



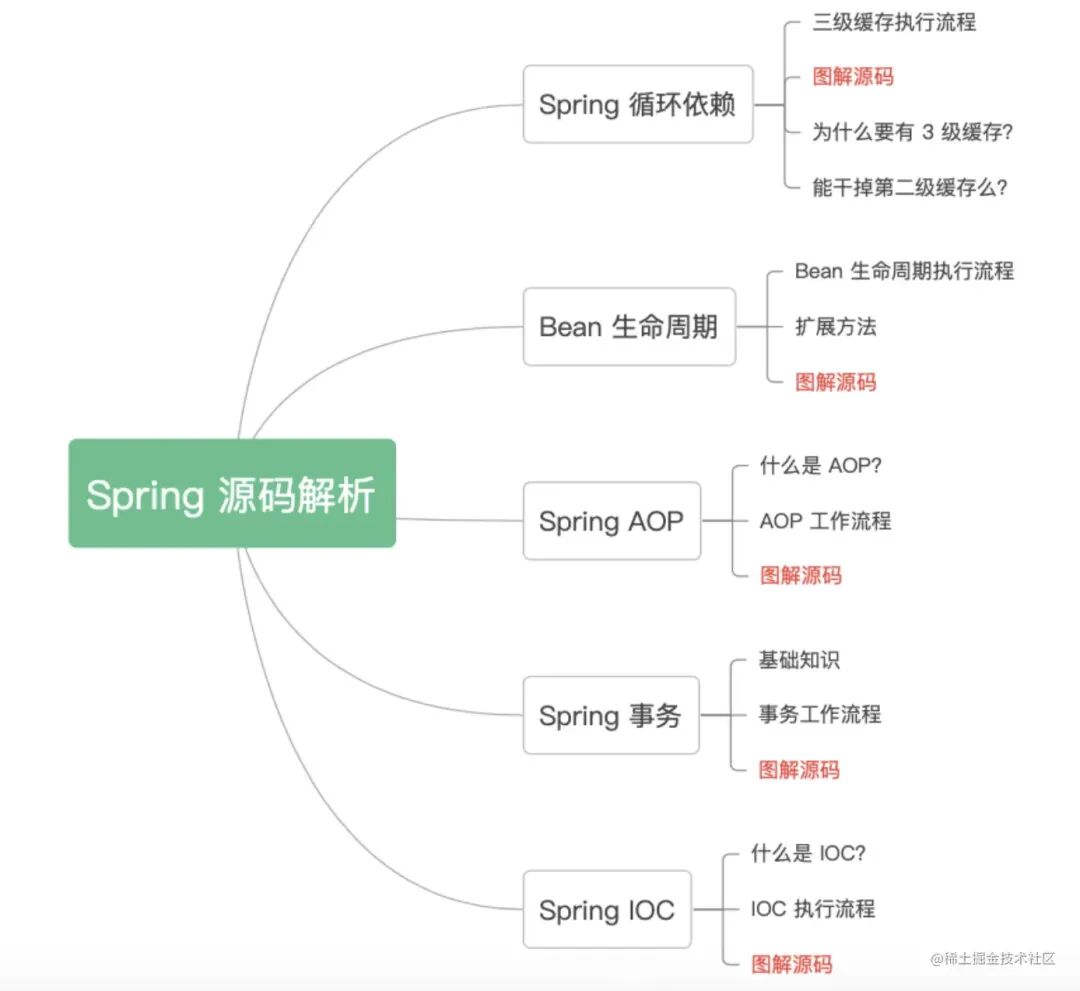
Spring源码解析简图:
Spring 如何解决循环依赖,⽹上的资料很多,但是感觉写得好的极少,特别是源码解读⽅⾯,我就⾃⼰单独出⼀ 篇,这篇⽂章绝对肝!
文章目录:
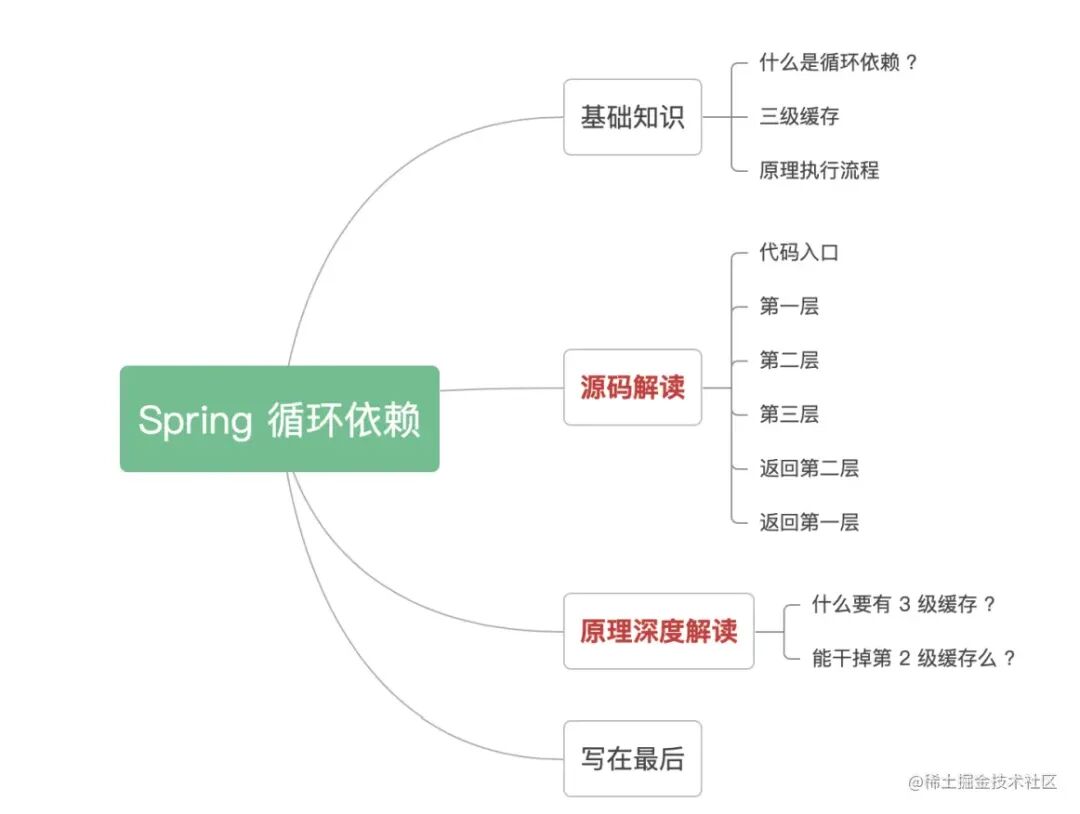
一. 基础知识
1.1 什么是循环依赖 ?
⼀个或多个对象之间存在直接或间接的依赖关系,这种依赖关系构成⼀个环形调⽤,有下⾯ 3 种⽅式。
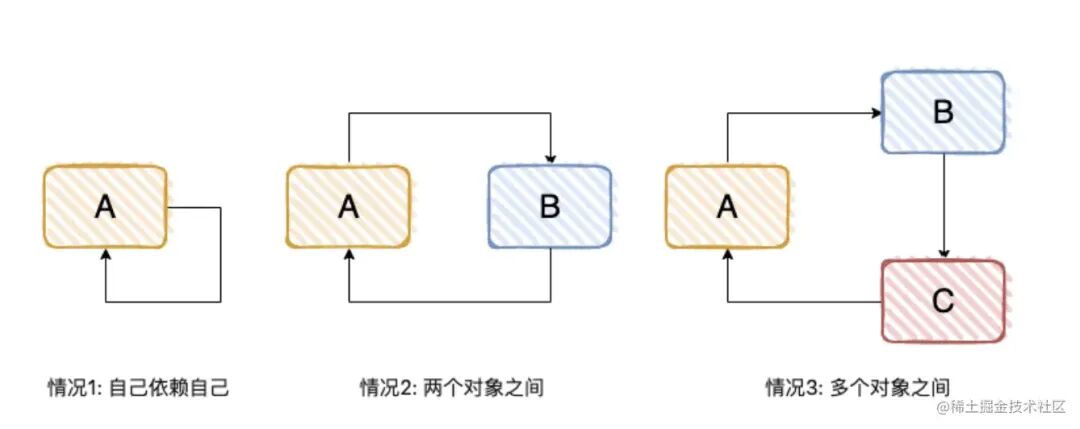
我们看⼀个简单的 Demo,对标“情况 2”。
@ServicepublicclassModel1{@Autowiredprivate Model2 model2;publicvoidtest1(){}}@ServicepublicclassModel2{@Autowiredprivate Model1 model1;publicvoidtest2(){}}
这是⼀个经典的循环依赖,它能正常运⾏,后⾯我们会通过源码的⻆度,解读整体的执⾏流程。
1.2 三级缓存
解读源码流程之前,spring 内部的三级缓存逻辑必须了解,要不然后⾯看代码会蒙圈。
![]()
第⼀级缓存:singletonObjects,⽤于保存实例化、注⼊、初始化完成的 bean 实例;
第⼆级缓存:earlySingletonObjects,⽤于保存实例化完成的 bean 实例;
第三级缓存:singletonFactories,⽤于保存 bean 创建⼯⼚,以便后⾯有机会创建代理对象。
![]()
这是最核⼼,我们直接上源码:
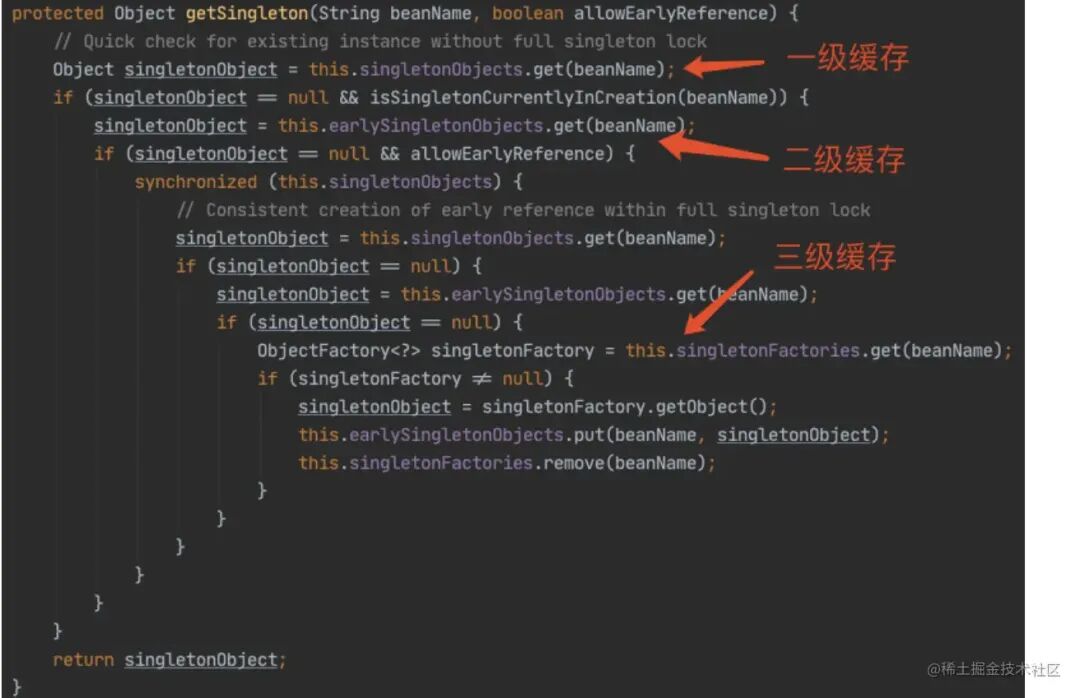
执⾏逻辑:
![]()
先从“第⼀级缓存”找对象,有就返回,没有就找“⼆级缓存”;
找“⼆级缓存”,有就返回,没有就找“三级缓存”;
找“三级缓存”,找到了,就获取对象,放到“⼆级缓存”,从“三级缓存”移除。
![]()
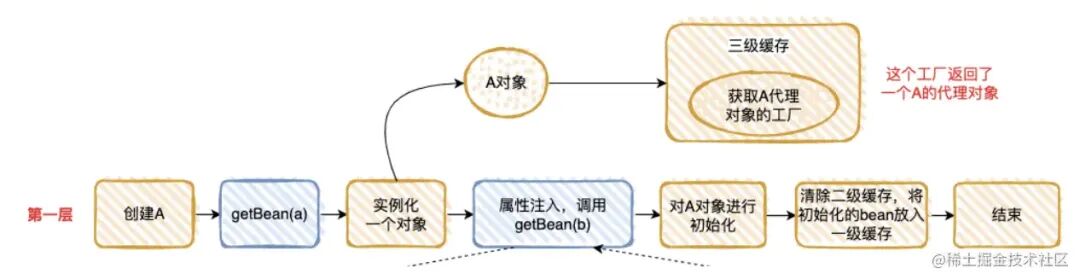
1.3 原理执⾏流程
我把“情况 2”执⾏的流程分解为下⾯ 3 步,是不是和“套娃”很像 ?
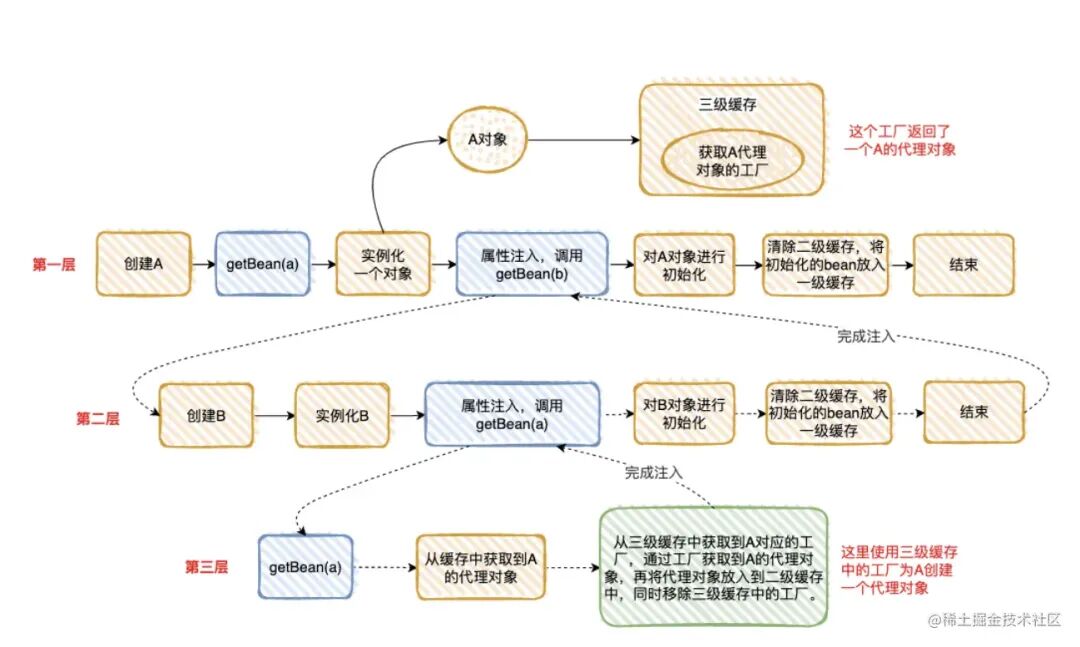
整个执⾏逻辑如下:
引用字数:386/300(单次引用不得超过300字,避免不合理引用)
![]()
在第⼀层中,先去获取 A 的 Bean,发现没有就准备去创建⼀个,然后将 A 的代理⼯⼚放⼊“三级缓存”(这个 A 其实是⼀个半成品,还没有对⾥⾯的属性进⾏注⼊),但是 A 依赖 B 的创建,就必须先去创建 B;
在第⼆层中,准备创建 B,发现 B ⼜依赖 A,需要先去创建 A;
在第三层中,去创建 A,因为第⼀层已经创建了 A 的代理⼯⼚,直接从“三级缓存”中拿到 A 的代理⼯⼚,获 取 A 的代理对象,放⼊“⼆级缓存”,并清除“三级缓存”;
回到第⼆层,现在有了 A 的代理对象,对 A 的依赖完美解决(这⾥的 A 仍然是个半成品),B 初始化成功;
回到第⼀层,现在 B 初始化成功,完成 A 对象的属性注⼊,然后再填充 A 的其它属性,以及 A 的其它步骤 (包括 AOP),完成对 A 完整的初始化功能(这⾥的 A 才是完整的 Bean)。
将 A 放⼊“⼀级缓存”。
![]()
为什么要⽤ 3 级缓存 ?我们先看源码执⾏流程,后⾯我会给出答案。
二. 源码解读
![]()
注意:Spring 的版本是 5.2.15.RELEASE,否则和我的代码不⼀样!!!
![]()
上⾯的知识,⽹上其实都有,下⾯才是我们的重头戏,让我们一起⾛⼀遍代码流程。
2.1 代码⼊⼝
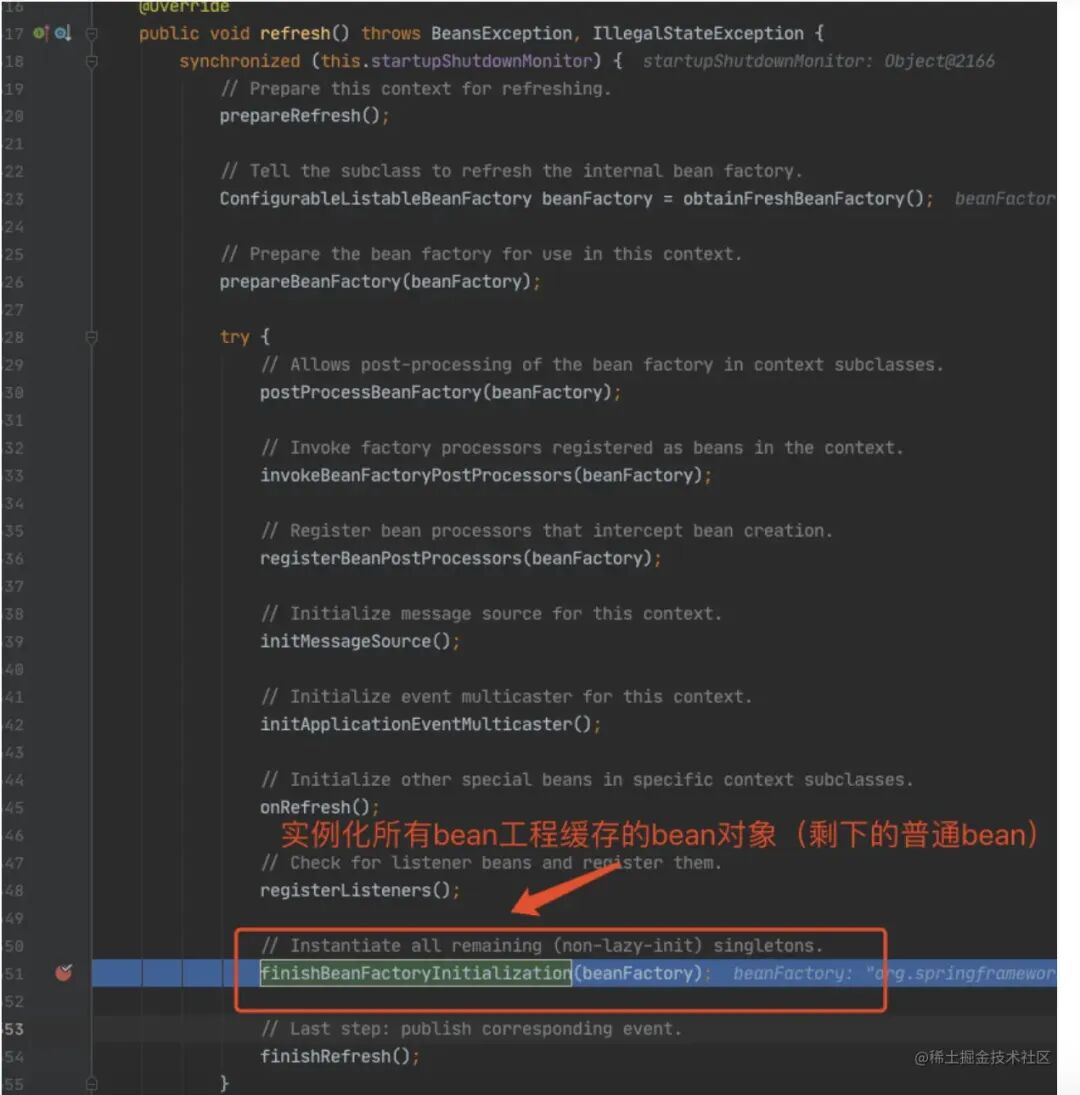
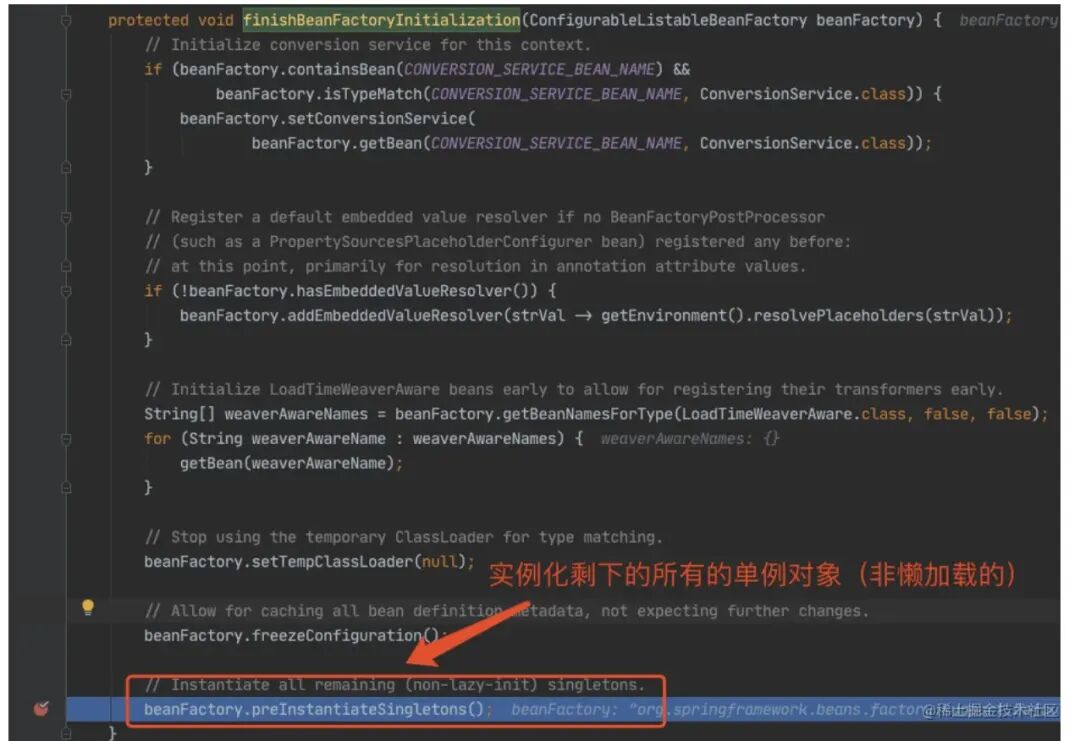
这⾥需要多跑⼏次,把前⾯的 beanName 跳过去,只看 Model1。
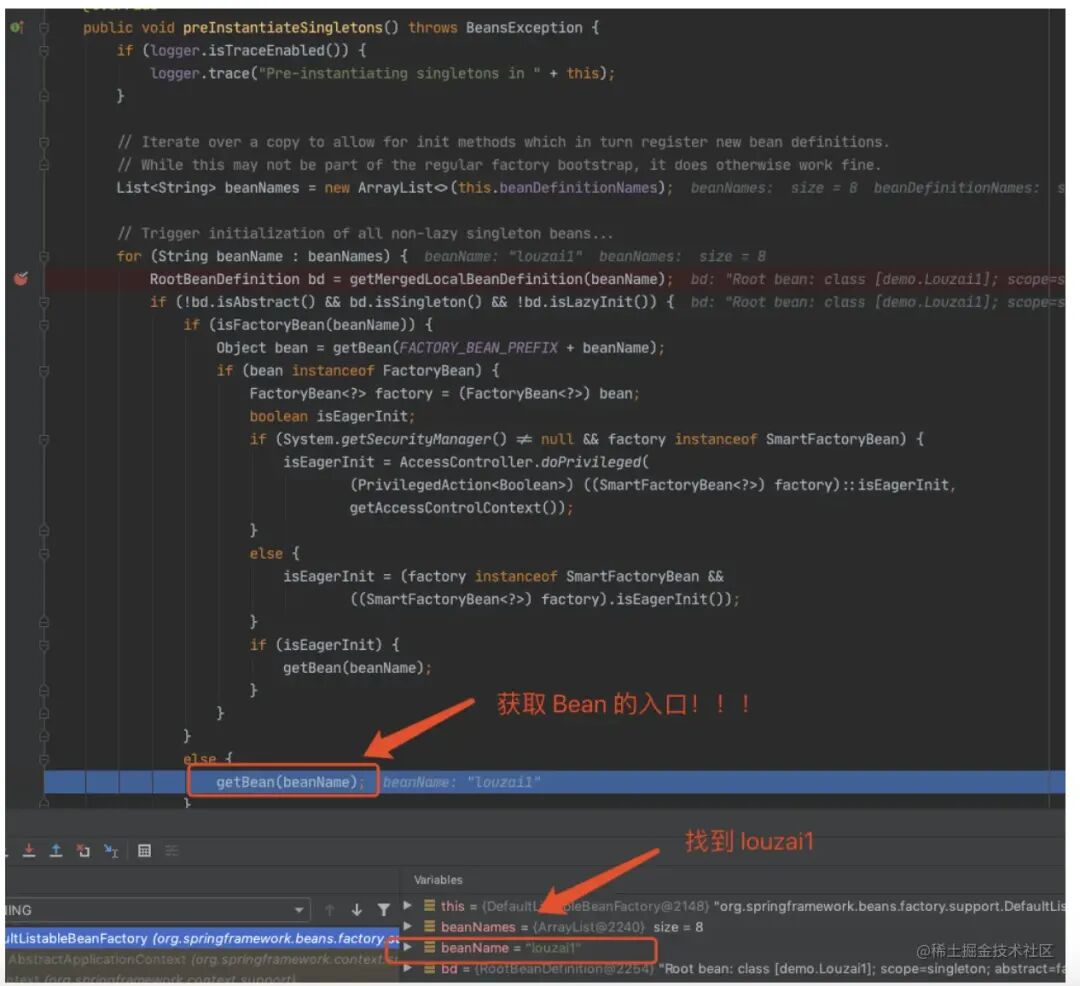

2.2 第⼀层
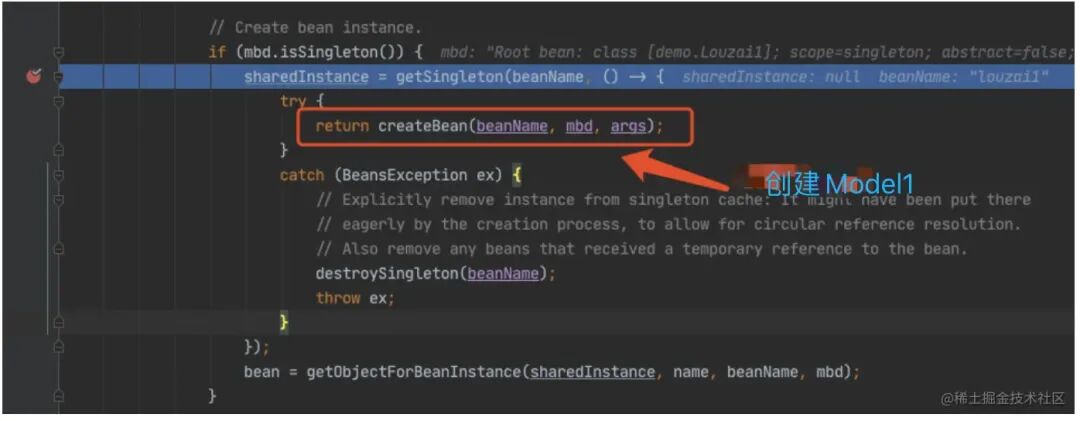
进⼊ doGetBean(),从 getSingleton() 没有找到对象,进⼊创建 Bean 的逻辑。
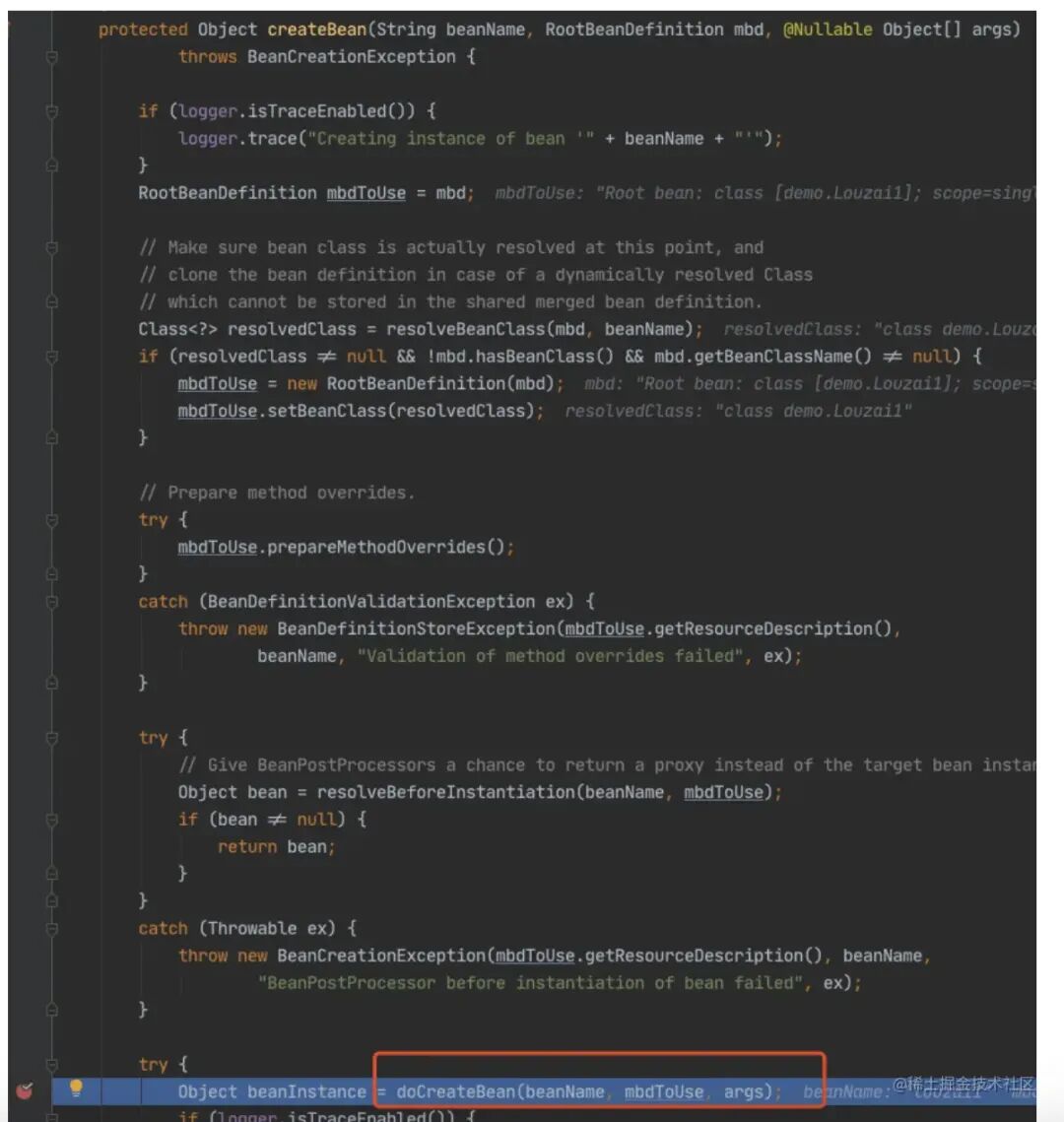
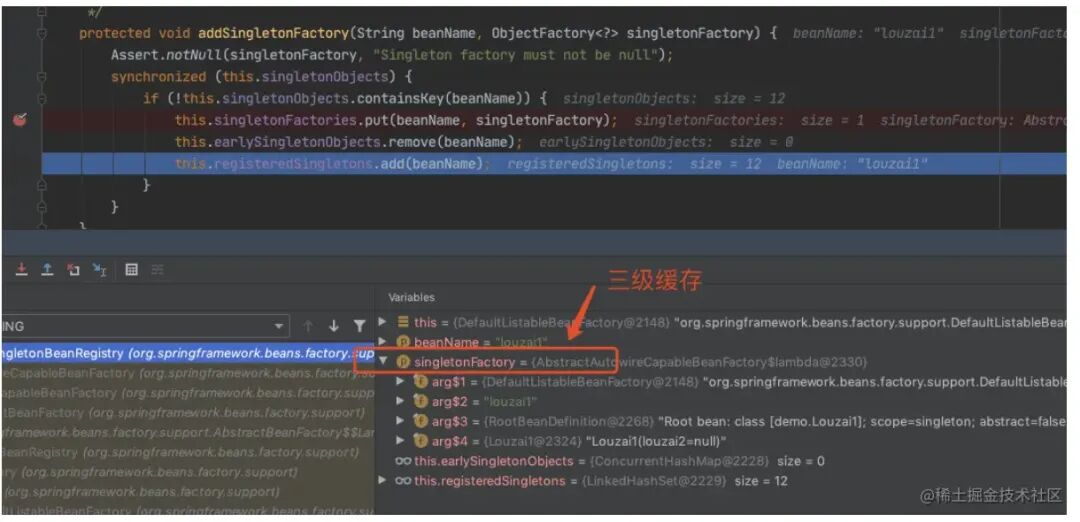
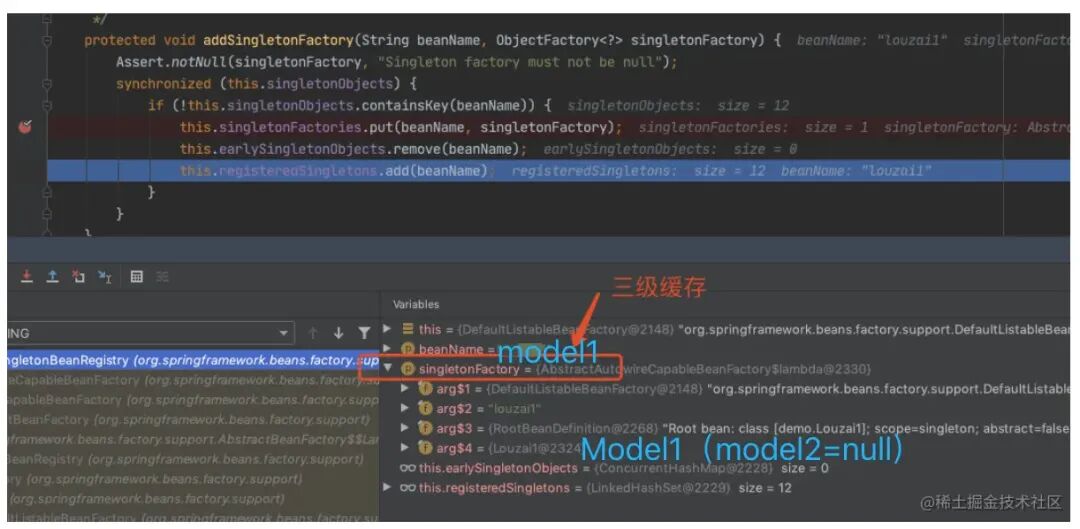
进⼊ doCreateBean() 后,调⽤ addSingletonFactory()。
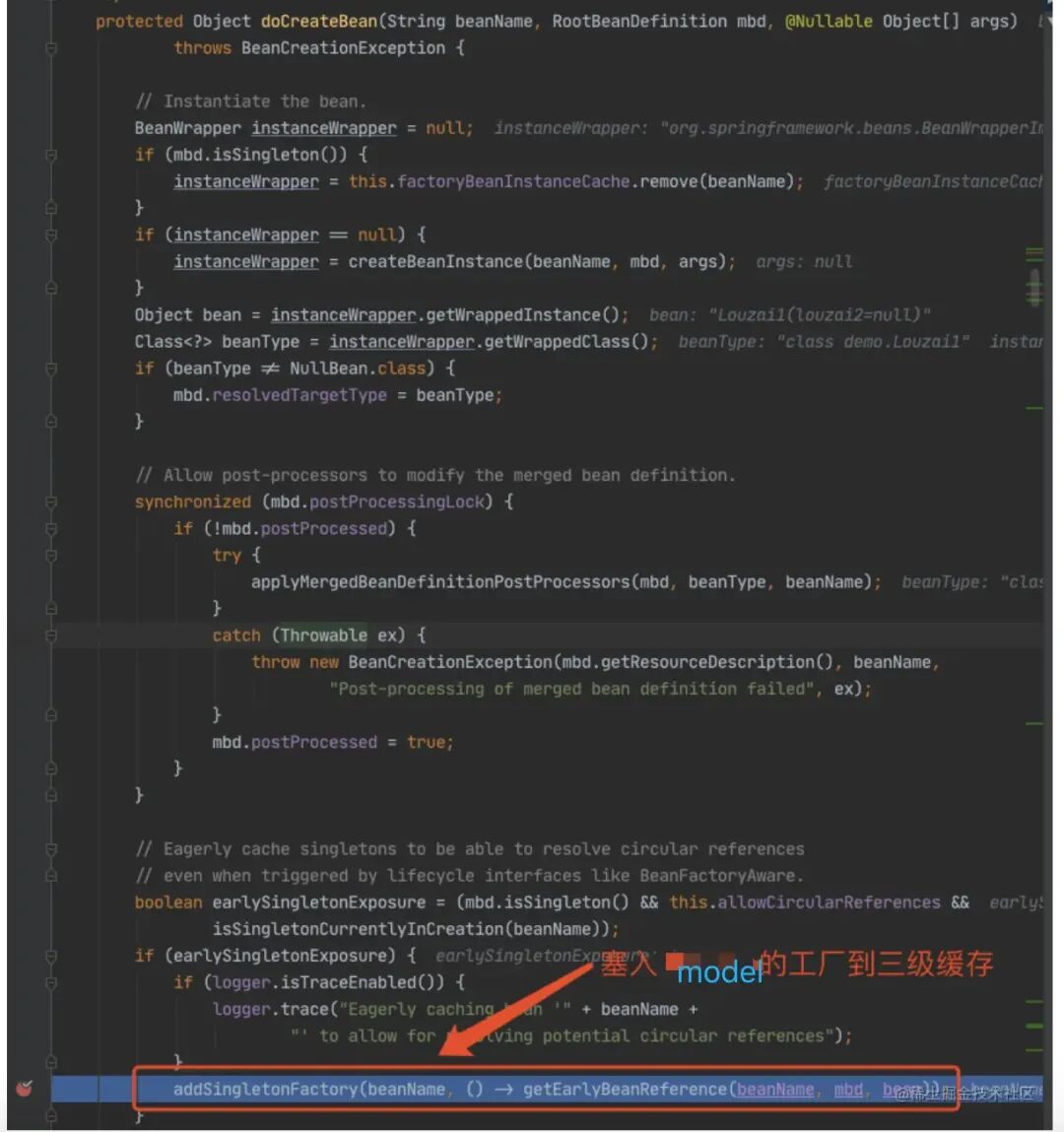
往三级缓存 singletonFactories 塞⼊ model1 的⼯⼚对象。
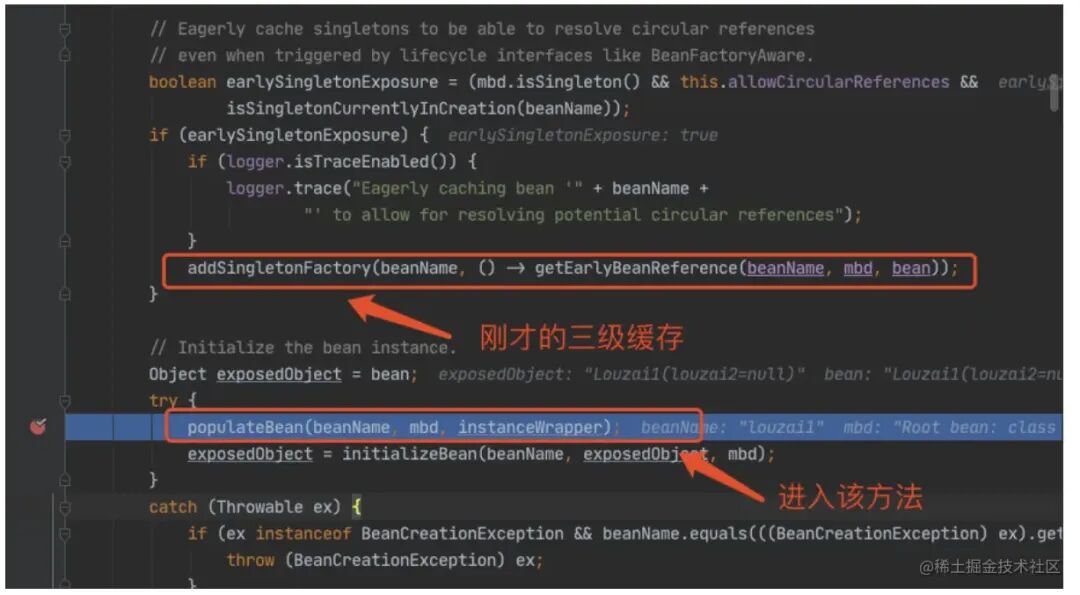
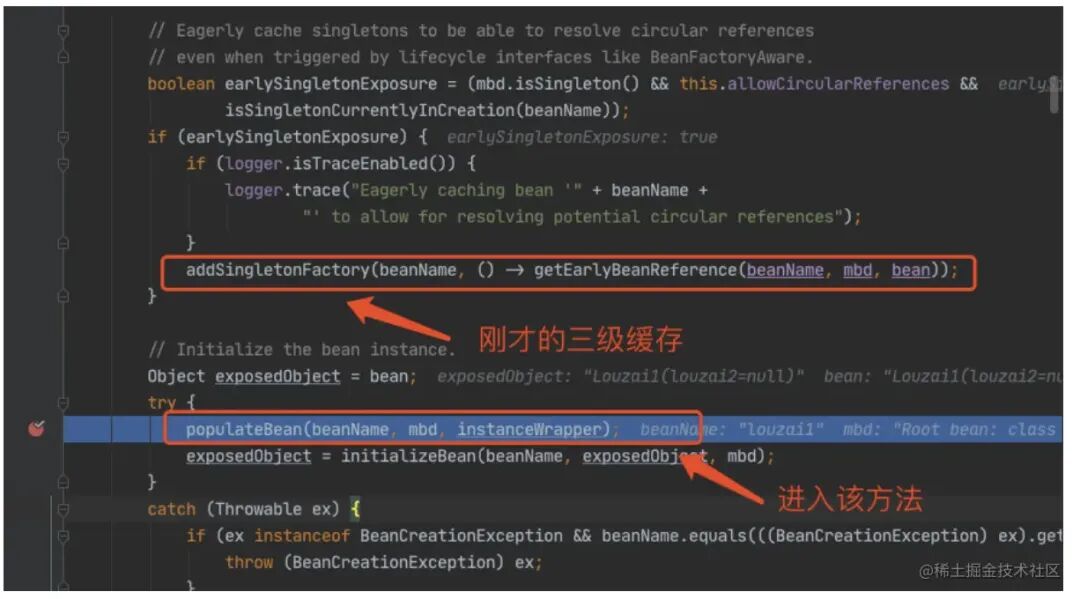
进⼊到 populateBean(),执⾏ postProcessProperties(),这⾥是⼀个策略模式,找到下图的策略对象。
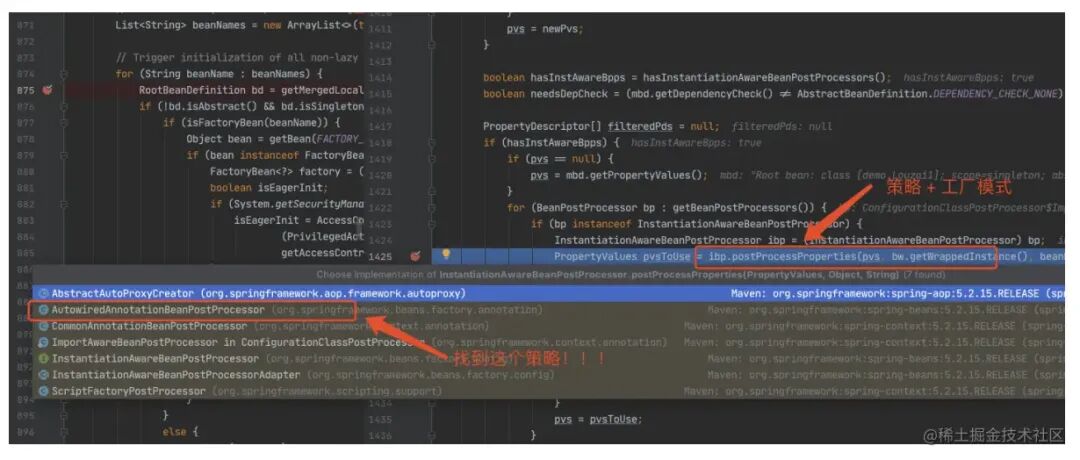
正式进⼊该策略对应的⽅法。
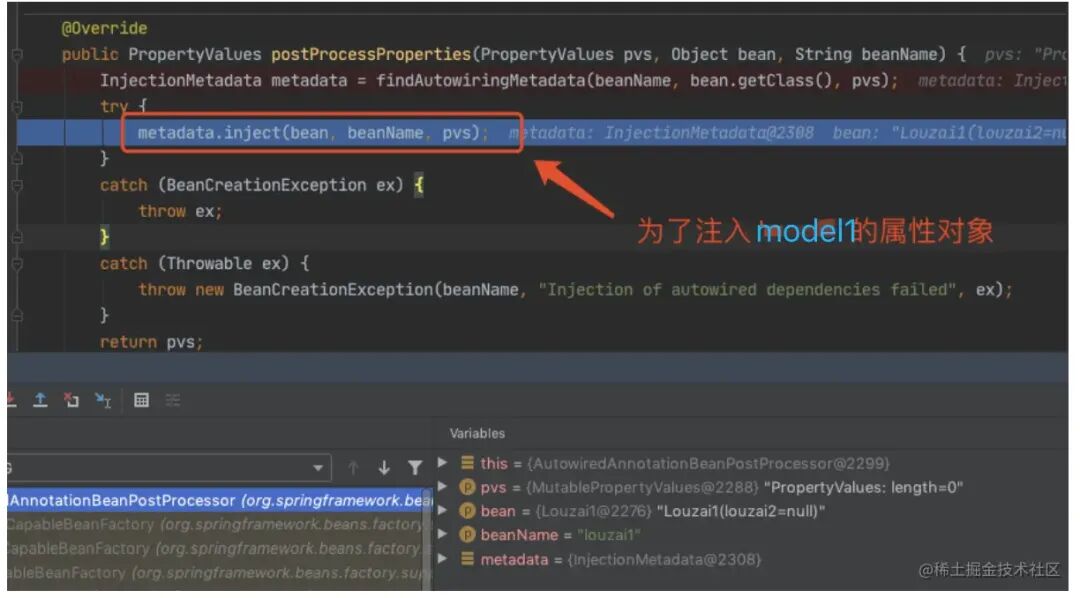
下⾯都是为了获取 model1 的成员对象,然后进⾏注⼊。
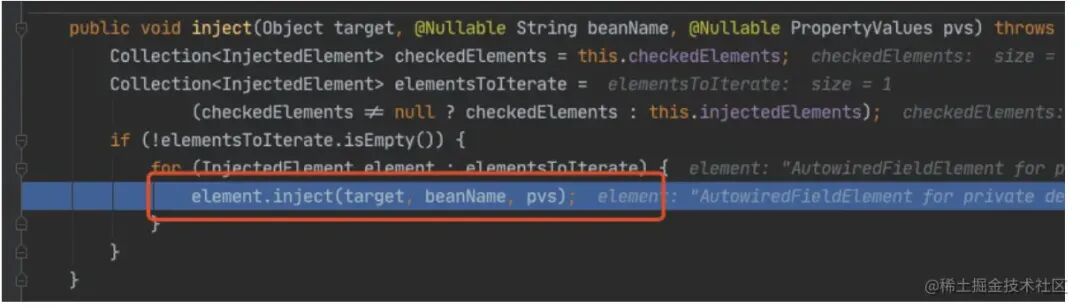
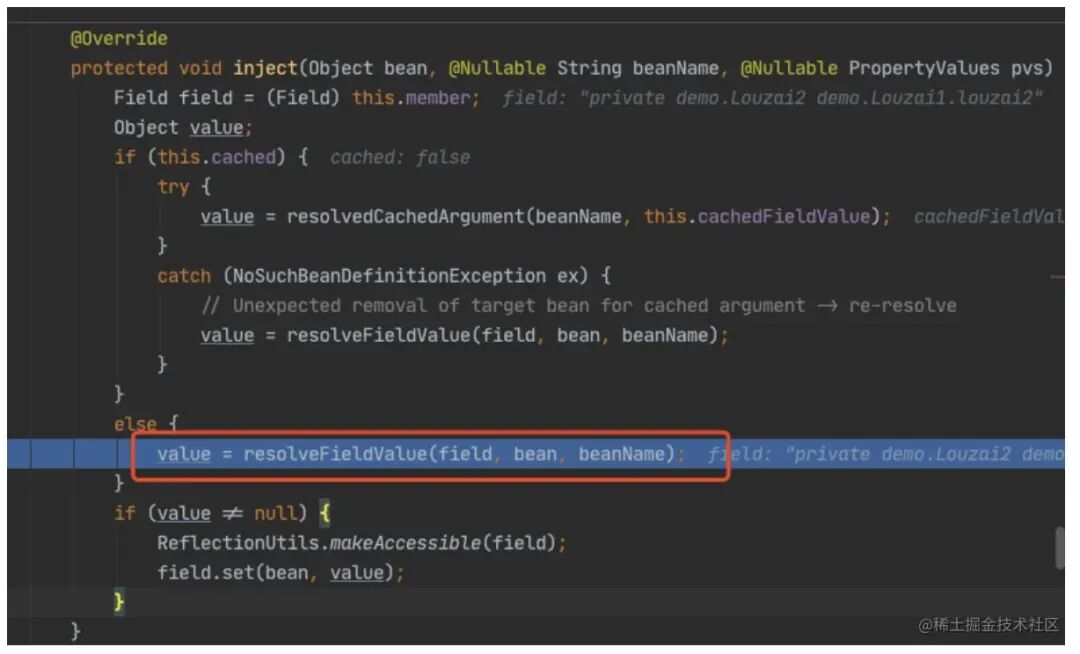
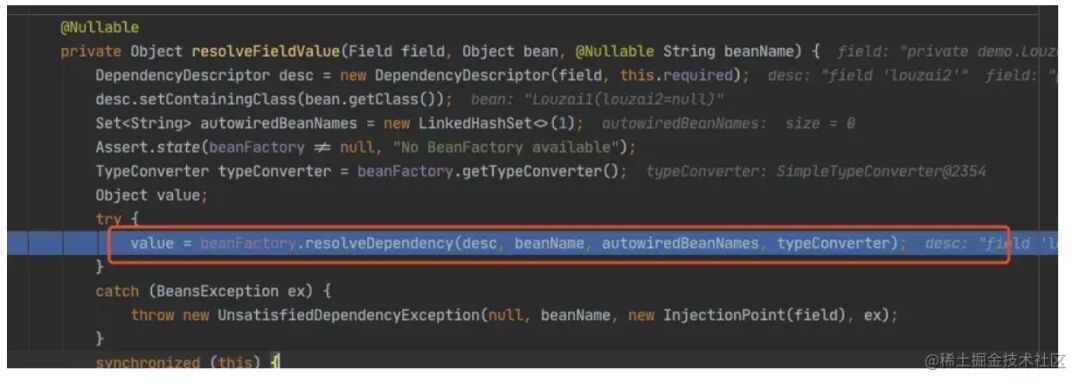
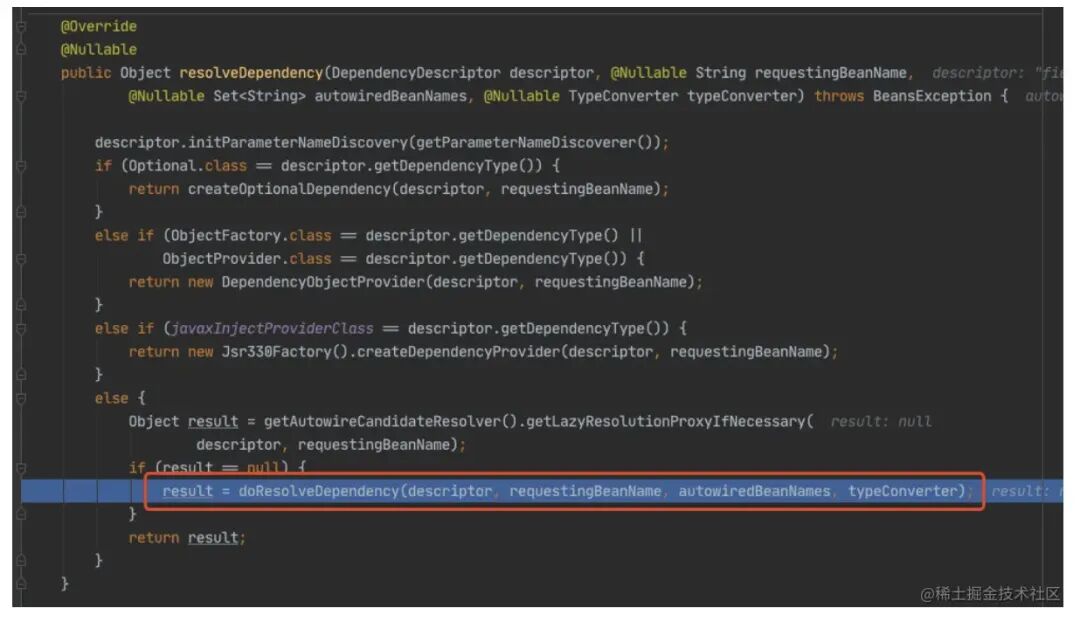
进⼊ doResolveDependency(),找到 model1 依赖的对象名 model2
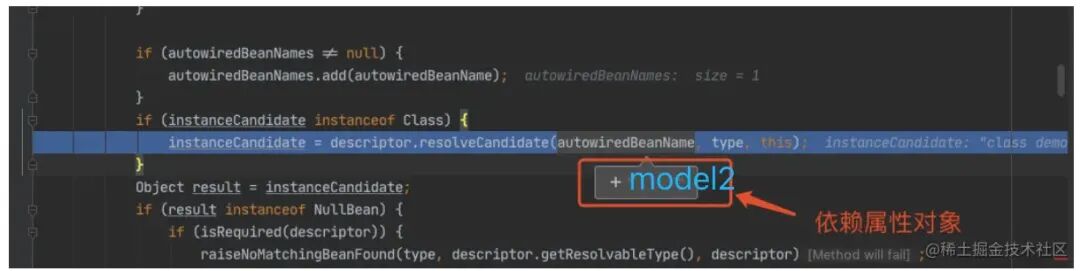
需要获取 model2 的 bean,是 AbstractBeanFactory 的⽅法。
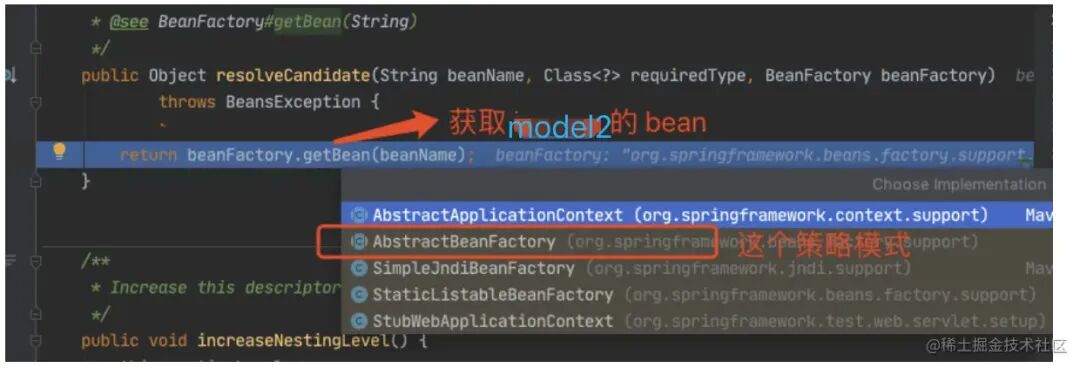
正式获取 model2 的 bean。

到这⾥,第⼀层套娃基本结束,因为 model1 依赖 model2,下⾯我们进⼊第⼆层套娃。
2.3 第⼆层

获取 louzai2 的 bean,从 doGetBean(),到 doResolveDependency(),和第⼀层的逻辑完全⼀样,找到 model2 依赖的对象名 model1。
前⾯的流程全部省略,直接到 doResolveDependency()。
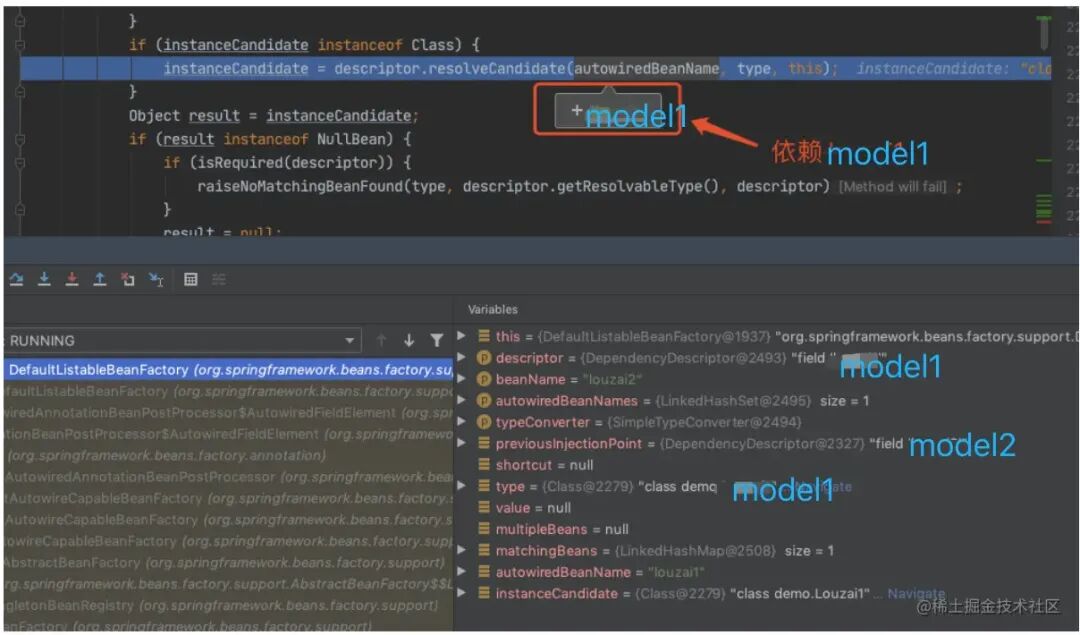
正式获取 model1 的 bean。
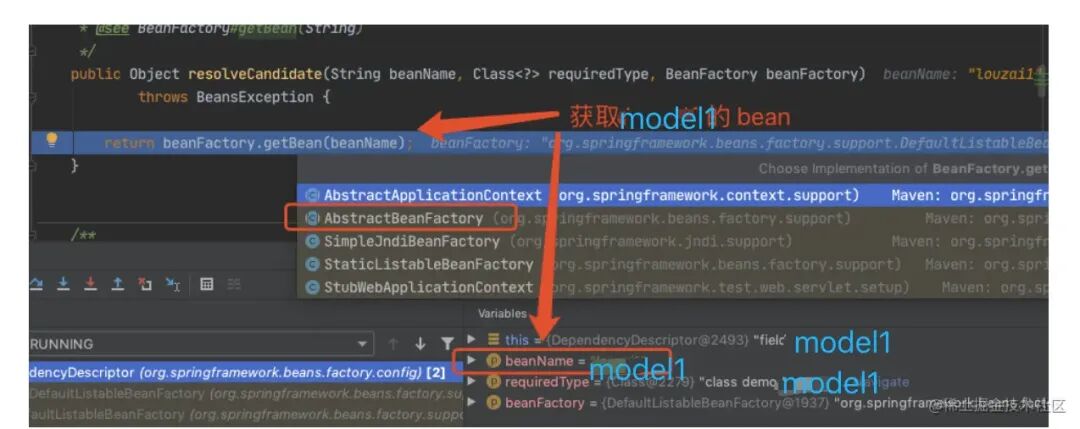
到这⾥,第⼆层套娃结束,因为 model2 依赖 model1,所以我们进⼊第三层套娃。
2.4 第三层

获取 model1 的 bean,在第⼀层和第⼆层中,我们每次都会从 getSingleton() 获取对象,但是由于之前没有初始 化 model1 和 model2 的三级缓存,所以获取对象为空。
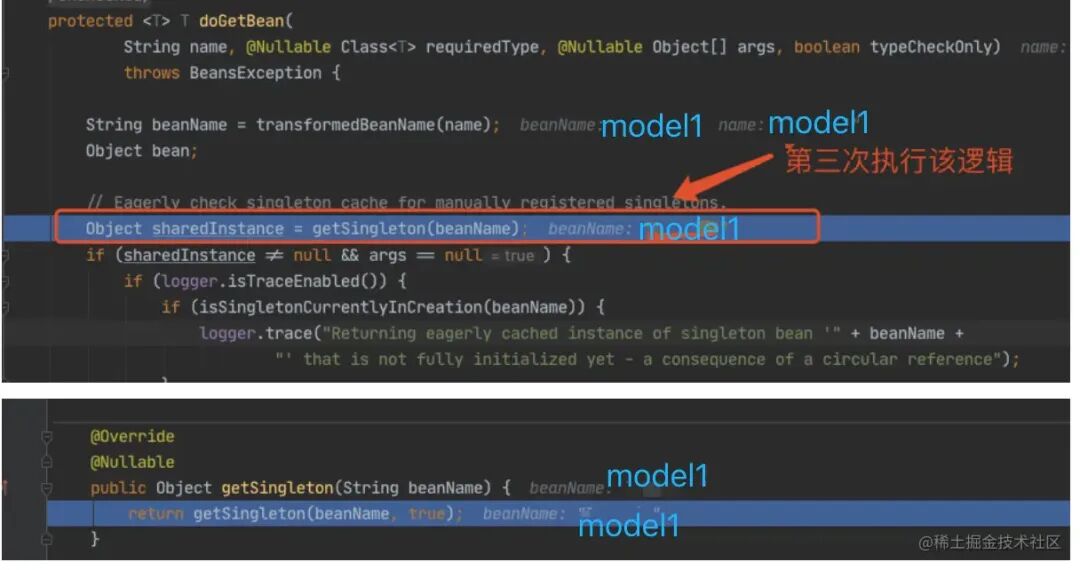
敲重点!敲重点!!敲重点!!!
到了第三层,由于第三级缓存有 model1 数据,这⾥使⽤三级缓存中的⼯⼚,为 model2 创建⼀个代理对象,塞⼊ ⼆级缓存。
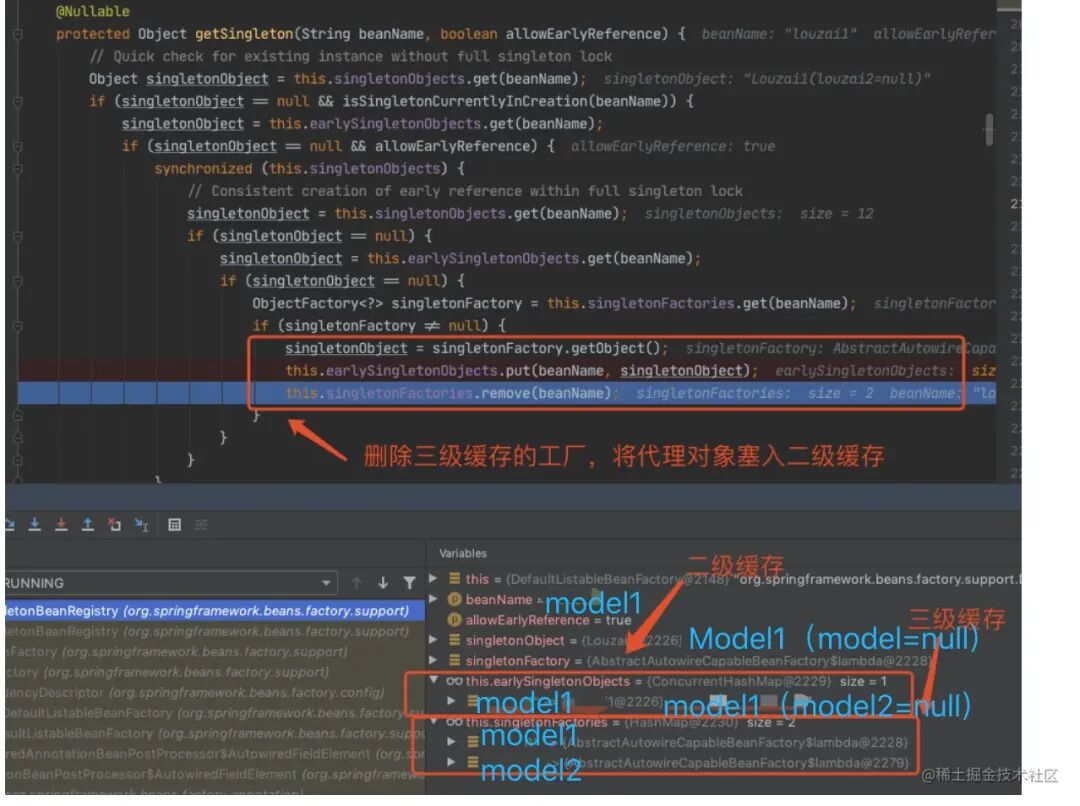
这⾥就拿到了 model1 的代理对象,解决了 model2 的依赖关系,返回到第⼆层。
2.5 返回第⼆层
返回第⼆层后,model2 初始化结束,这⾥就结束了么?⼆级缓存的数据,啥时候会给到⼀级呢?
甭着急,看这⾥,还记得在 doGetBean() 中,我们会通过 createBean() 创建⼀个 model2 的 bean,当 model2 的 bean 创建成功后,我们会执⾏ getSingleton(),它会对 model2 的结果进⾏处理。
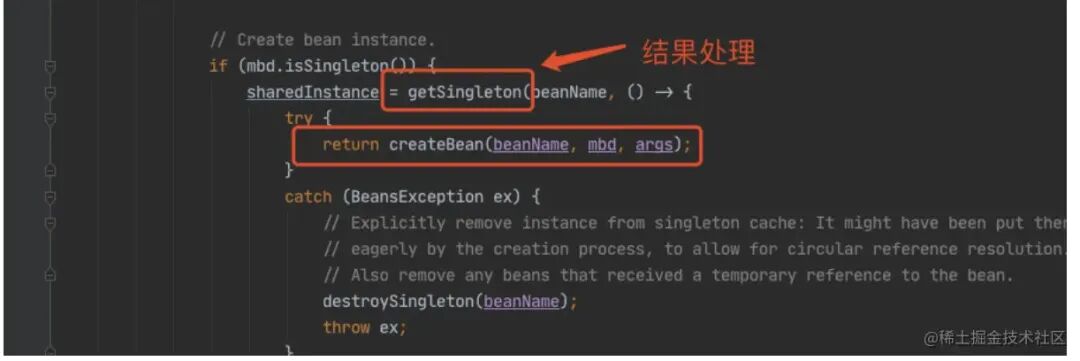
我们进⼊ getSingleton(),会看到下⾯这个⽅法。
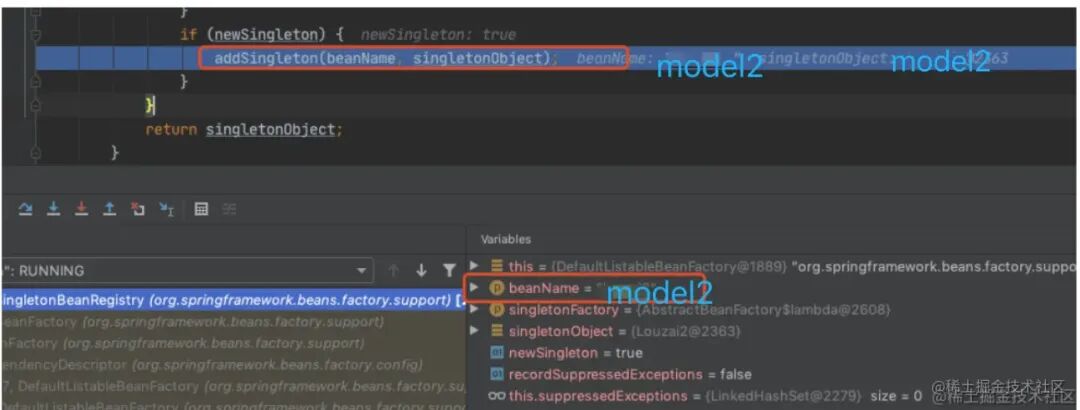
这⾥就是处理 model2 的 ⼀、⼆级缓存的逻辑,将⼆级缓存清除,放⼊⼀级缓存。
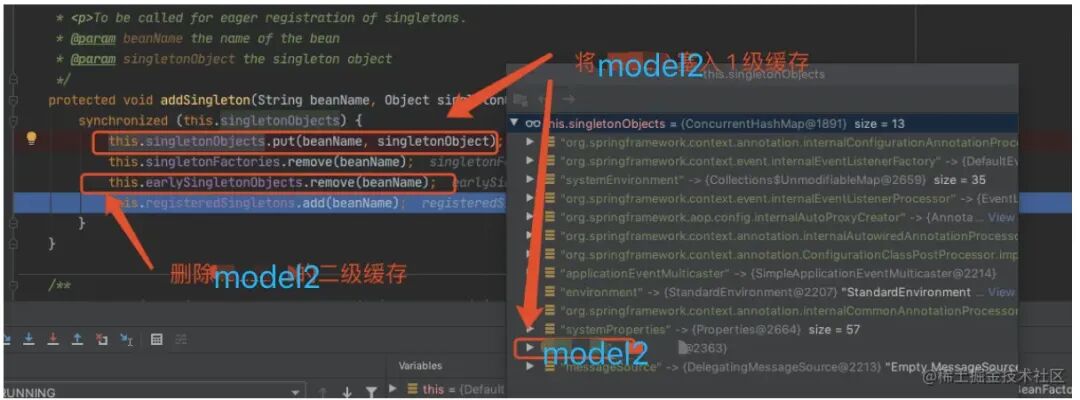
2.6 返回第⼀层
同 2.5,model1 初始化完毕后,会把 model1 的⼆级缓存清除,将对象放⼊⼀级缓存。
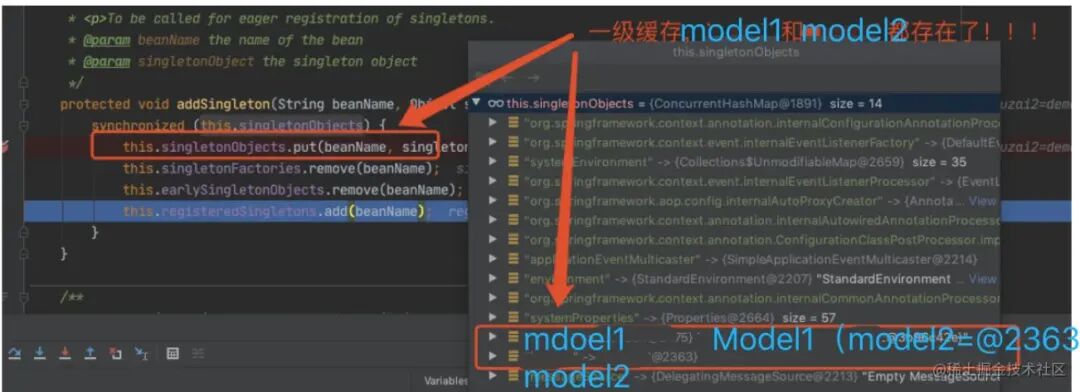
到这⾥,所有的流程结束,我们返回 model1 对象。
三. 原理深度解读
3.1 什么要有 3 级缓存 ?
这是⼀道⾮常经典的⾯试题,前⾯已经告诉⼤家详细的执⾏流程,包括源码解读,但是没有告诉⼤家为什么要⽤ 3 级缓存?
这⾥是重点!敲⿊板!!!
我们先说“⼀级缓存”的作⽤,变量命名为 singletonObjects,结构是 Map,它就是⼀个单例池, 将初始化好的对象放到⾥⾯,给其它线程使⽤,如果没有第⼀级缓存,程序不能保证 Spring 的单例属性。
“⼆级缓存”先放放,我们直接看“三级缓存”的作⽤,变量命名为 singletonFactories,结构是 Map>,Map 的 Value 是⼀个对象的代理⼯⼚,所以“三级缓存”的作⽤,其实就是⽤来存放对象的代 理⼯⼚。
那这个对象的代理⼯⼚有什么作⽤呢,我先给出答案,它的主要作⽤是存放半成品的单例 Bean,⽬的是为了“打破 循环”,可能⼤家还是不太懂,这⾥我再稍微解释⼀下。
我们回到⽂章开头的例⼦,创建 A 对象时,会把实例化的 A 对象存⼊“三级缓存”,这个 A 其实是个半成品,因为没 有完成依赖属性 B 的注⼊,所以后⾯当初始化 B 时,B ⼜要去找 A,这时就需要从“三级缓存”中拿到这个半成品的 A(这⾥描述,其实也不完全准确,因为不是直接拿,为了让⼤家好理解,我就先这样描述),打破循环
那我再问⼀个问题,为什么“三级缓存”不直接存半成品的 A,⽽是要存⼀个代理⼯⼚呢 ?答案是因为 AOP。
在解释这个问题前,我们看⼀下这个代理⼯⼚的源码,让⼤家有⼀个更清晰的认识。
直接找到创建 A 对象时,把实例化的 A 对象存⼊“三级缓存”的代码,直接⽤前⾯的两幅截图。
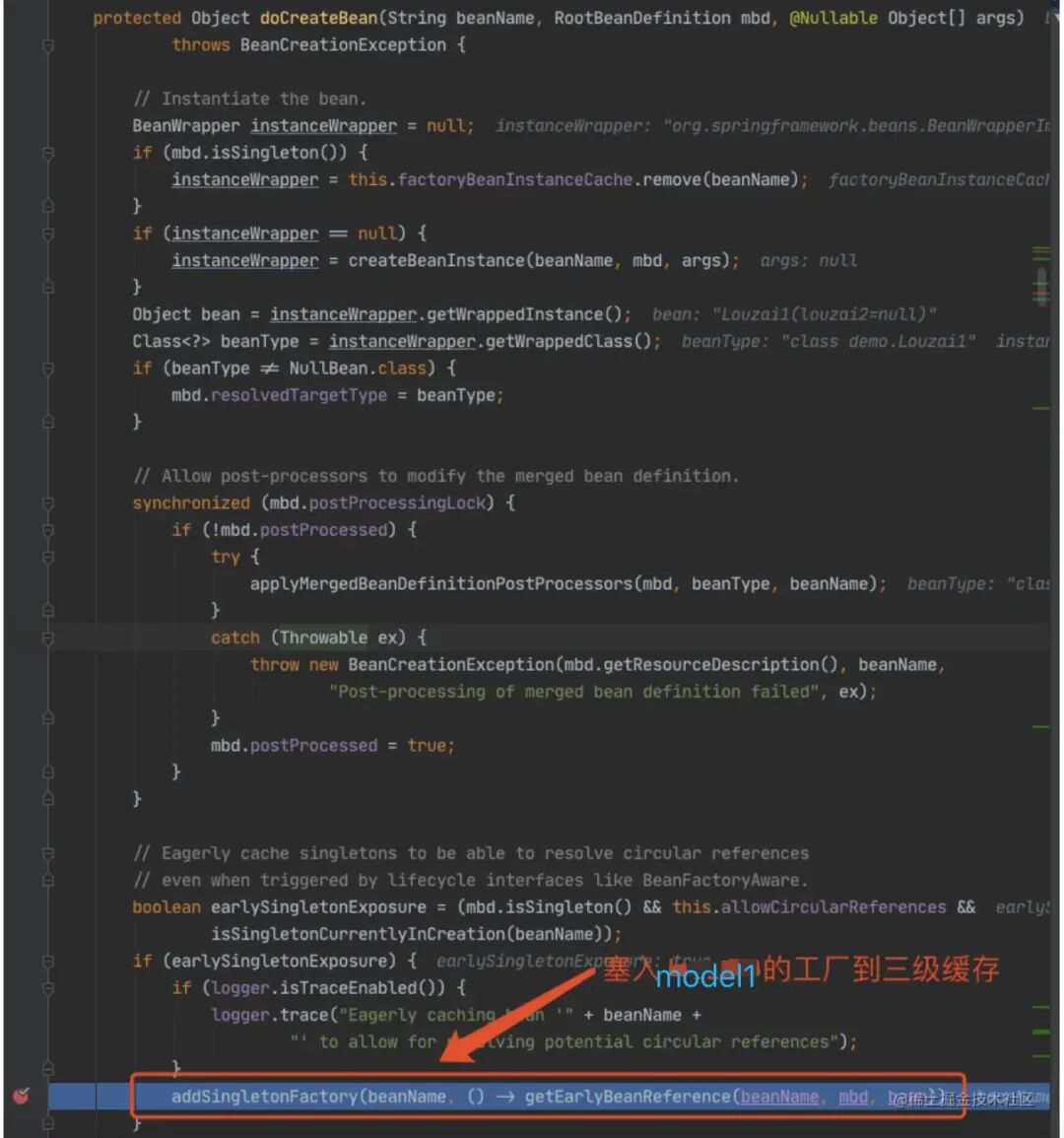
下⾯我们主要看这个对象⼯⼚是如何得到的,进⼊ getEarlyBeanReference() ⽅法。
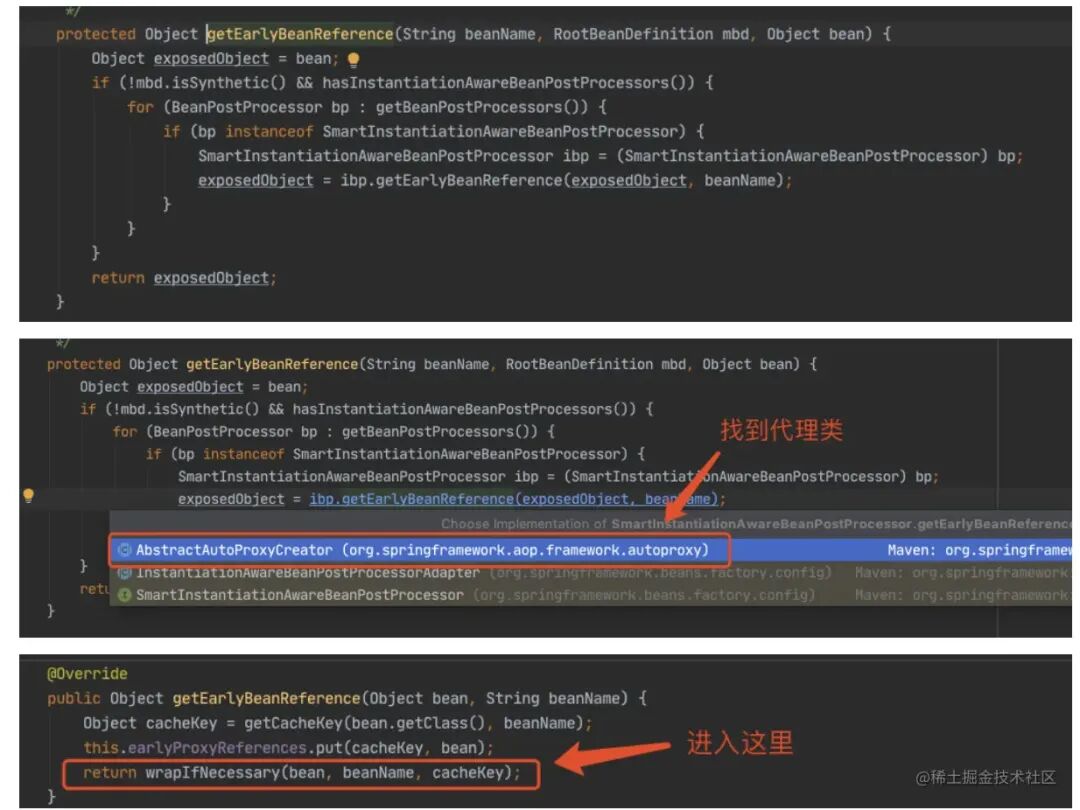
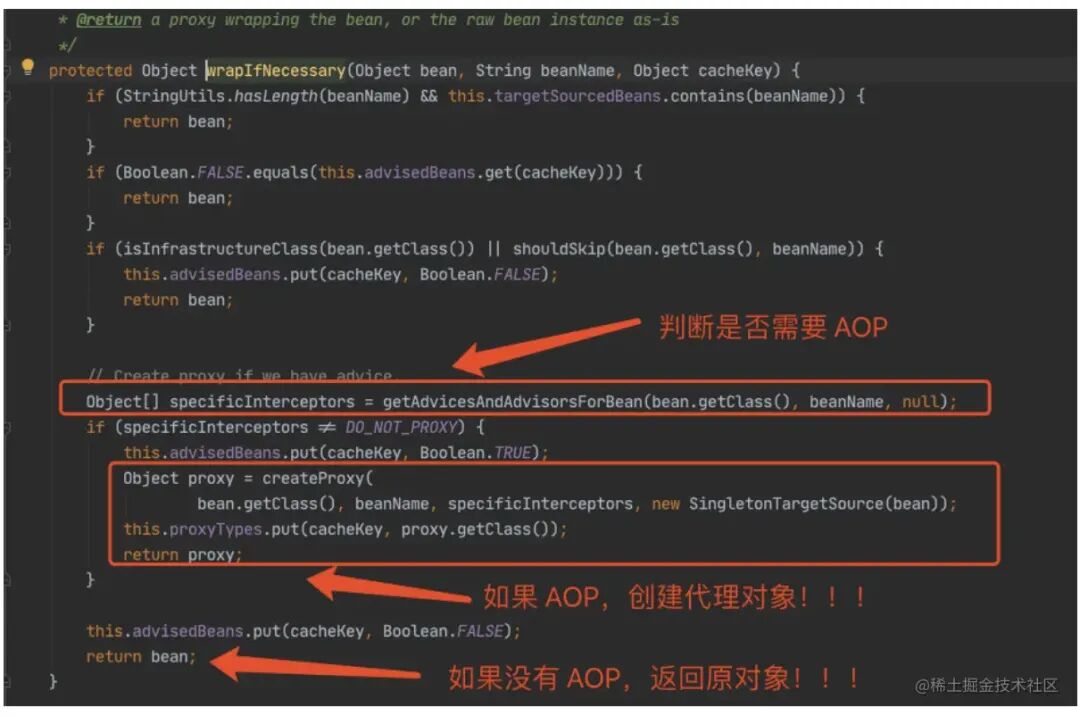
最后⼀幅图太重要了,我们知道这个对象⼯⼚的作⽤:
![]()
如果 A 有 AOP,就创建⼀个代理对象;
如果 A 没有 AOP,就返回原对象。
![]()
![]()
那“⼆级缓存”的作⽤就清楚了,就是⽤来存放对象⼯⼚⽣成的对象,这个对象可能是原对象,也可能是个代理对 象。
![]()
我再问⼀个问题,为什么要这样设计呢?把⼆级缓存⼲掉不⾏么 ?我们继续往下看。
3.2 能⼲掉第 2 级缓存么 ?
@ServicepublicclassA{@Autowiredprivate B b;@Autowiredprivate C c;publicvoidtest1(){}}@ServicepublicclassB{@Autowiredprivate A a;publicvoidtest2(){}}@ServicepublicclassC{@Autowiredprivate A a;publicvoidtest3(){}}
根据上⾯的套娃逻辑,A 需要找 B 和 C,但是 B 需要找 A,C 也需要找 A。
假如 A 需要进⾏ AOP,因为代理对象每次都是⽣成不同的对象,如果⼲掉第⼆级缓存,只有第⼀、三级缓存:
![]()
B 找到 A 时,直接通过三级缓存的⼯⼚的代理对象,⽣成对象 A1。
C 找到 A 时,直接通过三级缓存的⼯⼚的代理对象,⽣成对象 A2。
![]()
看到问题没?你通过 A 的⼯⼚的代理对象,⽣成了两个不同的对象 A1 和 A2,所以为了避免这种问题的出现,我们搞个⼆级缓存,把 A1 存下来,下次再获取时,直接从⼆级缓存获取,⽆需再⽣成新的代理对象。
所以“⼆级缓存”的⽬的是为了避免因为 AOP 创建多个对象,其中存储的是半成品的 AOP 的单例 bean。
如果没有 AOP 的话,我们其实只要 1、3 级缓存,就可以满⾜要求。
4. 总结
我们再回顾⼀下 3 级缓存的作⽤:
![]()
⼀级缓存:为“Spring 的单例属性”⽽⽣,就是个单例池,⽤来存放已经初始化完成的单例 Bean;
⼆级缓存:为“解决 AOP”⽽⽣,存放的是半成品的 AOP 的单例 Bean;
三级缓存:为“打破循环”⽽⽣,存放的是⽣成半成品单例 Bean 的⼯⼚⽅法。
![]()
如果你能理解上⾯我说的三条,恭喜你,你对 Spring 的循环依赖理解得⾮常透彻!
关于循环依赖的知识,其实还有,因为篇幅原因,就不再写了,这篇⽂章的重点,⼀⽅⾯是告诉⼤家循环依赖的 核⼼原理,另⼀⽅⾯是让⼤家⾃⼰去 debug 代码,跑跑流程,挺有意思的。
这⾥说⼀下我看源码的⼼得:
![]()
需要掌握基本的设计模式;
看源码前,最好能找⼀些理论知识先看看;
英语能力,学会读英⽂注释,不会的话就百度翻译;
debug 时,要克制⾃⼰,不要陷⼊⽆⽤的细节,这个最重要。
![]()
其中最难的是第 4 步,因为很多同学看 Spring 源码,每看⼀个⽅法,就想多研究研究,这样很容易被绕进去了, 这个要学会克制,有全剧意识,并能分辨哪⾥是核⼼逻辑,⾄于如何分辨,可以在⽹上先找些资料,如果没有的话, 就只能多看代码了。

















 6737
6737

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









