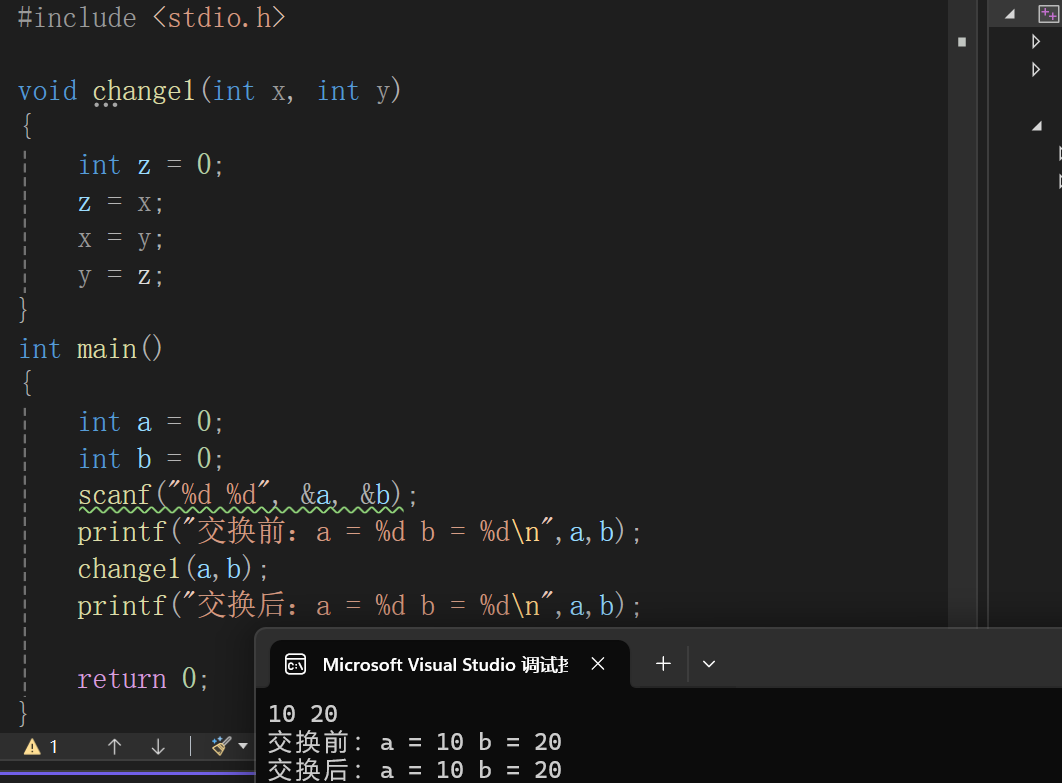
发现没有实现两个数的交换,但是代码逻辑是没有问题的,我们通过调试一下来看看:
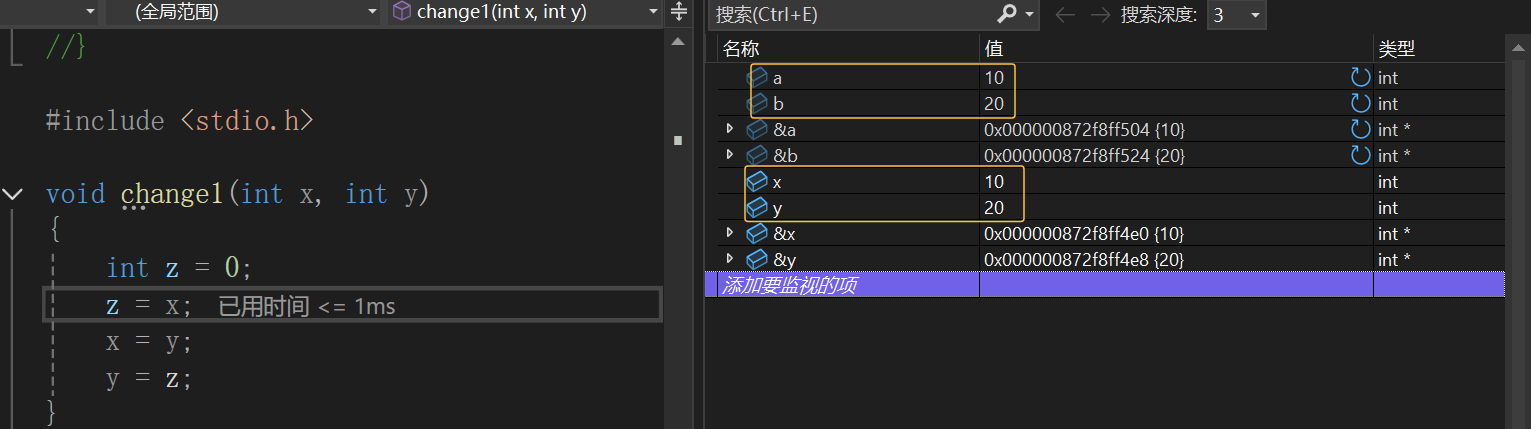
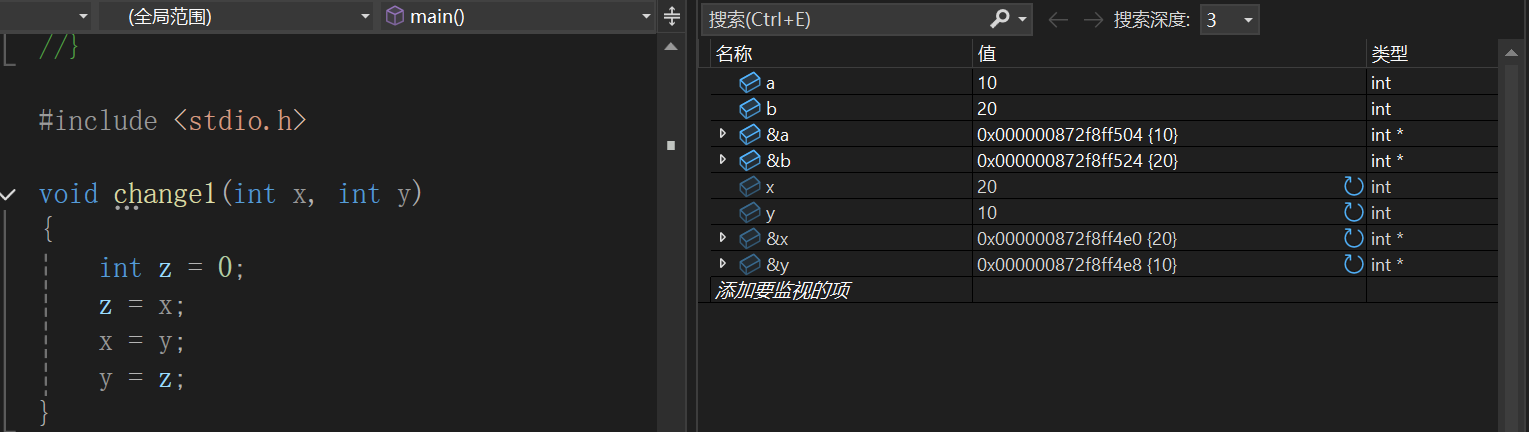
发先x和y的值确实交换了,但是a和b的值没有交换,说明main函数内部确实把实参a和b传给了change1函数,在change1函数中的形参x和y确实接受了a和b的值,但是发现形参x和y的地址与实参a和b的地址是不一样的,相当于x和y是独立的空间,那么在change1函数中交换x和y的值,自然不会影响a和b,我们前面文章也说到过,形参是实参的一份临时拷贝,就相当于你有一份文件(实参),你把他拷贝到了U盘里,那你把这个拷贝的文件(形参)进行修改,那你原来文件是不会被修改的。所以要想实现写一个函数交换两个数的值,我们就要把地址给传过去,这样形参中接收到的地址就和实参是一样的地址,那么地址都一样了,我再去修改是不是就都修改了。
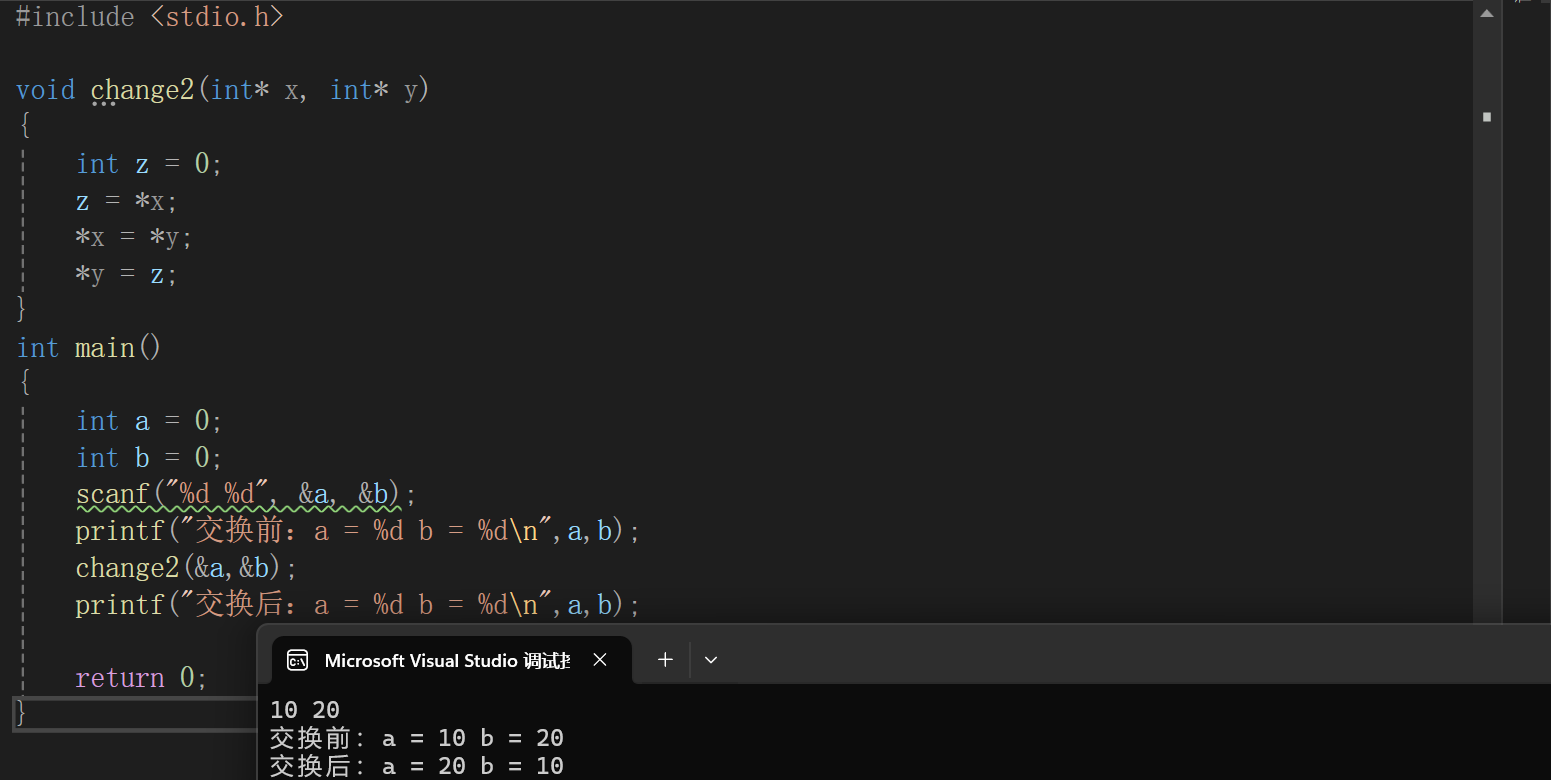
这就是指针的传值调用和传址调用,也相信各位道友都理解了。
2.指针二
1)数组名的理解
数组名的理解:
在指针一中有这样一段代码:
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int* p = &arr[0];
这里我们使用&arr[0]的方式拿到了数组第一个元素的地址,但是我也说过arr(数组名)本来就是地址,而且是首元素的地址,也就是arr == &arr[0];,我们来做个测试:
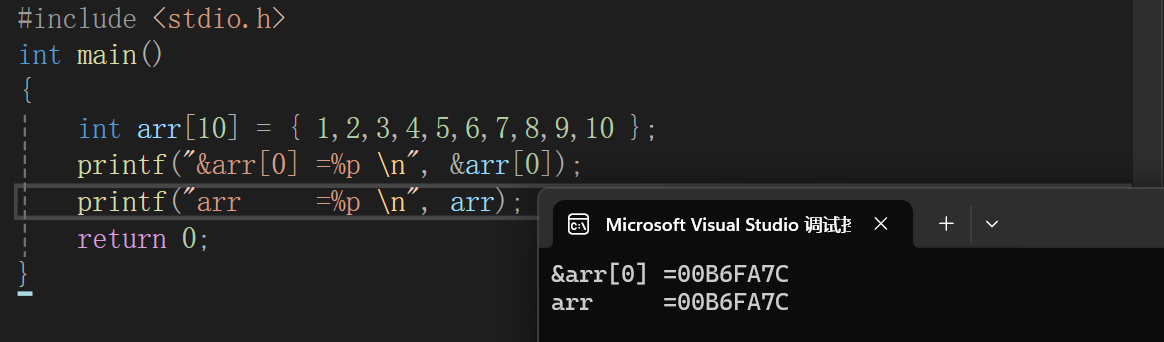
得出的结论是数组名和数组首元素的地址打印出来的结果是一样的,也就是说数组名就是数组首元素的地址。
那我们再看一段代码:
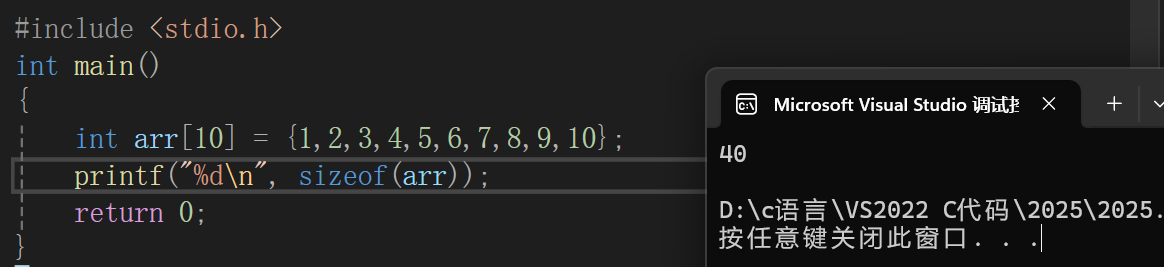
如果arr(数组名)是首元素的地址,那这个值输出结果就是4或者8,指针大小在x64环境下是8个字节,在x86环境下是4个字节,那么为什么打印出来的结果是40呢?
其实数组名就是首元素的地址这句话是没问题的,但是有两个例外:
- sizeof(数组名),sizeof中单独放数组名,这里的数组名表示整个数组,计算的是整个数组的大小,单位是字节
- &数组名,这里的数组名表示整个数组,取出的是整个数组的地址(整个数组的地址和首元素的地址是有区别的)
除此之外,任何地方使用数组名,数组名都表示首元素的地址,我们再看一段代码:
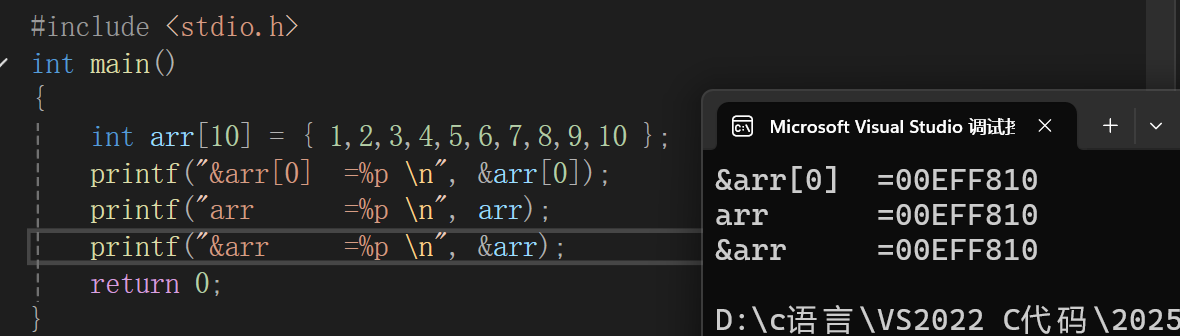
发现三个打印结果是一样的,那么arr和&arr有什么区别呢?
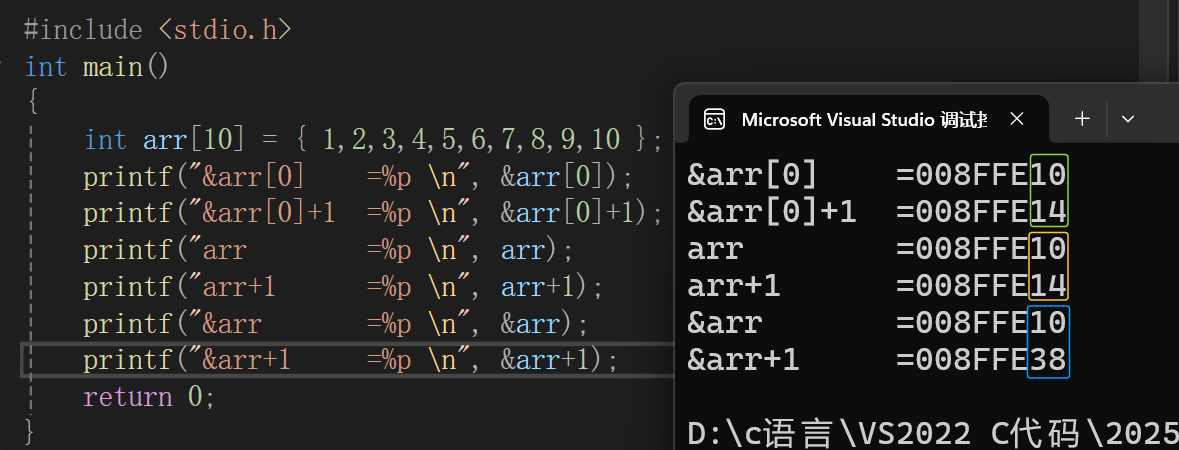
发现&arr[0]和&arr[0]+1相差4个字节,arr和arr+1相差4个字节,因为它们两个都是首元素的地址,+1就是跳过一个元素。
但是&arr和&arr+1相差40个字节,这就是因为&arr是数组的地址,+1就是跳过整个数组的,10变化到38,有道友说这不是差了28吗,怎么就成差了40个字节,因为地址的打印是以16进制形式进行打印的,16进制的28转换成10进制就是40。

2)一维数组传参的本质
数组是可以传递给函数的,我们之前计算数组元素个数都是在函数外部来计算的,那么我们可以把数组传给一个函数后,在函数内部求数组元素个数吗?
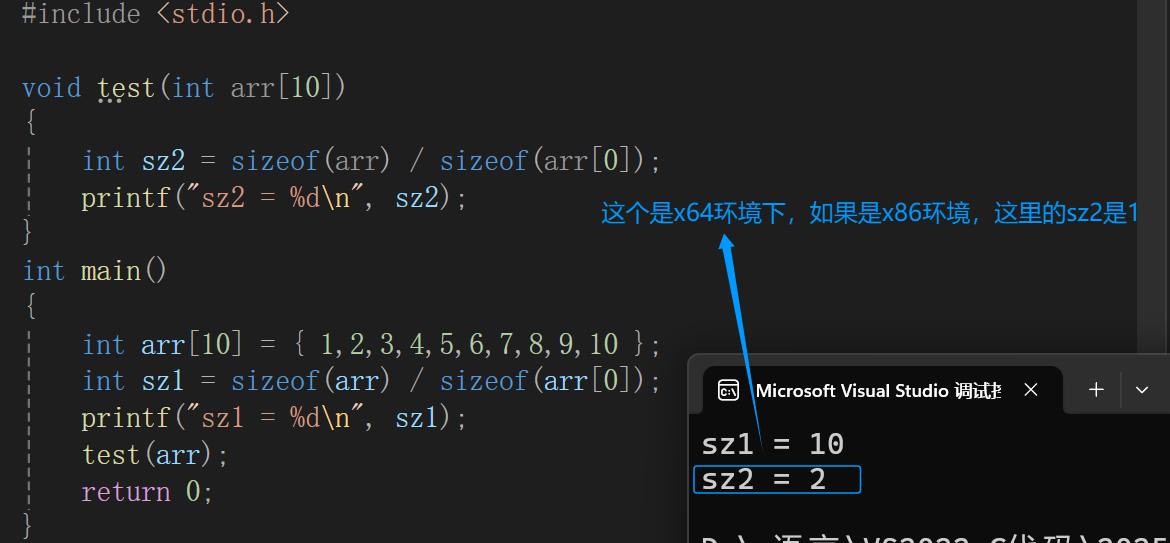
发现在函数内部是没有正确获得数组的元素个数,是因为一维数组传参的本质是:传递的是数组首元素的地址,所以在函数内部写sizeof(arr)计算的是一个地址的大小(单位字节)而不是数组的大小(单位字节),正是因为函数的参数部分本质是指针,所以在函数内部是没有办法求数组的元素个数的。
所以在一维数组传参的时候,形参部分可以写成数组形式,也可以写成指针的形式,如下:
void test(int arr[ ]) //数组形式
{
//..........
}
void test(int* arr) //指针形式
{
//...........
}
//但是写成数组的形式我们要知道它这里其实本质上是指针
3)冒泡排序
冒泡排序:核心思想就是两两相邻元素进行比较
例如:把数组内的n个元素从小到大依次打印出来
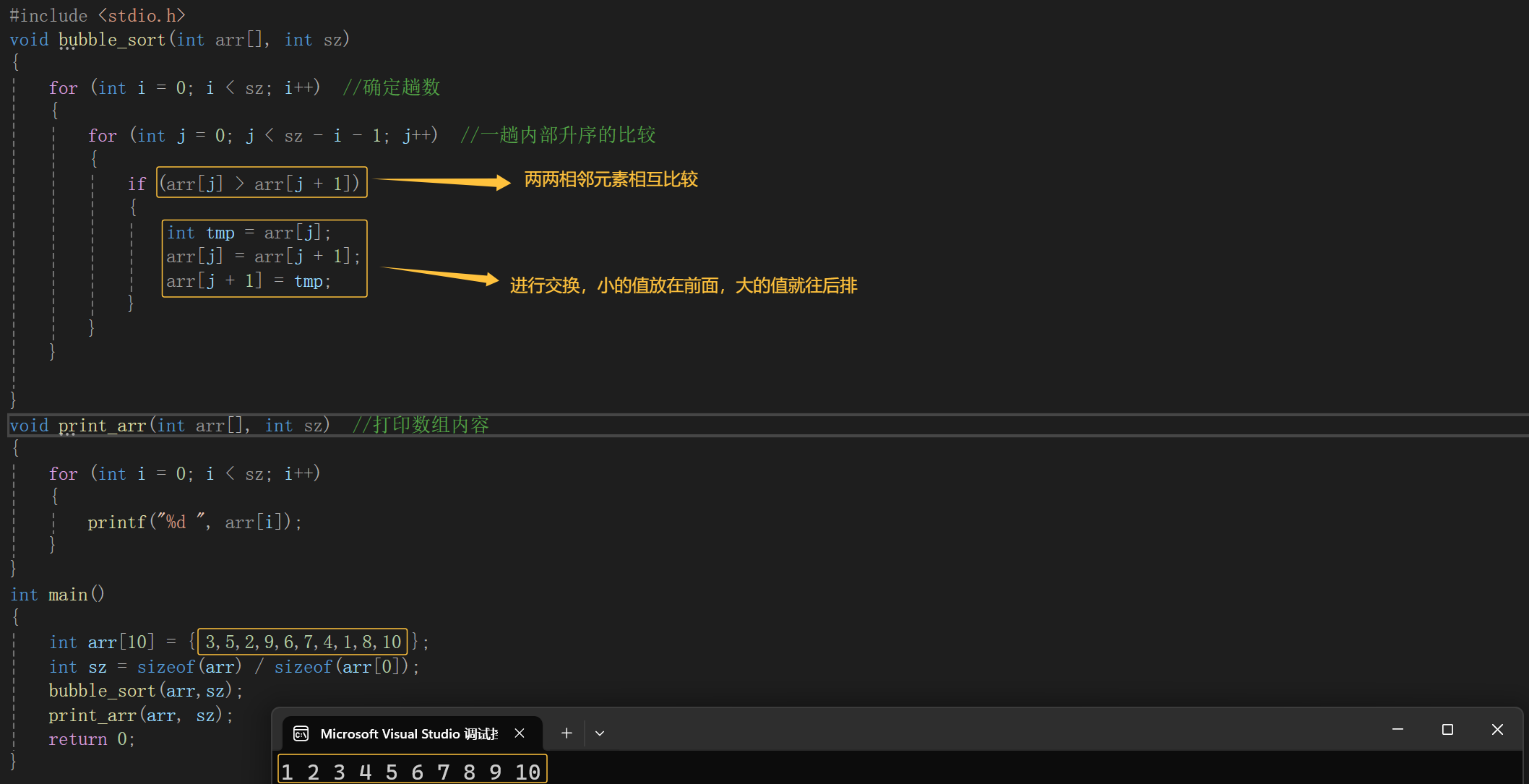
这样就把一个数组内的数据从小到大依次打印出来,那么也可以从大到小打印哈,用的就是冒泡排序,但是这个代码还可以进行优化,那我们来看一下优化后的代码:
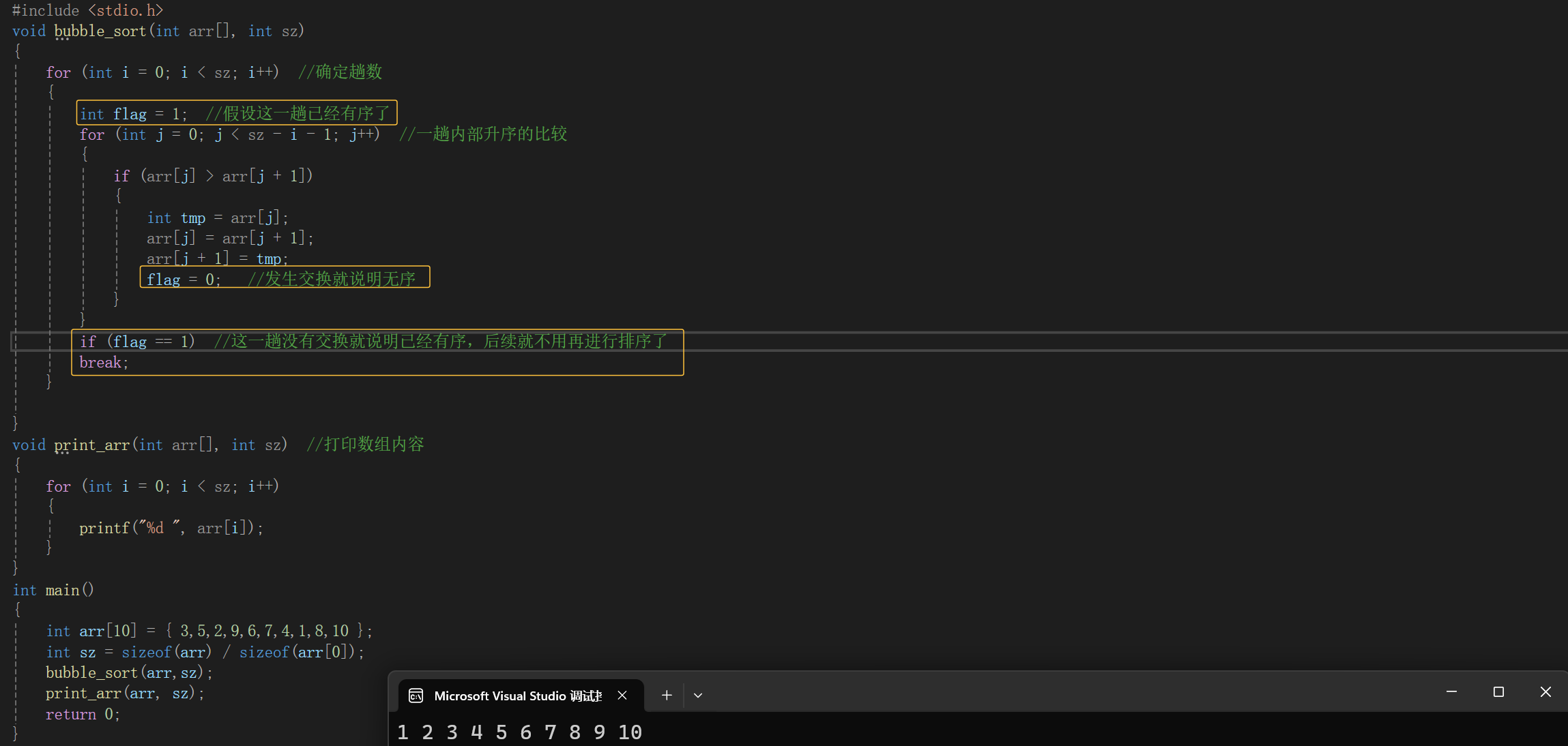
这样的话代码运行效率就会高很多,比如我的数组内容是{9,0,1,2,3,4,5,6,7,8},那我把9也就是数组第一个元素,与后面相邻的元素两两交换,第一趟交换完之后就是{0,1,2,3,4,5,6,7,8,9},这样它就已经有序了,就不用再去进行第二趟的比较了。
4)二级指针
指针变量也是变量,是变量就会有地址,那指针变量的地址存放在哪里呢?
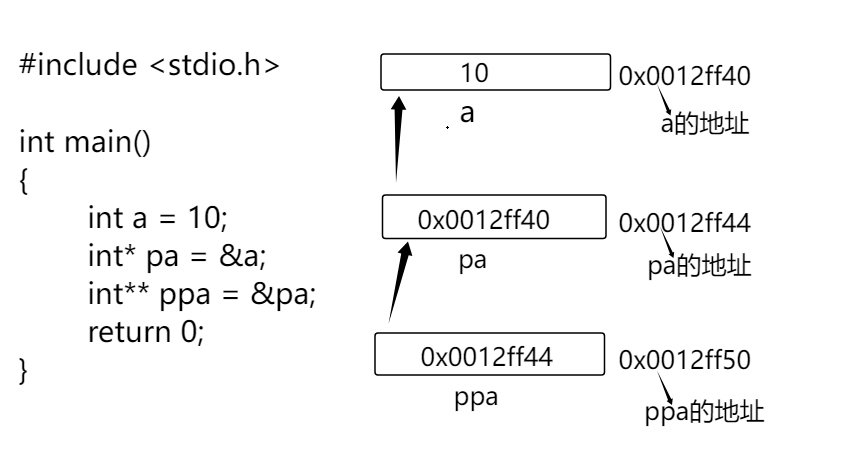
比如说a,pa,ppa的地址是我上图随便写的,那么指针变量pa就可以找到a的地址,*pa就可以找到a地址中存放的内容,也就是*pa == a == 10,那么指针变量ppa不就可以找到pa的地址,*ppa就可以找到pa地址中的内容,也就是a的地址,代码中**ppa不就相当于对*pa解引用,那**ppa不就可以找到a地址中存放的内容了对吧,那我们来看一下打印结果。
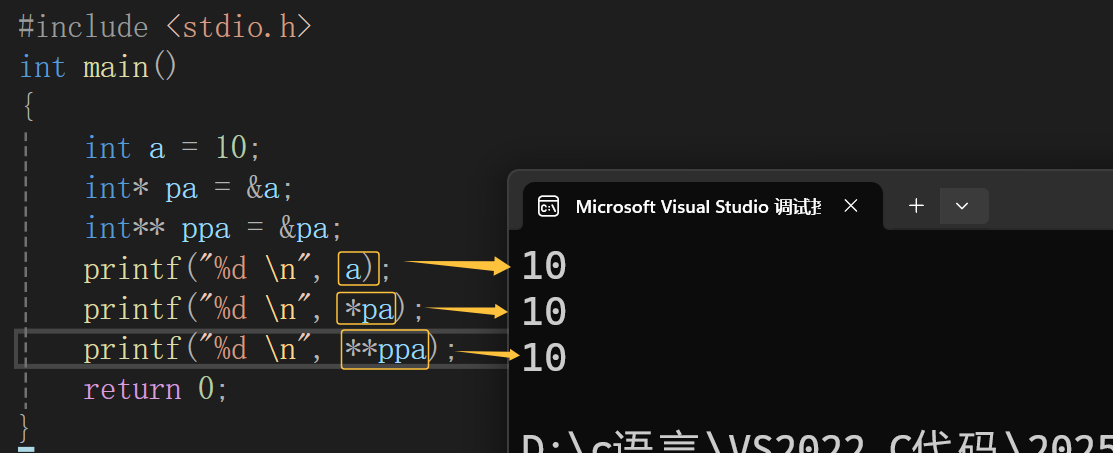
上面代码中:
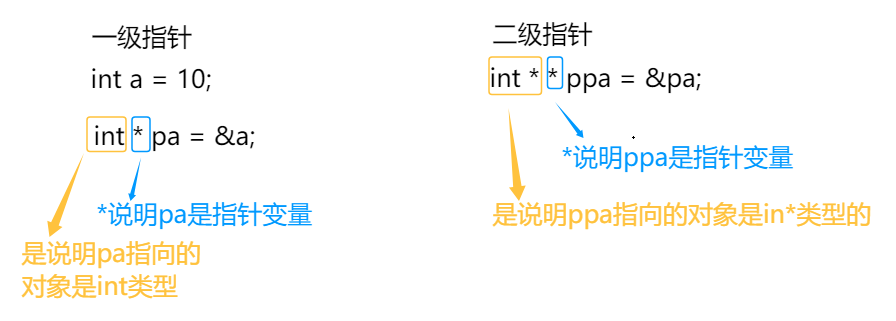
一级指针
int a = 10;
int* pa = &a;//pa是指针变量,pa是一级指针
pa是变量,也有自己的地址
int** ppa = &pa;//ppa是二级指针变量,ppa是二级指针
那如何理解二级指针呢?
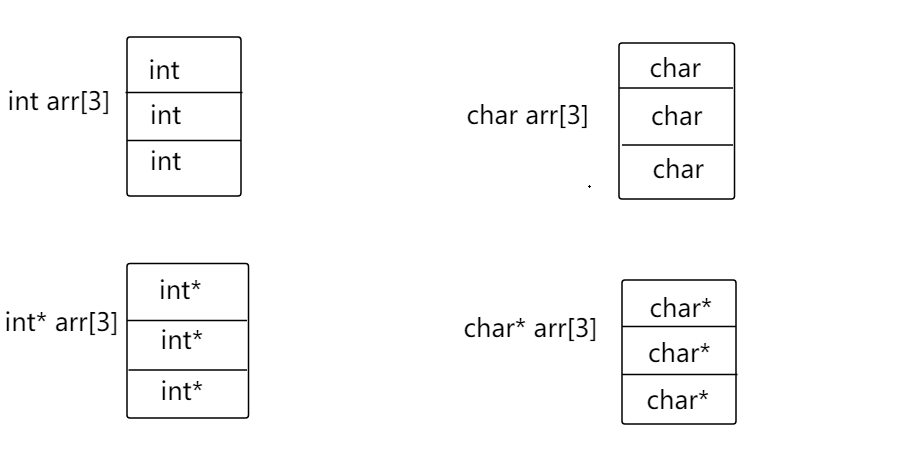
5)指针数组
什么是指针数组呢?指针数组是指针还是数组?带着这两个疑问,我来展开指针数组的讲解:
我们用类比的思想:前面说到数组有整型数组(存放整型的数组,数组中的每个元素都是整型类型),字符数组(存放字符的数组,数组中的每个元素都是字符类型),那么指针数组就是存放指针的数组,数组中的每个元素都是指针类型:
指针数组模拟二维数组:
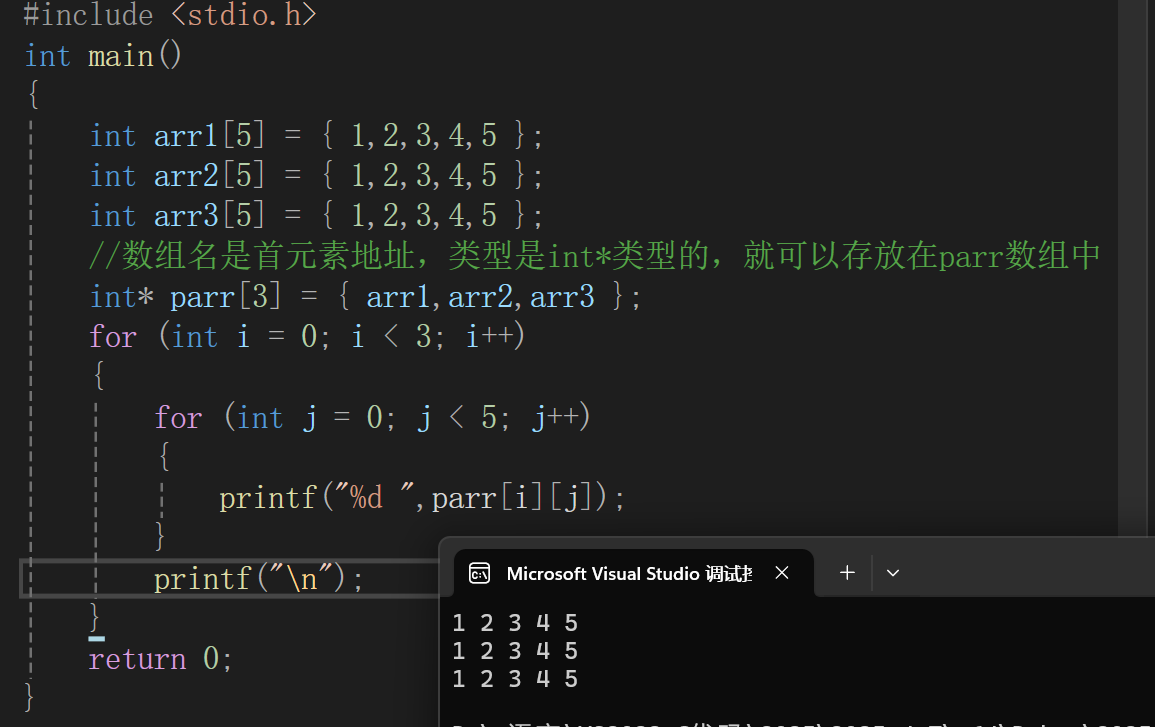
parr[i]是访问parr数组的元素,也就是parr[i]找到的数组元素指向了整型一维数组,parr[i][j]就是整型一维数组中的元素,上述的代码模拟出二维数组的效果,实际上并非完全是二维数组。
这样就实现了指针模拟二维数组,以上内容也相信各位道友理解了哈。
3.指针三
1)字符指针变量
字符指针变量:
在指针的类型中我们知道有一种指针类型为字符指针cha*
一般使用如下:
int main()
{
char ch = 't';
char* pc = &ch;
*pc = 't';
return 0;
}
还有一种使用方式如下:
int main()
{
char* ps = "hellow world"; //这是一个常量字符串
printf("%s\n",ps);
}
这个代码的意思是把一个常量字符串首字符h的地址存放到指针变量ps中
但是我们一般把这一句代码char* ps = "hellow world";写成const char* ps = "hellow world";因为它是一个常量字符串,如果我们要通过*ps去修改字符串中的内容,比如*ps = 'w',是修改不了的,所以加上const 修饰*ps,是为了防止我们编写出把字符串内容重新修改的错误代码:
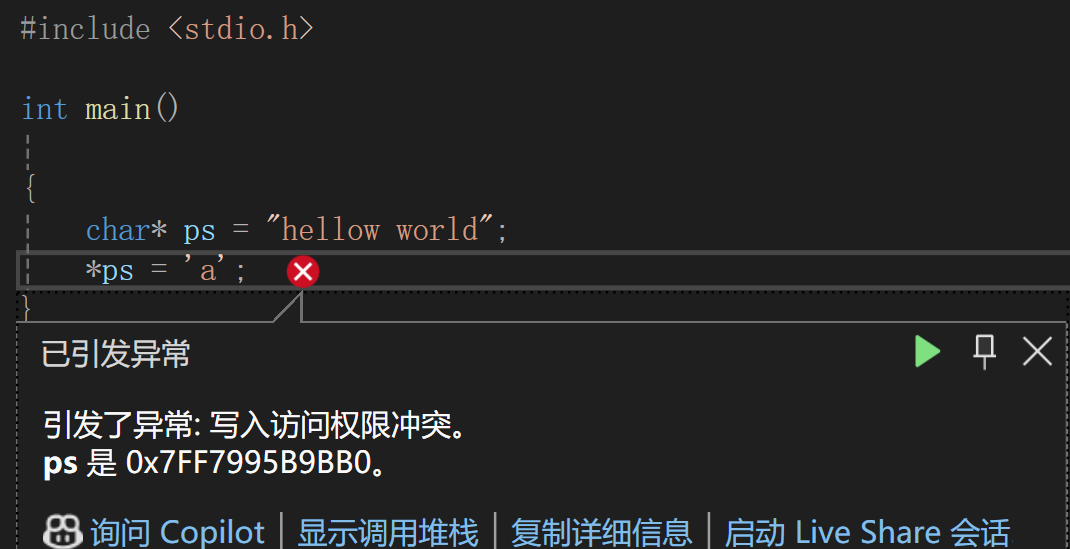
这样写虽然编译不会报错,但是你调试的时候它就崩了,你就会发现编译不报错,通过调试发现的错误代码处理是最麻烦的,因为你写完这样的代码,你编译之后,效果跟实际运行效果不一致,又不会报错,你还要通过调试去找代码的问题,就比较麻烦了。
2)数组指针变量
前面说到指针数组是一个数组,那么数组指针变量是指针变量还是数组?答案是:指针变量
我们已经熟悉了整型指针变量:int* pint;存放的是整型变量的地址,能够指向整型数据的指针,字符型指针变量:char* pc;存放的是字符型变量的地址,能够指向字符型数据的指针。那数组指针变量就是:存放的是数组的地址,能够指向数组的指针变量。
数组指针变量形式:int(*p)[10];前面提到指针数组形式:int* p[10];两者的区别就是数组指针变量的*p加了(),而指针数组的*p没有加(),不加()的话,因为[ ]的优先级要高于*号的,所以p会先和[ ]结合,加上()的话,p就先会和*结合,此时就说明p是一个指针变量,然后指针指向的是一个大小为10个整型的数组,所以p是一个指针,指向一个数组,叫数组指针。
数组指针的初始化如下:
int(*p)[10] = &arr;
数组指针类型解析:
int (*p) [10] = &arr;
| | |
| | |
| | p指向数组元素个数
| p是数组指针变量名
p指向的数组元素类型
//int(*)[10] = &arr;去掉变量名就是数组指针的类型
3)二维数组传参的本质
二维数组传参的本质也是指针,之前有一个二维数组需要传参给一个函数的时候,我是这样写的:
#include <stdio.h>
void test(int arr[3][5],int r,int c)
{
for(int i = 0; i < r; i++)
{
for(int j = 0; j < c; j++)
{
printf("%d ",arr[i][j]);
}
printf("\n");
}
}
int main()
{
int arr[3][5] = {{1,2,3,4,5},{2,3,4,5,6},{3,4,5,6,7}};
test(arr,3,5);
return 0;
}
这里的实参是二维数组,形参也写成二维数组的形式,之前说一维数组传参的时候,形参部分可以写成数组也可以写成指针形式,那么二维数组也是一样的,形参部分可以写成二维数组形式,也可以写成指针形式,如下:
#include <stdio.h>
void test(int (*arr)[5],int r,int c)
{
for(int i = 0; i < r; i++)
{
for(int j = 0; j < c; j++)
{
printf("%d ",arr[i][j]);
}
printf("\n");
}
}
int main()
{
int arr[3][5] = {{1,2,3,4,5},{2,3,4,5,6},{3,4,5,6,7}};
test(arr,3,5);
return 0;
}
若有道友不理解的话,我们就还是写成二维数组的形式就好,只需要知道,他虽然写成了二维数组的形式,但它本质上是指针就行。
4)函数指针变量
函数指针:
我们还是用类比的思想,整型指针:存放的是整型地址,指向的是整型变量,数组指针:存放的是数组地址,指向的是数组,函数指针:存放的是函数的地址,指向的是函数。
函数指针类型:
int (*p) (int,int*)
| | |
| | p指向函数的参数类型和个数的交代
| 函数指针变量名,p就是函数指针变量
p指向函数的返回类型
//int (*) (int,int*),去掉函数名就是p函数指针变量的类型
函数指针变量的使用:
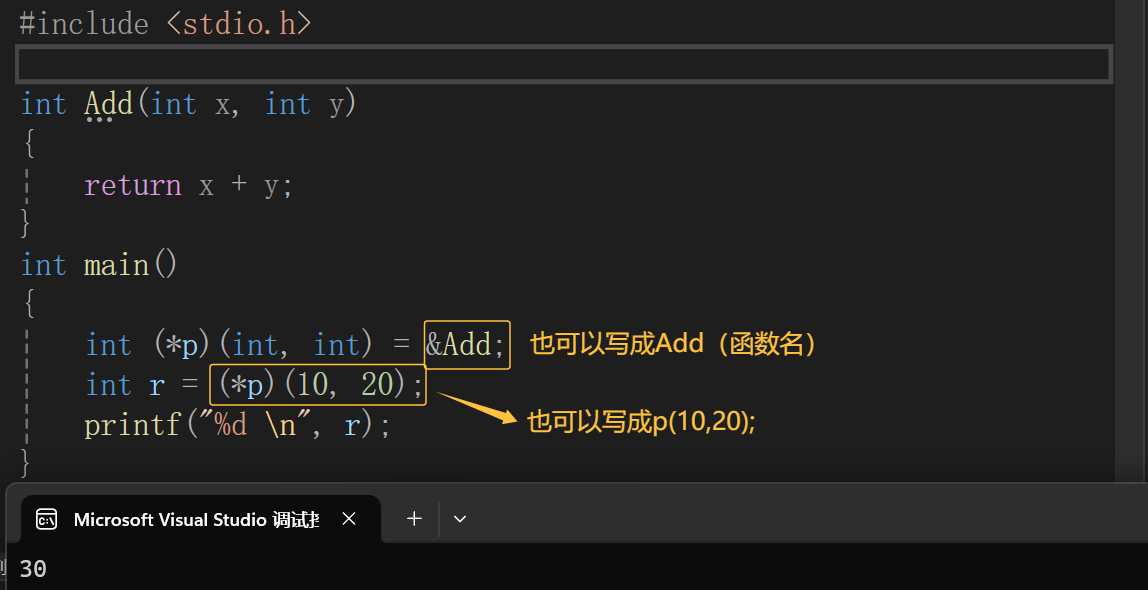
typedef关键字:
typedef是用来类型重命名的,可以将复杂的类型简单化。比如说:unsigned int n = 100;
你要是觉得unsigned int 写起来比较麻烦,就可以用typedef来重命名。
typedef unsigned int uint;
uint n = 100; //就相当于unsigned int n = 100;
那么指针类型也可以重命名,比如将int*重命名为pint_t,就可以这样写:
typedef int* pint_t;
但是对于数组指针类型和函数指针类型稍微有点区别:
比如将数组指针类型int(*)[5]重命名为pint_t,是这样写的:
typedef int(*pint_t)[5]; //新的类型名必须在括号中*的右边
函数指针类型的重命名也是一样的,比如将void(*)(int)类型重命名为pint_t,是这样写的:
typedef void(*pint_t)(int); //新的类型名必须在括号中*的右边
5)函数指针数组
数组是一个存放相同类型数据的存储空间,我前面已经介绍了指针数组,那么这里我们还是用类比的思想:
字符数组:charr arr[5]; 整型数组:int arr[5];
指针数组:char* arr[5]; int* arr[5];
函数指针数组其实就是指针数组的一种,这种数组中存放的是函数指针。
例如:写四个函数,实现加减乘除运算,代码如下:
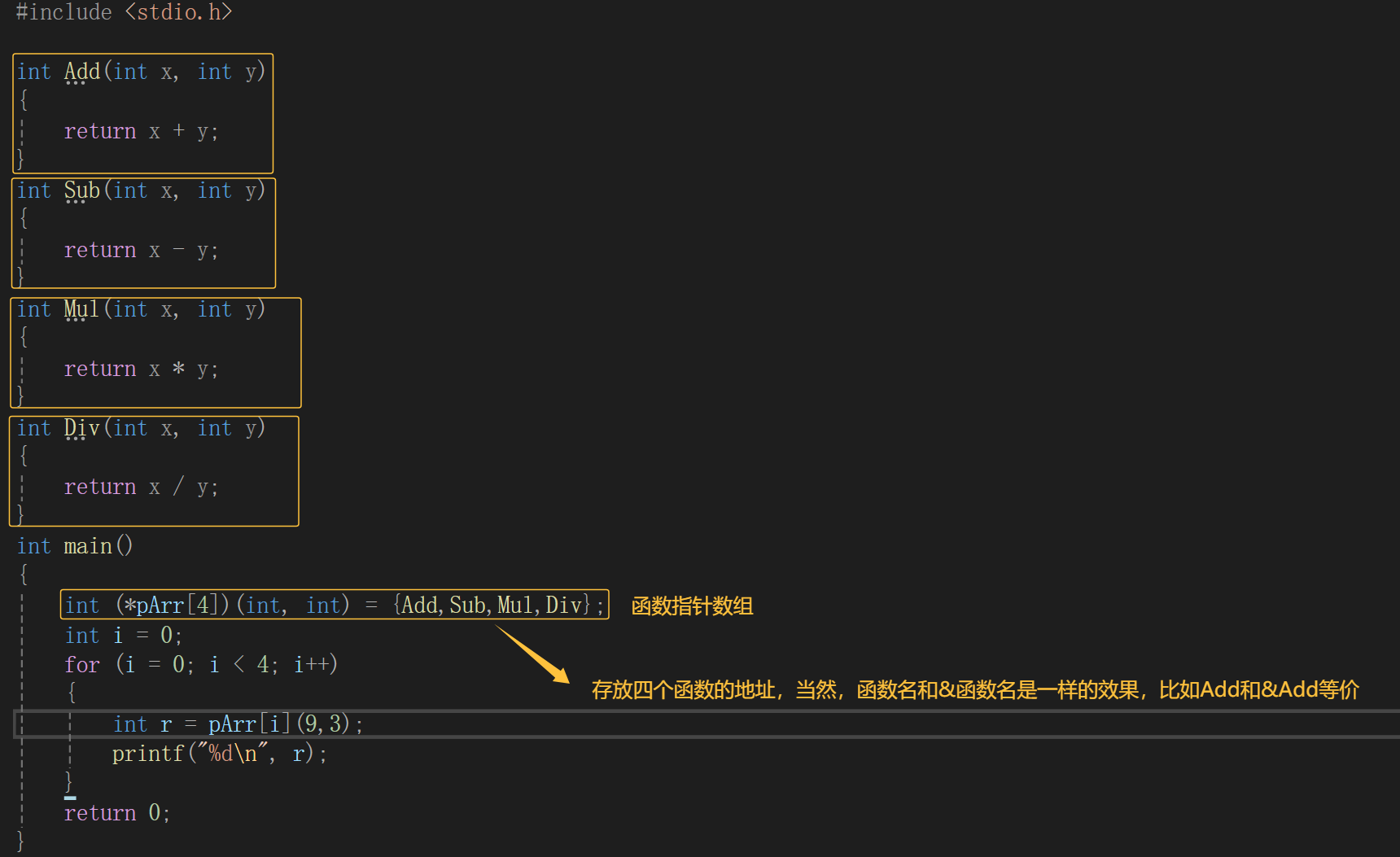

我们来看这一句代码:int (*pArr[4])(int, int);如果把[4]去掉,代码就成了int (*pArr)(int, int);这不就是前面刚讲过的函数指针变量吗,给它稍作修改不就成了一个函数指针数组。
6)转移表
函数指针的用途:转移表
这里我实现一个模拟计算器(加减乘除):
switch语句实现,代码如下:
#include <stdio.h>
void menu()
{
printf("***********************\n");
printf("******1.Add 2.Sub ****\n");
printf("******3.Mul 4.Div ****\n");
printf("******0.exit ***\n");
printf("***********************\n");
}
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int Mul(int x, int y)
{
return x * y;
}
int Div(int x, int y)
{
return x / y;
}
int main()
{
int input = 0;
int x = 0;
int y = 0;
int r = 0;
do
{
menu();
printf("请选择->\n");
scanf("%d", &input);
switch (input)
{
case 1:
printf("请输入两个操作数:");
scanf("%d %d", &x, &y);
r = Add(x,y);
printf("%d", r);
break;
case 2:
printf("请输入两个操作数:");
scanf("%d %d", &x, &y);
r = Sub(x, y);
printf("%d", r);
break;
case 3:
printf("请输入两个操作数:");
scanf("%d %d", &x, &y);
r = Mul(x, y);
printf("%d", r);
break;
case 4 :
printf("请输入两个操作数:");
scanf("%d %d", &x, &y);
r = Div(x, y);
printf("%d", r);
break;
case 0:
printf("退出计算器\n");
break;
default:
printf("选择错误,重新选择\n");
break;
}
printf("\n");
} while (input);
return 0;
}
这样就简单实现了一个加减乘除计算器,但是这个代码其实是不太好的,为什么这么说呢?如果我想对这个计算器的功能进行拓展,比如说求两个操作数的按位与,按位或,按位异或等等运算,那我是不是就要多加case 5:、case 6:、case 7:等等语句,那switch语句是不是就会太长了,而且一个个加也是很麻烦的,这是一个点,还有一个点就是它的代码有点冗余(重复)了,比如:
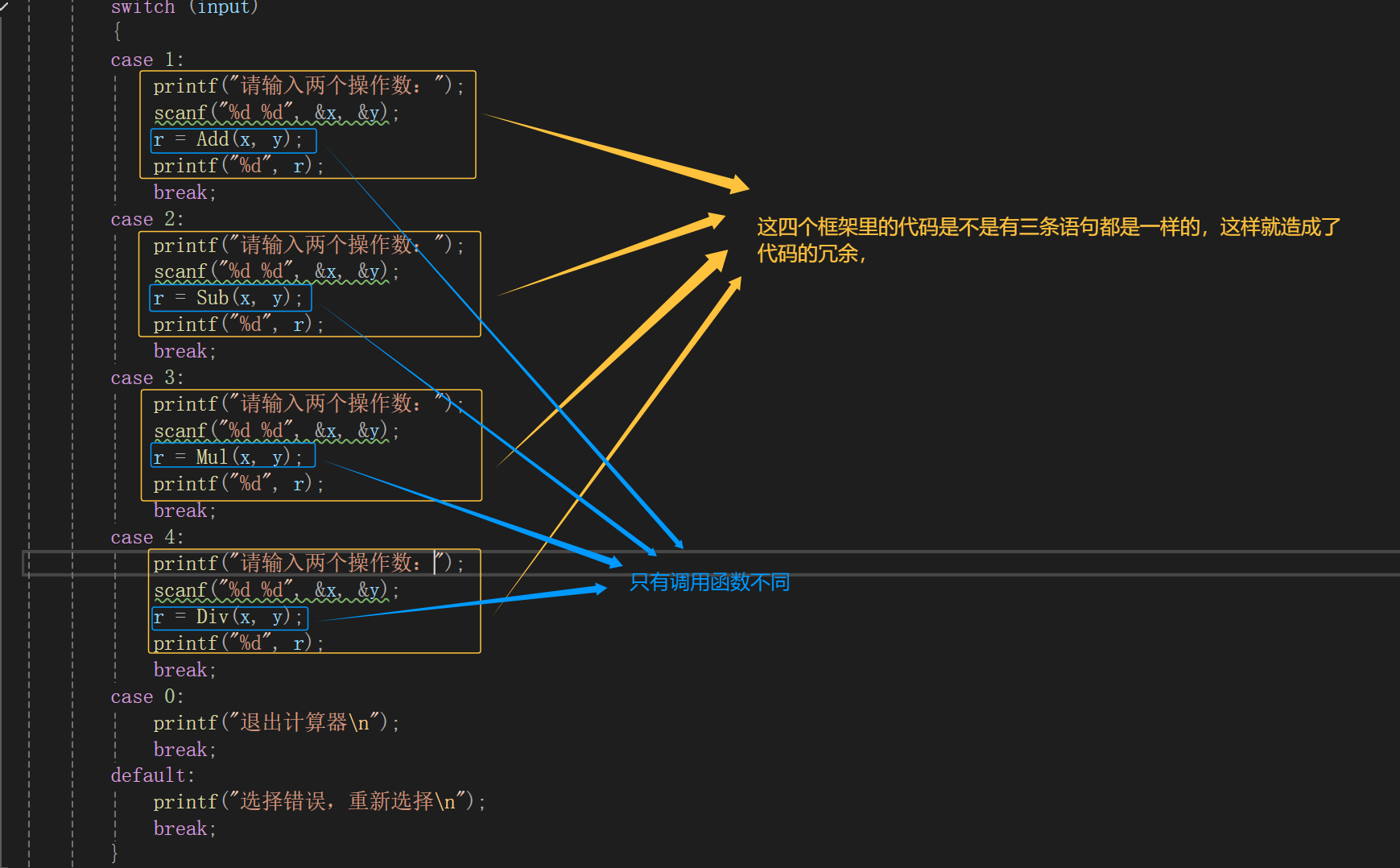
转移表实现,代码如下:
#include <stdio.h>
void menu()
{
printf("***********************\n");
printf("******1.Add 2.Sub ****\n");
printf("******3.Mul 4.Div ****\n");
printf("******0.exit ***\n");
printf("***********************\n");
}
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int Mul(int x, int y)
{
return x * y;
}
int Div(int x, int y)
{
return x / y;
}
int main()
{
int input = 0;
int x = 0;
int y = 0;
int r = 0;
do
{
menu();
printf("请选择->\n");
scanf("%d", &input);
if (input == 0)
{
printf("退出计算器\n");
}
else if (input >= 1 && input <= 4)
{
int(*parr[5])(int, int) = {NULL,Add,Sub,Mul,Div};
printf("请输入两个操作数:");
scanf("%d %d", &x, &y);
r = parr[input](x, y);
printf("%d\n", r);
}
else
{
printf("选择错误,重新选择\n");
}
} while (input);
return 0;
}
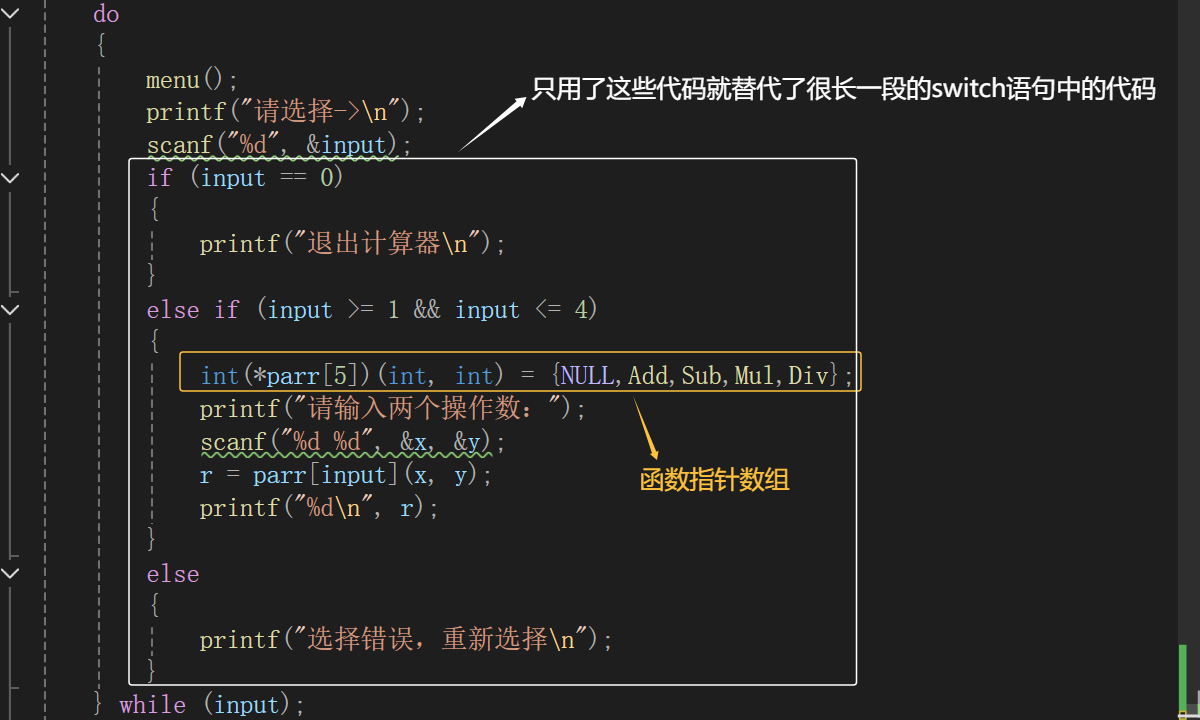
如此一来,不仅解决了switch语句中代码冗余(重复)的问题,而且代码拓展也很方便了,只需要写相应的函数,实现相应的功能,再把函数名加到函数指针数组中,就非常的方便了。
这里数组中第一个元素是NULL,是因为数组下标是从0开始的,但菜单中Add函数是1,就是输入1才会进行Add函数中的运算,写NULL的好处是,NULL的值本质是0,输入的数是0的话就进行上面那个if语句,就直接跳出计算器了。
7)回调函数:
回调函数就是一个通过函数指针调用的函数,如果你把函数的指针作为参数传递给另一个函数,当这个指针被用来调用其所指向的函数时,被调用函数就是回调函数,回调函数不是由该函数的实现方直接调用,而是在特定的事件或条件发生时由另外的一方调用的,用于对该事件或条件进行响应。
这是回调函数的概念,想必各位道友也没有理解哈,我刚开始学的时候看到这个概念也是一脸懵,不理解,待会我就通过代码来解释,就会有一个很好的理解,其实各位道友发现没,很多概念性的东西往往不好理解,就比如高数,大学物理课本中的一些概念,你根本看不懂,说不好听一点就是防自学,我本来不打算将这个内容写到文章里的,因为我想写的就是一些C语言基础知识,但是这块内容我是觉得有点难度的,思索再三,我觉得还是很有必要讲一下的,因为有了前面文章中的基础,适当的拓展也是很有必要的。
上面那个实现计算器的代码,用switch语句来写发现会有代码冗余(重复),我写了一个解决方案就是用转移表,但是还有一个方案就是用回调函数,我们来看一下。
#include <stdio.h>
void menu()
{
printf("***********************\n");
printf("******1.Add 2.Sub ****\n");
printf("******3.Mul 4.Div ****\n");
printf("******0.exit ***\n");
printf("***********************\n");
}
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int Mul(int x, int y)
{
return x * y;
}
int Div(int x, int y)
{
return x / y;
}
void Calc(int(*p)(int,int))
{
int x = 0;
int y = 0;
int r = 0;
printf("请输入两个操作数:");
scanf("%d %d", &x, &y);
r = p(x, y);
printf("%d", r);
}
int main()
{
int input = 0;
do
{
menu();
printf("请选择->\n");
scanf("%d", &input);
switch (input)
{
case 1:
Calc(Add);
break;
case 2:
Calc(Sub);
break;
case 3:
Calc(Mul);
break;
case 4 :
Calc(Div);
break;
case 0:
printf("退出计算器\n");
break;
default:
printf("选择错误,重新选择\n");
break;
}
printf("\n");
} while (input);
return 0;
}

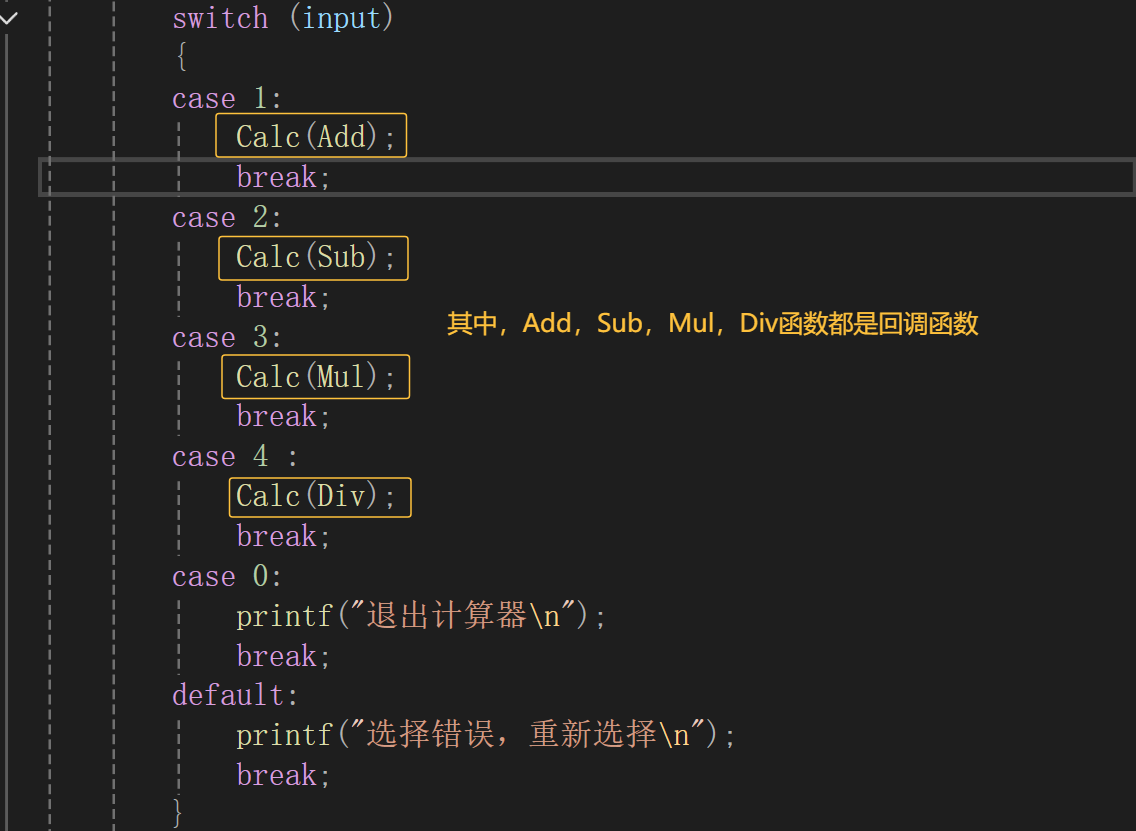
那我画个图来给道友们解释一下是怎么个事呢?

也相信各位道友理解了哈。
8)sizeof和strlen的对比
sizeof:
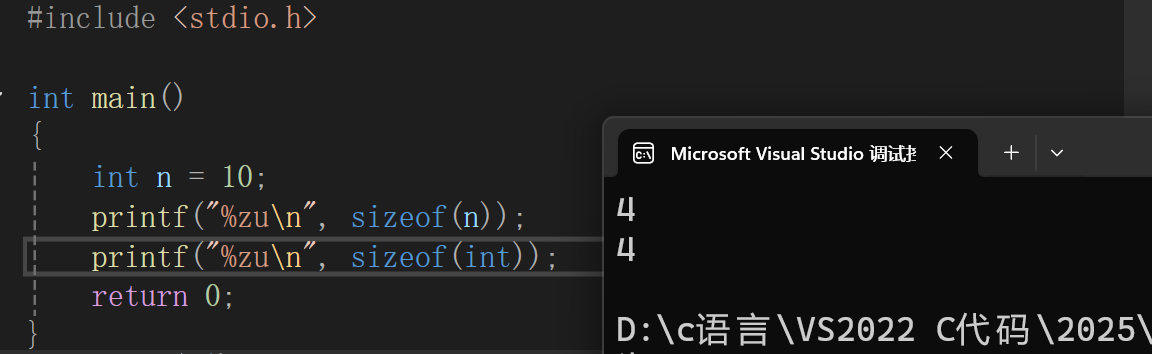
之前在学习操作符的时候,我们学习了sizeof,szieof是用来计算变量所占内存空间大小的,单位是字节,如果操作数是类型的话,计算的是使用类型创建的变量所占内存空间的大小,并且sizeof只关注内存空间的大小,不在乎内存中存放的数据。比如:
strlen:
strlen是C语言中的一个库函数,功能是求字符串的长度,函数原型如下:
size_t strlen (const char* str);
统计的是strlen函数的参数str中这个地址开始向后,\0之前字符串中字符的个数,strlen函数会一直向后找\0字符,直到找到为止,所以可能存在越界查找。
我们来看一段代码,看一下这段代码的运行结果:
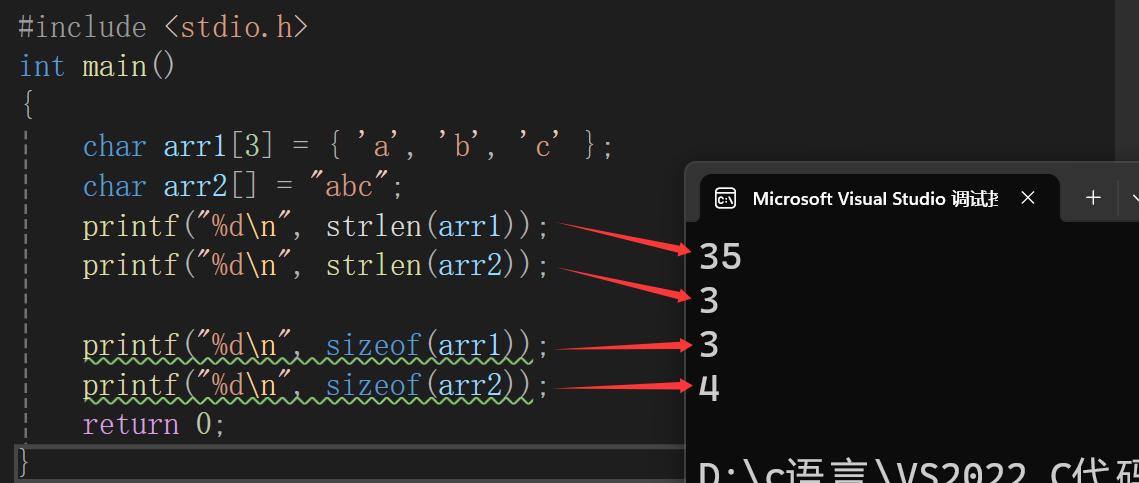
我们来分析一下运行结果,首先arr1数组中存放的是3个字符:'a' 'b' 'c',所以arr1数组中是不含有字符\0的,而arr2数组中存放的是4个字符,它的字符串中的字符是'a' 'b' 'c' '\0',因为字符串中本身存在字符\0,这个前面文章中介绍过哈,那么第一个打印结果是35,这是一个随机值,因为arr1数组中不存在\0,而strlen求的是\0之前的字符个数,没有找到\0,就继续找,直到找到位置,其实这里它已经越界查找了,正好找到第36个字符是\0,那么打印就是35,第二个打印结果是因为arr2数组中存放的是一个字符串,它本身就含有\0,所以打印结果是3,第三个打印结果3,是因为sizeof计算的是操作数所占内存的大小,而arr1数组的元素是3个,类型是char类型,所以是3,第四个打印结果是4,因为\0也是一个字符。
sizeof和strlen的对比:
| sizeof | strlen |
|
1.sizeof是操作符 2.sizeof计算操作符所占内存的大小,单位是字节。 3.不关注内存中存放什么数据 |
1.strlen是库函数,使用需要包含头文件string.h 2.strlen是求字符串长度的统计的是\0之前字符的个数 3.关注内存中是否有\0,如果没有\0,就会继续往后找,可能会越界 |
二,总结
1)作者声明:
原本打算是将C语言分为上中下三篇文章来写完,但是写完指针板块发现已经写了一万六千字了,因为指针是整个C语言中的精华,所以说我就写的内容更比较多,写的也比较详细,就把C语言下篇分为两篇文章来写,不然写完后面板块加起来有三四万字了,篇幅太长也会使得各位道友看不下去,但是指针这块确实不太好理解,学习起来比较烧脑,也希望我写的文章可以让各位道友有一个很好的理解哈,这也是我写文章的初心,可以让道友们看懂,理解透彻,总之呢,有什么问题也可以放在评论区或者私信我哈,看到必回!文章若有问题还请指出哈,若觉得写的不错,还望各位道友三连哈。
2)总结:
这篇文章也拖了较长的时间,主要前一周放纵了四五天没有学习,不知道为啥,突然就不想学习了哈哈,很莫名其妙,可能是迷茫了,也可能是累了,也可能是自己想的太多了,但是现在还是调整过来了,也继续向着自己的目标而努力,我想说的是,各位道友若有一天突然不想学习了,就立刻停下来,给自己一点时间缓缓,好好调整一下自己的状态,因为你那会要真不想学习,哪怕给你按在那里让你学你也学不进去的,不要把自己绷得太紧,我也希望各位道友可以去主动的学习,而不是被动的学习,上了大学之后,时间确实比高中初中充足了很多,你有的是时间去干一些自己喜欢的事,学习也好,娱乐也好,健身也好等等,而不是初高中,天天被盯着学习,除了学习还是学习,很少有时间去干一些学习之外自己喜欢的事情。所以,各位道友们,我们就一起努力,一起加油。朝着自己的目标继续努力。相信各位道友一定会成为理想中的自己,那我们下一篇文章再见!!!

















 3339
3339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









