




 本文详细介绍了堆排序算法的工作原理,包括如何构建初始堆、调整堆结构以及实现完整的排序过程。通过具体的实例展示了堆排序如何逐步将无序数组变为有序数组。
本文详细介绍了堆排序算法的工作原理,包括如何构建初始堆、调整堆结构以及实现完整的排序过程。通过具体的实例展示了堆排序如何逐步将无序数组变为有序数组。
堆排序实例
首先,建立初始的堆结构如图:
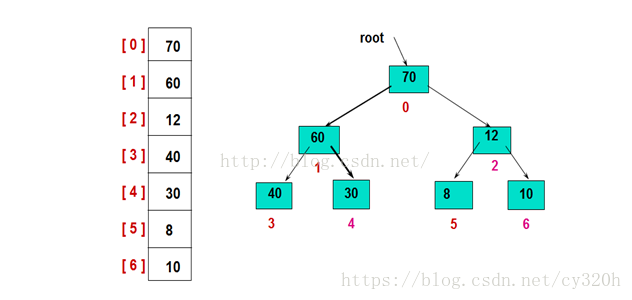
然后,交换堆顶的元素和最后一个元素,此时最后一个位置作为有序区(有序区显示为黄色),然后进行其他无序区的堆调整,重新得到大顶堆后,交换堆顶和倒数第二个元素的位置……
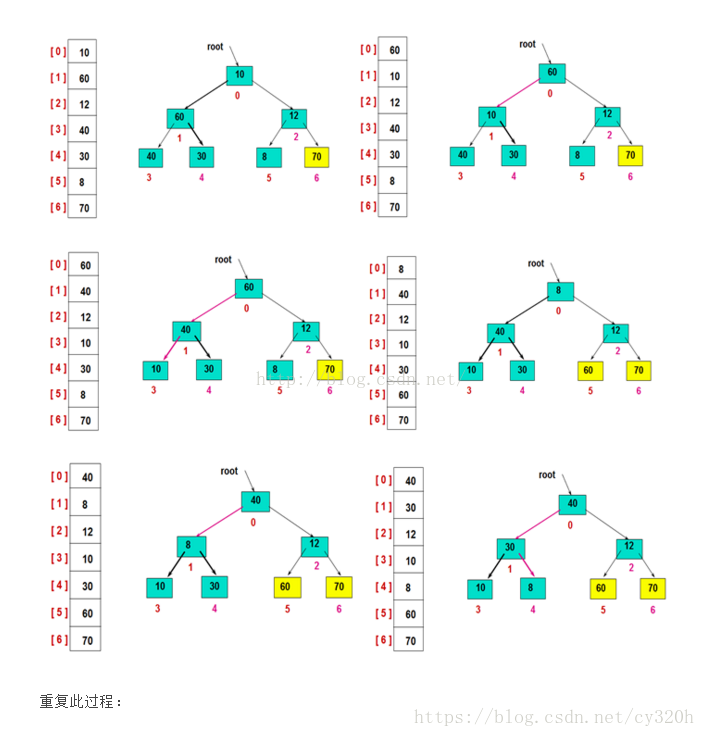
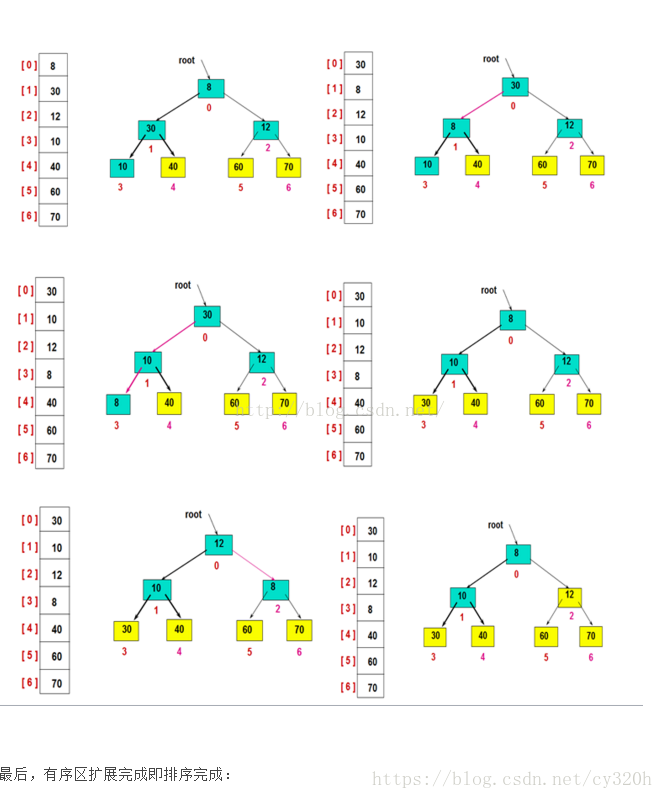
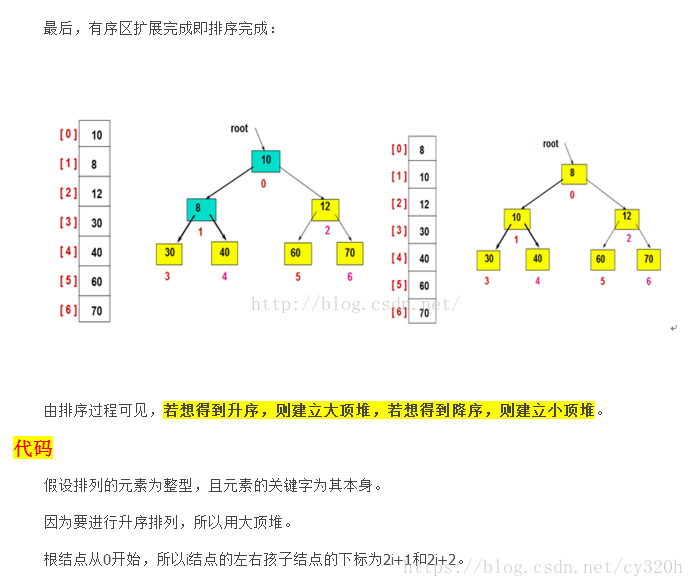
堆排序分析
堆排序方法对记录数较少的文件并不值得提倡,但对n较大的文件还是很有效的。因为其运行时间主要耗费在建初始堆和调整建新堆时进行的反复“筛选”上。
堆排序在最坏的情况下,其时间复杂度也为O(nlogn)。相对于快速排序来说,这是堆排序的最大优点。此外,堆排序仅需一个记录大小的供交换用的辅助存储空间。
在第一个元素的索引为 0 的情形中:
性质一:索引为i的左孩子的索引是 (2*i+1);
性质二:索引为i的左孩子的索引是 (2*i+2);
性质三:索引为i的父结点的索引是 floor((i-1)/2);
/*
* (最大)堆的向下调整算法
*
* 注:数组实现的堆中,第N个节点的左孩子的索引值是(2N+1),右孩子的索引是(2N+2)。
* 其中,N为数组下标索引值,如数组中第1个数对应的N为0。
*
* 参数说明:
* a -- 待排序的数组
* start -- 被下调节点的起始位置(一般为0,表示从第1个开始)
* end -- 截至范围(一般为数组中最后一个元素的索引)
*/
void maxheap_down(int a[], int start, int end)
{
int c = start; // 当前(current)节点的位置
int l = 2*c + 1; // 左(left)孩子的位置
int tmp = a[c]; // 当前(current)节点的大小
for (; l <= end; c=l,l=2*l+1)
{
// "l"是左孩子,"l+1"是右孩子
if ( l < end && a[l] < a[l+1])
l++; // 左右两孩子中选择较大者,即m_heap[l+1]
if (tmp >= a[l])
break; // 调整结束
else // 交换值
{
a[c] = a[l];
a[l]= tmp;
}
}
}
/*
* 堆排序(从小到大)
*
* 参数说明:
* a -- 待排序的数组
* n -- 数组的长度
*/
void heap_sort_asc(int a[], int n)
{
int i;
// 从(n/2-1) --> 0逐次遍历。遍历之后,得到的数组实际上是一个(最大)二叉堆。
for (i = n / 2 - 1; i >= 0; i--)
maxheap_down(a, i, n-1);
// 从最后一个元素开始对序列进行调整,不断的缩小调整的范围直到第一个元素
for (i = n - 1; i > 0; i--)
{
// 交换a[0]和a[i]。交换后,a[i]是a[0...i]中最大的。
swap(a[0], a[i]);
// 调整a[0...i-1],使得a[0...i-1]仍然是一个最大堆。
// 即,保证a[i-1]是a[0...i-1]中的最大值。
maxheap_down(a, 0, i-1);
}
}
















 30万+
30万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









