




Redis面试题-final
参考:https://blog.youkuaiyun.com/weixin_40205234/article/details/124614720
重点:
单线程模型
redis缓存的雪崩,击穿,穿透
概述
redis==remote dictionary Server,是一个使用c语言编写的,高性能的非关系型数据库
- 关系型数据库:
- 非关系型数据库:
- 基于键值对(可以想象成表中主键和值的关系),不需要进行SQL层的解析,性能无敌
- 数据存储于缓存之中,速度无敌
- 不需要像关系型数据库那样大量的存储空间,价格便宜
redis持久化
RDB(redis dataBase): redis 数据库—》就是内存快照
AOF(Append only file): 文件添加–》就是日志文件
-
为什么需要持久化
- redis对数据的操作都是基于内存的,当遇到了进程退出,服务器宕机等意外情况,如果没有持久化机制,redis里面的数据就会丢失无法回复。有了持久化操作就可以利用之前持久化的文件进行数据恢复
-
持久化机制
-
RDB:把当前数据生成快照保存在硬盘上
-
-
RDB优点:
只有一个dump.rdb文件生成,方便持久化
性能最大化,fork子进程来完成写操作,让主进程继续处理命令,所以是IO最大化,使用单独子进程来进行持久化,主进程不会进行任何IO操作,保证了redis的高性能
相对于数据集大时,比AOF启动效率更高
RDB缺点:
数据安全性低,RDB是间隔一段时间进行持久化,如果持久化之间redis发生故障,会产生数据丢失,所以这种方式更适合数据要求不严格的时候
-
-
AOF:记录每次对数据的操作到单独的日志文件中,恢复的时候直接看日志。(当RDB和AOF同时开启时,默认选择AOF恢复,但是都不设置的时候,默认是RDB)
-
AOF:
优点:数据更加安全,不像RDB会有数据丢失的危险,可以配置某个属性,每次写操作就进行日志插入。
缺点:AOF文件比RDB文件大,且回复速度慢
数据集大的时候,比rdb效率低。
-
-
如何选择持久化方式:
- 如果想要完美的数据安全性,就选用AOF方式
- 如果能够承受数分钟以内的数据丢失,可以使用RDB持久化
过期键的删除策略
key的过期策略同时选择了:惰性过期和定期过期
定时过期:每个设置过期时间的key都要创建一个定时器,到过期时间直接清除。该策略可以立即清除过期的数据,对内存很友好,但是会占用大量的CPU资源去处理。
惰性过期:只有当访问一个key的时候,才会判断该key是否已经过期,过期则清除。
定期过期(上面两种的一种折中方案):每隔一段时间,会扫描一定胡数量的数据库的expires字典中一定数量的key,并清除已经过期的key

内存淘汰策略
- 当redis存储的数据集到达一定大小的时候,就会施行数据淘汰策略
- 淘汰策略分类
- 全局的键空间选择性移除
- (最常用的)allkeys-lru:当内存不足以容纳写入新数据时,在键空间中,移除最近最少使用的key
- 设置过期时间的键空间选择性移除
- 不展示了,看不懂
- 全局的键空间选择性移除
redis做内存优化(限制redis的不是cpu和内存,而是网络IO)
- 好好利用hash,list,sort等集合类型数据,因为通常情况下很多小的key-value可以用更紧凑的方式存放到一起,尽可能的使用散列表,散列表使用的内存非常小。
redis单线程模型-(单线程-多路复用IO模型)
-
为什么是单线程模型
-
redis内部使用文件事件处理器 file event handler,这个文件事件处理器是单线程的,所以redis才叫做单线程的模型
-
单线程优点
- 单线程更容易维护
- 多线程会存在死锁,线程上下文切换等问题,甚至会影响性能
-
文件事件处理器详解
-
文件事件处理器包含 套接字(理解为多个客户端即可) IO多路复用程序,文件事件分派器,以及事件处理器
-

-
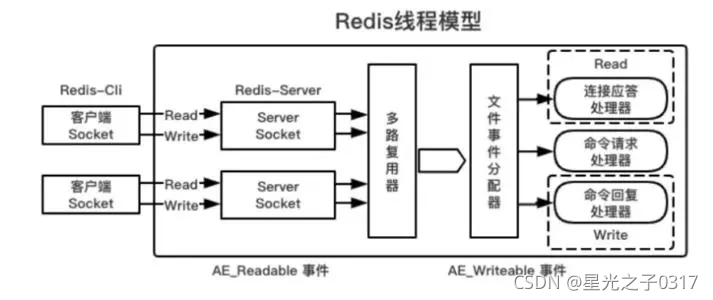
-
工作原理:
IO多路复用程序负责监听多个套接字,并向文件事件分派器传送了那些产生了事件的套接字,尽管多个文件事件会并发的出现,但是IO多路复用程序总会将所有产生事件的套接字都入到队列里面,
-
redis缓存名词(下图好好理解!)
- 击穿就是击穿了某个热点数据
- 穿透就是穿透了整个缓存层面
- 缓存雪崩:大量缓存数据同时过期/redis故障,导致大量请求全部访问数据库,导致数据库宕机。
- 缓存击穿:缓存中的某个热点数据(不是大量数据哦,就是某一个或者某几个热点数据)过期了,然后大量请求访问数据库,但是宕机。
- 可以理解 缓存击穿 为 缓存雪崩 的一个子集
- 缓存穿透:
- 当发生缓存雪崩或者缓存击穿的时候,数据库里面都是存在那些数据的,一旦缓存恢复相应的数据后,就可以减轻数据库的压力,而缓存穿透就不一样了,缓存穿透就是用户访问的数据既不在缓存里面也不在数据库中
- 缓存和数据库都没有用户想要的数据,大量请求一来,数据集不就崩了么

redis缓存对应解决办法
互斥锁方案:当业务线程处理请求的时候,如果发现访问的数据不在redis里面,加个互斥锁,保证同一时间里面只有一个请求来构建缓存(即从数据库读取数据,再将数据更新到redis里),当缓存构建完成后再释放锁。未能获取互斥锁的请求,要么等待锁释放后重写读取缓存,要么直接返回空值
后台更新缓存策略:业务线程不负责更新缓存,缓存也不设置有效期,让缓存永久有效,并且将更新缓存的工作交给后台线程定时更新
双key策略:对于每个缓存数据使用两个key,存储相同的value,一个主key设置过期时间,另一个备份key不设置过期时间。当业务线程访问不到主key的数据时,就直接返回备份key的缓存数据,然后更新缓存的时候,同时更新主key和备份key
- 缓存雪崩解决办法:
- 均匀设置过期时间
- 互斥锁
- 双key策略
- 后台更新缓存
- 缓存击穿解决办法:
- 互斥锁方案
- 后台更新缓存
- 缓存穿透解决办法:
- 非法请求的限制
为什么单线程模型也这么快
- 纯内存操作
- 核心是基于非阻塞的IO多路复用机制
- 虽然文件事件处理器以单线程方式运行,但通过使用IO多路复用程序来监听多个套接字,文件时间处理器既实现了高性能的网络通信模型,又可以很好的与redis服务器中其他同样以单线程方式运行的模块进行对接,保持了redis单线程设计的简单性。
redis集群如何保证数据一致?
主从复制+读写分离
一类是主数据库,一类是从数据库,主数据库可以进行读写操作,当发生写操作的时候自动将数据同步到从数据库,而从数据库一般是只读的,并接受主数据库同步过来的数据,一个主数据库可以有多个从数据库。
Redis后期面试题添加:
1. redis的五种数据结构
- String:字符串
- Hash:哈希
- List:列表
- Set:集合
- ZSet:有序集合
2. redis的String类型
-
Java语言的字符串是char[]实现的
-
public final class String{ private final char value[]; private int hash; }
-
-
redis使用SDS(simple dynamic string)封装String
-
struct sdshdr{ unsigned int len; // 标记buf的长度 unsigned int free; //标记buf中未使用的元素个数 char buf[]; // 存放元素的坑 } -
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aW6TVJB7-1666073219460)(D:/Typora_Plus/Typora/ipic/ad018b1bb30479015c921e944ea9431d.png)]
-
在原来只有一个char[]的情况下,新增了已用空间和未用空间的数字
-
为什么不采用c原生的String类型呢? 获取string.length()时候,redis直接o(1),C是o(n)遍历
-
3. 缓存击穿和穿透
- 缓存击穿:是指击穿了缓存层(某热点数据过期)

- 互斥锁:缓存失效的时候,当再来个请求,缓存中查不到,会去获取互斥锁,然后查询sql将结果写入缓存中,最后释放锁。这个过程如果有其他请求来,就等待并且一直尝试重连。
- 缓存穿透:是指穿透了缓存层和数据库层(某个根本不存在的数据)
- 布隆过滤器
- 简要的意思就是:用哈希函数计算出位置,然后填充二进制向量,0代表没有,1代表有。
- 布隆过滤器是一种占用空间很小的一种数据结构,由很长的二进制向量和一组hash映射函数组成。用于检索一个元素是否在一个集合中,空间效率和查询时间都比一般的算法要好得多,缺点是有一点误识别
- 原理:将集合a中的每个元素映射到长度为a的数组b的不同位置,初始化这个数组的时候都为0,映射到一个数就改个1。如果待检查的元素,经过这k个哈希散列函数的映射后,发现其k个位置上的二进制数都为1,这个元素很可能属于集合a,反之,一定不属于集合A。
- 对于上面这条的详细理解就是:布隆过滤器说某个元素存在,他大概率会在。当布隆过滤器说它不在,它一定不在!
- 布隆过滤器
4. redis的集群
见redis的集群建立方式.md
5. redis的分布式锁
详情可见另一篇文章【redis分布式锁】
常见redis的加锁机制
- setnx命令(set if not exist):当不存在再插入
- set命令实现
基础命令介绍
- setnx
127.0.0.1:6379> SETNX test 'try'
(integer) 1
127.0.0.1:6379> get test
"try"
127.0.0.1:6379> SETNX test 'tryAgain'
(integer) 0
127.0.0.1:6379> get test
"try"
- set命令
- setnx其实就是set其中的一种
- 完整set key value [EX seconds] [Px mlliseconds] [NX] [XX]
- redis从2.6.12开始:等同于setnx,setex,psetex
- 其中
- EX:设置键的过期时间单位为秒 ,set key value Ex senond完全等于setex key second value
- PX:设置键的过期时间为毫秒,set key value Px milliSecond完全等于psetex key millisecond value
- NX:只有在键不存在时,才对键进行设置操作,set key value Nx完全等于setnx key value
- XX:只有在键存在的时候,才对键进行操作。
6. redis常用场景
- 网站月度销量排行榜,直播礼物排行榜----zset
- 分布式锁–setnx
- 计数器
7. redis的set和zset
-
set
- 相当于Java中的HashSet(而HashSet内部也是用HashMap实现的),每个value都是null
- 内部键值对的无序,唯一的
-
zset
- 相当于Java中的SortedSet和HashMap的结合体,专业术语叫跳跃列表
- set保证了value的唯一性,另一方面可以给每个value赋予一个score,代表着这个value的权重
-
跳跃列表(skipList)结构
-
https://blog.youkuaiyun.com/mou_it/article/details/113831820
-
普通列表,想要查找某个数据,只能一个一个遍历

-
为了查找方便,可以考虑在链表上建立索引,每两个节点抽取一个上一级当作索引
-

-
在变成上述情况的时候,如果想要查找数字8,就可以在l1层先找到7索引,然后下降到链表层,在链表层继续遍历,就能找到8。这样比直接从原始链表里面查找8,节省了很多步骤(这tm跟mysql的索引原理真的很像)
-
当数据量大的时候,就可以添加多层级,建立多个索引
-
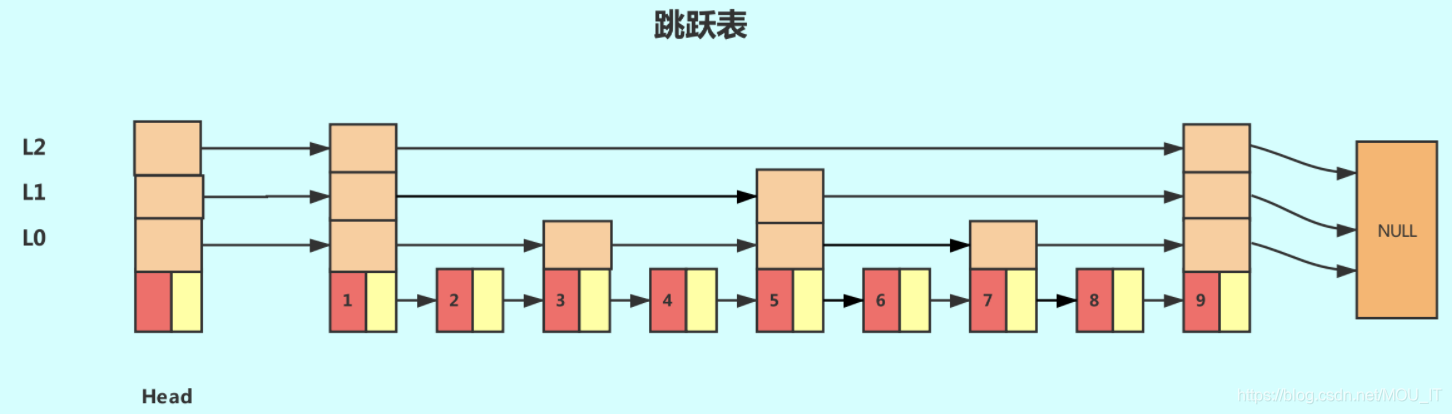
-
struct skipNode { int key; int value; int level; // size表示该节点存在的最高层数 skipNode* *next; //skipNode* 的数组 skipNode(int k, int v, int size) : key(k), value(v), level(size) { next = new skipNode*[size]; } }; class skipList { public: skipList(int, int, float prob = 0.5, int maxNum = 10000); ~skipList(); skipNode* find(const int) const; void erase(const int); void insert(const int k, const int v); protected: // 获得新的level int getNewLevel()const; // 搜索指定key的附近节点 skipNode* search(const int) const; private: float cutOff; // 用于生成新的层级 int levels; // 当前已经分到了多少层 int maxLevel; // 层数上限 int maxKey; // key值上限 int dataSize; // 节点个数 skipNode* headerNode; skipNode* tailNode; skipNode** last; // 因为是单链结构,所以保存查找的节点的前一个节点 };
-
8.分布式锁中redission的使用
- 分布式锁中可能存在锁过期释放,业务没有执行完的问题
- 使用redission实现定时检查锁是否还在,防止锁提前释放
- 只要线程一加锁成功,就会启动一个
watch dog看门狗,它是一个后台线程,会每隔10秒检查一下,如果线程1还持有锁,那么就会不断的延长锁key的生存时间。因此,Redisson就是使用Redisson解决了锁过期释放,业务没执行完问题。
9. 分布式锁中redLock算法
- 如果线程一在Redis的master节点上拿到了锁,但是加锁的key还没同步到slave节点。恰好这时,master节点发生故障,一个slave节点就会升级为master节点。线程二就可以获取同个key的锁啦,但线程一也已经拿到锁了,锁的安全性就没了。
- 为了解决这个问题,Redis作者 antirez提出一种高级的分布式锁算法:Redlock
- 具体实现步骤:
- 获取当前时间,以毫秒为单位
- 按顺序向5个主节点加锁,客户端设置网络链接和响应超时时间,并且超时时间要小于锁的失效时间。如果超时,就跳过该节点,去下一个节点
- 客户端使用当前时间减去开始获取锁时间,得到获取锁使用时间,当且仅当超过一半的redis主节点都获得锁,并且使用时间小于锁失效时间时,锁才算获取成功。
- 如果获取到了锁,就要减去获取锁所使用的时间
- 如果获取锁失败,客户端要在所有的主节点上面解锁。
10.redis的跳跃表

- 跳跃表时有序集合zset底层实现
- 跳跃表支持平均复杂度:o(logn) 最坏复杂度:o(n)
- 跳跃表实现由zskiplist和zskiplistNode两个结构组成,其中zskiplist用于保存跳跃表信息,而zskiplistNode用于表示跳跃表节点
- 跳跃表就是在链表的基础上,增加多级所有提升查找效率
使用时间小于锁失效时间时,锁才算获取成功。
4. 如果获取到了锁,就要减去获取锁所使用的时间
5. 如果获取锁失败,客户端要在所有的主节点上面解锁。
10.redis的跳跃表
- 跳跃表时有序集合zset底层实现
- 跳跃表支持平均复杂度:o(logn) 最坏复杂度:o(n)
- 跳跃表实现由zskiplist和zskiplistNode两个结构组成,其中zskiplist用于保存跳跃表信息,而zskiplistNode用于表示跳跃表节点
- 跳跃表就是在链表的基础上,增加多级所有提升查找效率

















 38万+
38万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









