




 本文详细介绍了MySQLInnoDB引擎中的undolog日志,包括其概念、在事务回滚和MVCC中的作用,以及undolog的生成时机、存储位置和结构。还通过实战案例解析了事务回滚的过程和MVCC的工作原理。
本文详细介绍了MySQLInnoDB引擎中的undolog日志,包括其概念、在事务回滚和MVCC中的作用,以及undolog的生成时机、存储位置和结构。还通过实战案例解析了事务回滚的过程和MVCC的工作原理。
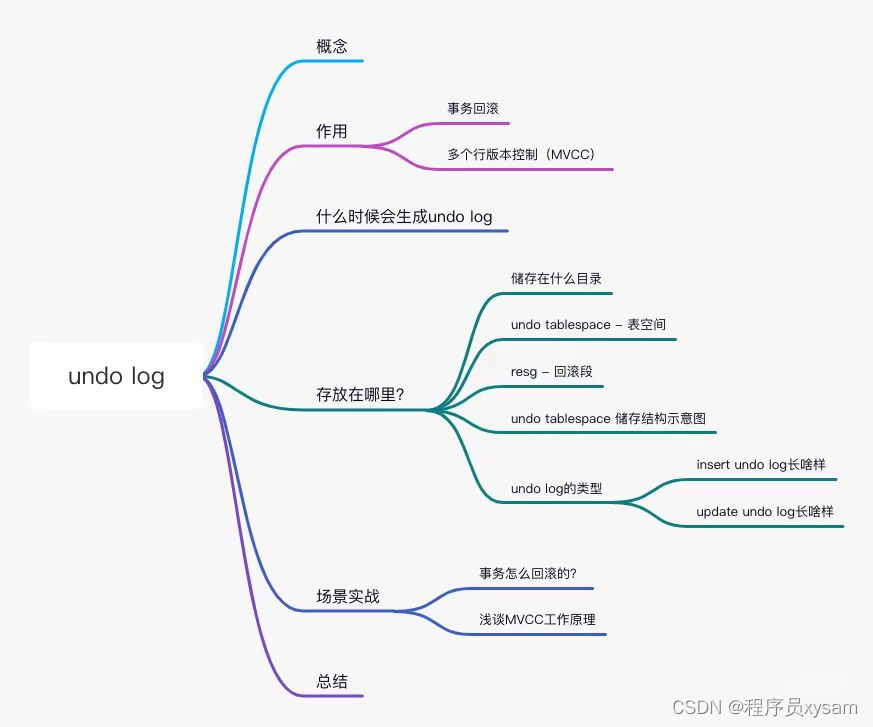
今天这篇文章给大家带来MySQL中另外一个重要的日志 - undo log。
文章导读
概念
undo log是innodb引擎的一种日志,在事务的修改记录之前,会把该记录的原值(before image)先保存起来(undo log)再做修改,以便修改过程中出错能够恢复原值或者其他的事务读取。
作用
从概念的定义不难看出undo log的两个作用:
-
事务回滚 - 原子性: undo log是为了实现事务的原子性而出现的产物,事务处理的过程中,如果出现了错误或者用户执行
ROLLBACK语句,MySQL可以利用undo log中的备份将数据恢复到事务开始之前的状态。 -
多个行版本控制(MVCC)- 隔离性: undo log在MySQL InnoDB储存引擎中用来实现多版本并发控制,事务未提交之前,当读取的某一行被其他事务锁定时,它可以从undo log中分析出该行记录以前的数据是什么,从而提供该行版本信息,让用户实现非锁定一致性读取。
什么时候会生成undo log
在事务中,进行以下四种操作,都会创建undo log:
-
insert用户定义的表 -
update或者delete用户定义的表 -
insert用户定义的临时表 -
update或者delete用户定义的临时表
存放在哪里?
既然是一种日志,储存在什么目录? 又是怎样储存的?
储存在什么目录?
这里要需要说明一下,在MySQL5.6.3之前的版本中,这个undo tablespace是和system tablespace系统表空间存放在一起的,也就是没有单独的undo log文件,直接存放在ibdata1文件里边,在MySQL5.6.3之后的版本中,MySQL支持将undo log tablespace单独剥离出来,但这个特性依然很鸡肋:
-
要在安装数据库的时候,就指定好独立undo tablespace,在安装完成后不可更改;
-
undo tablespace的space id必须从1开始,无法增加或者删除undo tablespace;
特意安装了MySQL5.6.39验证一波:

到了MySQL5.7版本,终于引入期待已久的功能:即在线truncate undo tablespace(解决了第一个鸡肋点,可以在安装数据库之后更改undo tablespace)
在MySQL8.0中,InnoDB再进一步,对undo log做了进一步的改进:
-
从8.0.3版本开始,默认undo tablespace的个数从0调整为2,也就是在8.0版本中,独立undo tablespace被默认打开。修改该参数为0会报warning并在未来不再支持;
-
无需从space_id 1开始创建undo tablespace,这样解决了In-place upgrade或者物理恢复到一个打开了Undo tablespace的实例所产生的space id冲突。不过依然要求undo tablespace的space id是连续分配的;
根据官方的MySQL结构图,我画了MySQL的结构简图,描述了undo log在数据库磁盘中的位置,只需要关注简图中画红色方框和绿色方框的模块。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1596
1596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









