



 文章讲述了如何在网站结构变化后,利用BeautifulSoup和requests库更新爬虫,抓取热门小说《遮天》的章节内容。作者介绍了爬虫环境设置、头信息获取、页面内容抓取和格式处理等关键步骤。
文章讲述了如何在网站结构变化后,利用BeautifulSoup和requests库更新爬虫,抓取热门小说《遮天》的章节内容。作者介绍了爬虫环境设置、头信息获取、页面内容抓取和格式处理等关键步骤。
有朋友反馈说,以前的一篇关于书籍爬虫的文章过于陈旧了,里面的网站打不开了,不能正常爬取想看的小说了。
晓晓抽时间看了一下,确实网站换了,即使换了新的网站,爬取的小说格式也乱了。以下是原文章:
没想到还有人关注这个小说的爬取,一看就是喜欢看书的人。那么本次就在新的环境下更新一版本。
本次仍使用BeautifulSoup库,它在爬虫的领域仍是经常被使用到的一个强大的工具。
它是一个用于解析HTML和XML文档的Python库,它能够帮助我们从网页中提取数据,或者对HTML进行修改和操作。BeautifulSoup提供了简单且Pythonic的API,使得我们可以轻松地遍历和搜索文档树。
环境:
Pycharm
Python 3.9.16
安装:
pip install requests==2.31.0
pip install beautifulsoup4==4.12.2
注:爬虫需要的包,没有的话可以去自行下载。直接用pip安装即可。
导入:
import os
import re
import requests
import time
from bs4 import BeautifulSoup
1 网站地址
首先,先确定新的网站地址
book_url = 'https://www.biquke.vip/book/200/' # 本次以《遮天》书链接
book_name = '遮天'
再确定爬取书籍的链接和书名,最近比较火的动漫《遮天》在播,笔趣阁中看到了同名小说,就爬取这个了。
注:如果爬取其他书箱,需要变更链接book_url和书名book_name即可
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'
}
2 头信息
头信息,即headers信息
headers = {` `'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'``}
(左右滑动查看完整代码)
headers可以在浏览器中获取,打开浏览器,按下F12键,输入网站链接,在Network中可以看到。
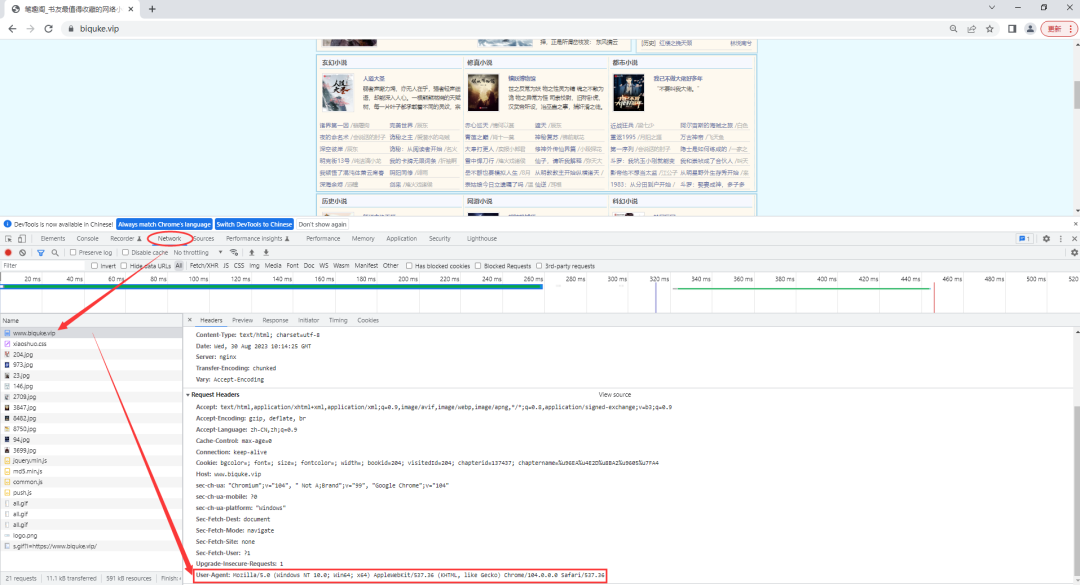
3 书籍页面
通过书籍的url获取页面的内容,这个是书籍页面的信息
# 获取书箱页面内容
html_content = requests.get(book_url, headers=headers)
html_content.raise_for_status()
result = html_content.text
print(result)
结果:

4 章节链接
将每个章节的url都获取到,并保存在一个list中。
# 获取文章正文章节
soup = BeautifulSoup(result, 'html.parser')
body_title = soup.find_all('div', id='list')[1]
dd_msg = body_title.find_all('dd')
# 获取章节的链接,并保存到列表中
urls = re.findall(r'a href="(.*?)"', str(dd_msg))
url_list = []
for i in urls:
if 'https' in i:
continue
url_list.append(i)
print(url_list)
结果:

5 书籍所有章节内容
爬取所有章节的内容,并进行格式处理,达到可阅读的标准
# 爬取书箱所有章节内容
article_content_all = ''
for url in url_list:
# 添加一个等待时间
time.sleep(3)
part_url = base_url + url
# 爬取单个章节内容
sub_html_content = requests.get(part_url, headers=headers)
sub_html_content.raise_for_status()
sub_result = sub_html_content.text
soup = BeautifulSoup(sub_result, 'html.parser')
article_title = soup.title.string
# 将章节标题去除固定尾名
try:
article_title = article_title.replace(f"{book_name} - 笔趣阁", "")
except:
article_title = article_title
print(url, "——", article_title + " 下载中…………")
# 获取章节内容
article_content_ = soup.find('div', id='content').text
# 去除章节内容中的一些广告词、制表回车符和空格
article_content = article_content_.replace("\r\n", "")\
.replace("天才一秒记住本站地址:[ 笔趣阁] https://www.biquke.vip最快更新!无广告!", "")\
.replace(" ", "")
article_content = article_title + article_content + "\n"
article_content_all += article_content
爬取代码实现,注重两点,
一是:
加一个等待3s的时间,防止频繁请求网站,被禁止访问!
time.sleep(3)
二是:
内容格式化处理,处理一些广告词、制表回车符和空格。(亲试了多个部书籍,均可统一处理,如后面遇到特殊情况,需要自行修改本部分处理)
try:
article_title = article_title.replace(f"{book_name} - 笔趣阁", "")
except:
article_title = article_title
print(url, "——", article_title + " 下载中…………")
# 获取章节内容
article_content_ = soup.find('div', id='content').text
# 去除章节内容中的一些广告词、制表回车符和空格
article_content = article_content_.replace("\r\n", "")\
.replace("天才一秒记住本站地址:[ 笔趣阁] https://www.biquke.vip最快更新!无广告!", "")\
.replace(" ", "")
article_content = article_title + article_content + "\n"
结果:

6 保存到txt文档
爬取完后,将其保存在当前文件夹下,同名txt文档中
# 写入到txt文档中
file_path = os.getcwd() + "\\" + book_name + "\\"
if os.path.exists(file_path):
path = book_name + "/" + book_name + ".txt"
else:
os.mkdir(file_path)
path = book_name + "/" + book_name + ".txt"
f = open(path, 'w+', encoding='utf-8')
try:
f.write(article_content_all)
f.write("\n")
finally:
f.close()
结果:

7 总结
这个属于静态页面的爬虫,比较简单,现在许多书籍均有电子书版本,多数情况下用不到这种方式,只作个练习吧。
感兴趣的小伙伴,相关源码以及全套Python学习资料,具体看下方。

一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、面试宝典


简历模板
若有侵权,请联系删除


















 659
659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









