







一、内存防护背景:数据库查询的潜在风险
Java服务中,数据库查询返回过大数据集可能引发两类风险:
-
结果集字节过大(如单结果集超过20MB)
-
直接导致JVM堆内存飙升
-
频繁触发Full GC甚至OOM崩溃
-
-
结果集行数过多(如单次查询返回10万行)
-
应用层对象转换消耗大量CPU
-
线程阻塞导致接口超时
-
为规避数据库查询返回过大数据集引发的内存风险,需在数据访问对象(DAO)层构建精准的监控与拦截机制,实现对查询结果集规模的有效把控。
MyBatis作为主流ORM框架,能够高效地将数据库操作转化为Java对象操作。其拦截器功能可为内存防护提供理想的解决方案,核心优势包括:
-
无侵入式改造:无需修改原有业务逻辑,通过拦截SQL执行流程嵌入自定义逻辑
-
精准拦截时机:基于MyBatis执行生命周期,可在查询执行前/后灵活融入监控与控制逻辑
这种无侵入式的开发方式,最大程度保障了原有系统的稳定性与可维护性,为系统安全稳定运行保驾护航。
二、MyBatis拦截器:基本原理与自定义实现
2.1 核心原理
MyBatis拦截器采用动态代理模式,在SQL执行关键节点插入自定义逻辑(比如修改 SQL、处理参数、包装结果等), 在不破坏原有代码结构的前提下,对 MyBatis 的核心流程进行改造。
核心原理:4大对象 + 拦截器链
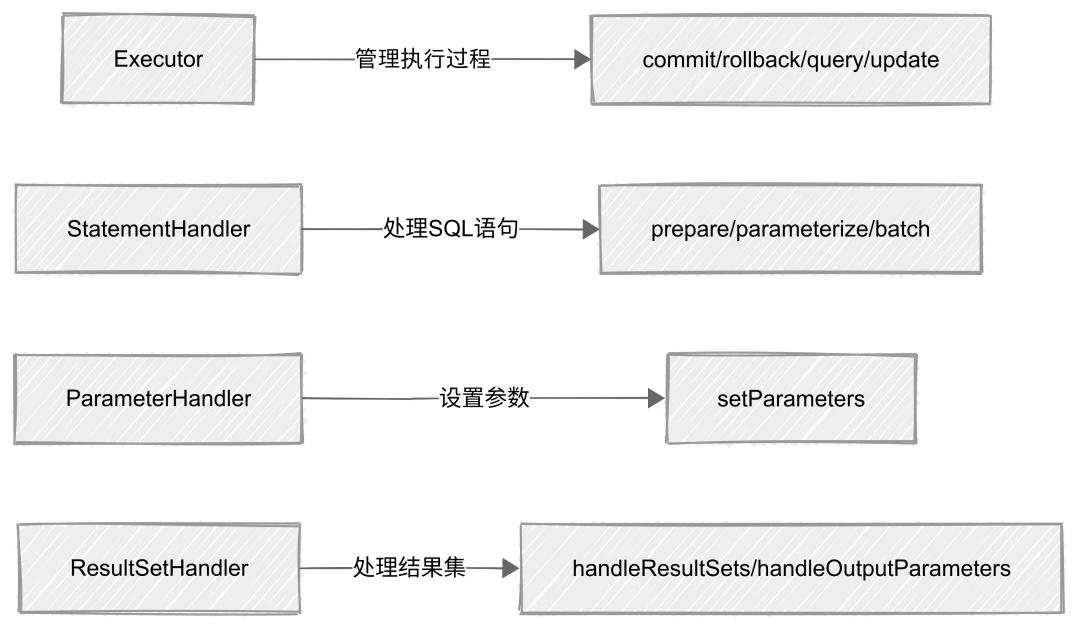
四大核心对象
MyBatis的SQL执行流程依赖四大核心对象:
-
Executor:管理SQL执行的全过程(如 query、update、commit、rollback)。
-
StatementHandler:可以在SQL语句执行之前修改或增强它们。
-
ParameterHandler:可以在将参数设置到SQL语句之前修改或验证它们。
-
ResultSetHandler:可以在将结果集返回给应用程序之前修改或分析它们。
四大核心对象
拦截器链工作机制
拦截器通过拦截四大核心对象的特定方法,形成一条“拦截器链”。当SQL执行到对应节点时,会依次触发链中拦截器的逻辑,就像工厂流水线中增加了自定义质检环节。

2.2 自定义拦截器实现步骤
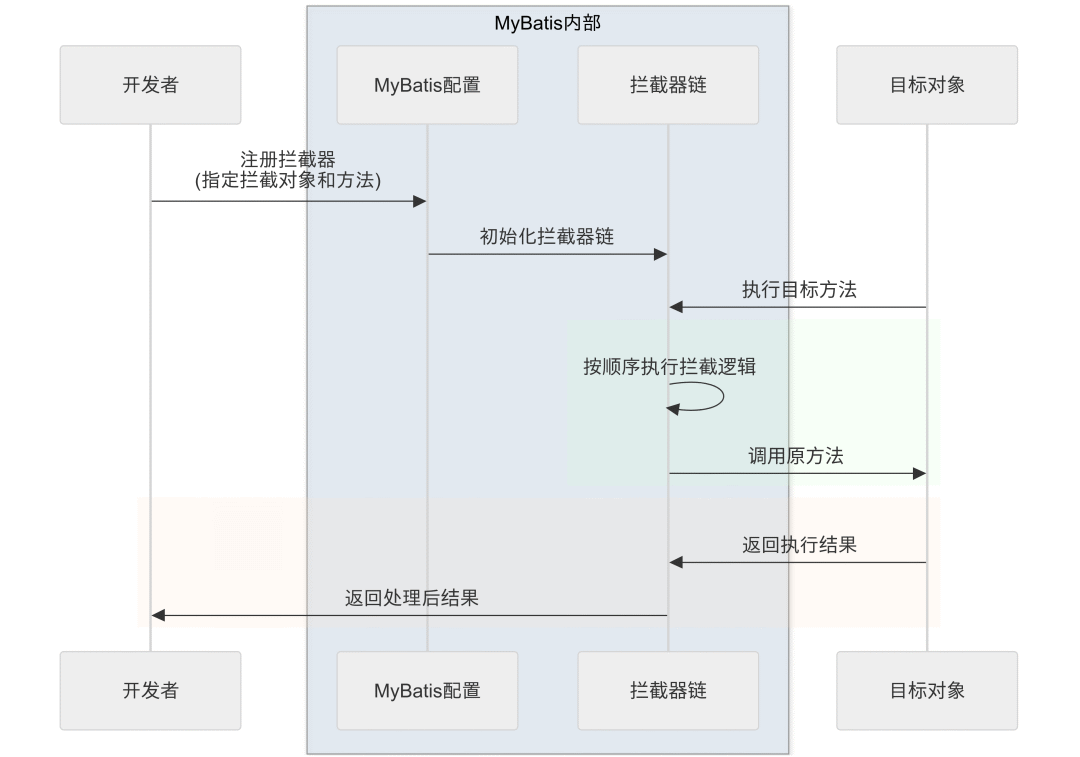
一个拦截器从定义到生效,需要经历三个关键阶段:
-
定义阶段:通过
@Intercepts和@Signature注解声明拦截目标 -
注册阶段:在MyBatis配置文件中配置拦截器
-
执行阶段:当目标方法被调用时,拦截器链按顺序执行拦截逻辑
1. @Intercepts注解声明拦截目标
@Intercepts({
@Signature(type = ResultSetHandler.class,
method = "handleResultSets",
args = {Statement.class})
})
-
type:拦截的四大接口之一(Executor、StatementHandler等) -
method:目标方法名 -
args:方法参数类型
2. 实现Interceptor接口
public class GuardInterceptor implements Interceptor {
@Override
public Object intercept(Invocation invocation) throws Throwable {
// 前置处理
preProcess(invocation);
// 执行原方法
Object result = invocation.proceed();
// 后置处理
postProcess(invocation, result);
return result;
}
}
3. 注册拦截器
在MyBatis配置文件中增加:
<plugins>
<plugin interceptor="com.example.GuardInterceptor">
<property name="maxBytes" value="20971520"/>
</plugin>
</plugins>
2.3拦截器执行时序
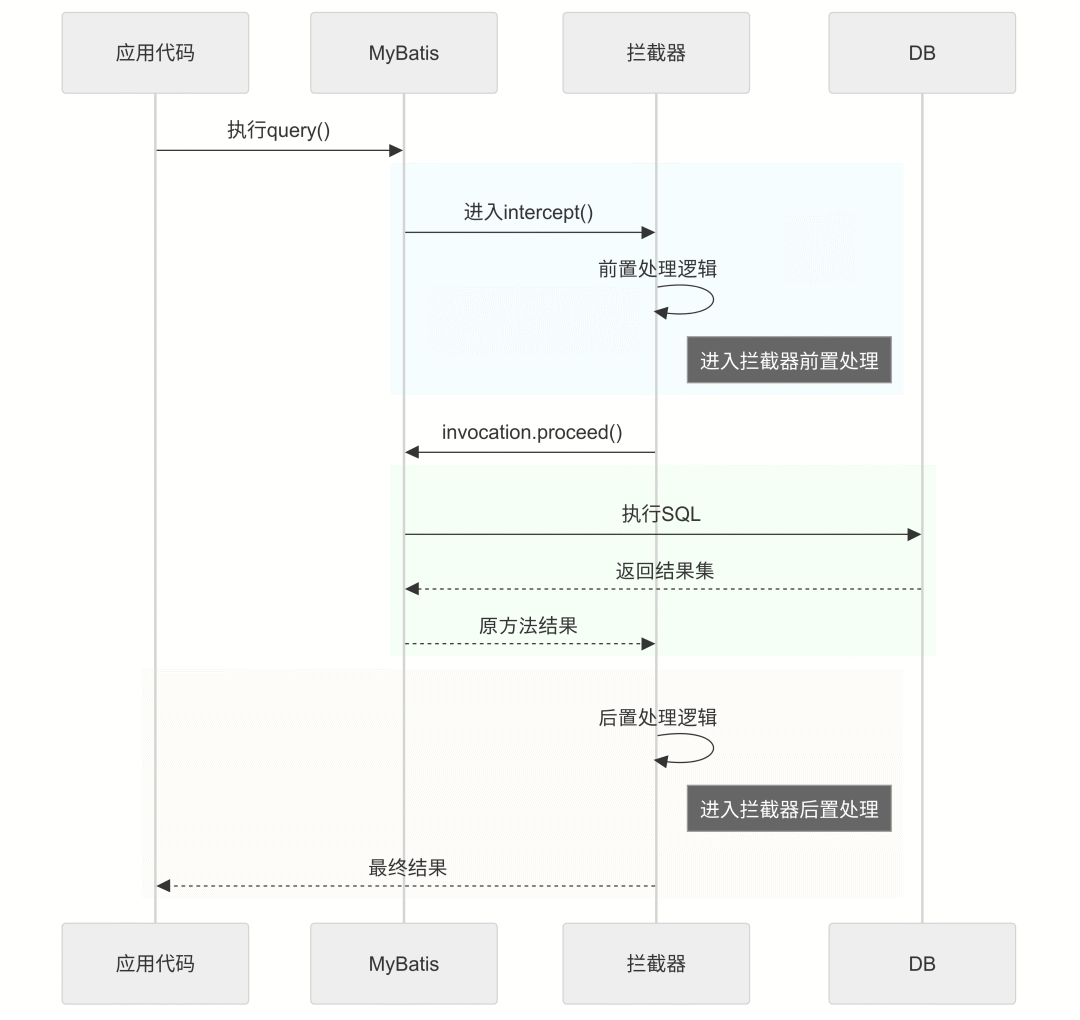
拦截器执行时序
2.4 开发注意事项
性能相关
-
避免在拦截器中做复杂计算
-
结果集分析可采用异步模式
一致性相关
-
拦截器中避免开启新事务
-
写操作拦截需严格测试
三、内存防护方案:基于 MyBatis 拦截器的设计与实践
3.1 方案整体架构
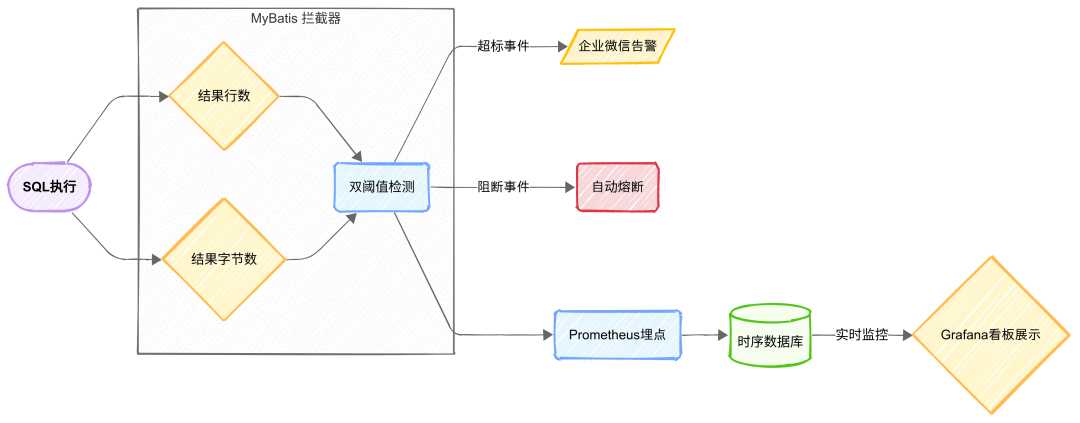
方案整体架构图
3.2 Prometheus埋点设计
metric类型为Histogram类型,Histogram的duration存储SQL查询的耗时,包含三个label:Mapper方法、行数等级、字节数等级。
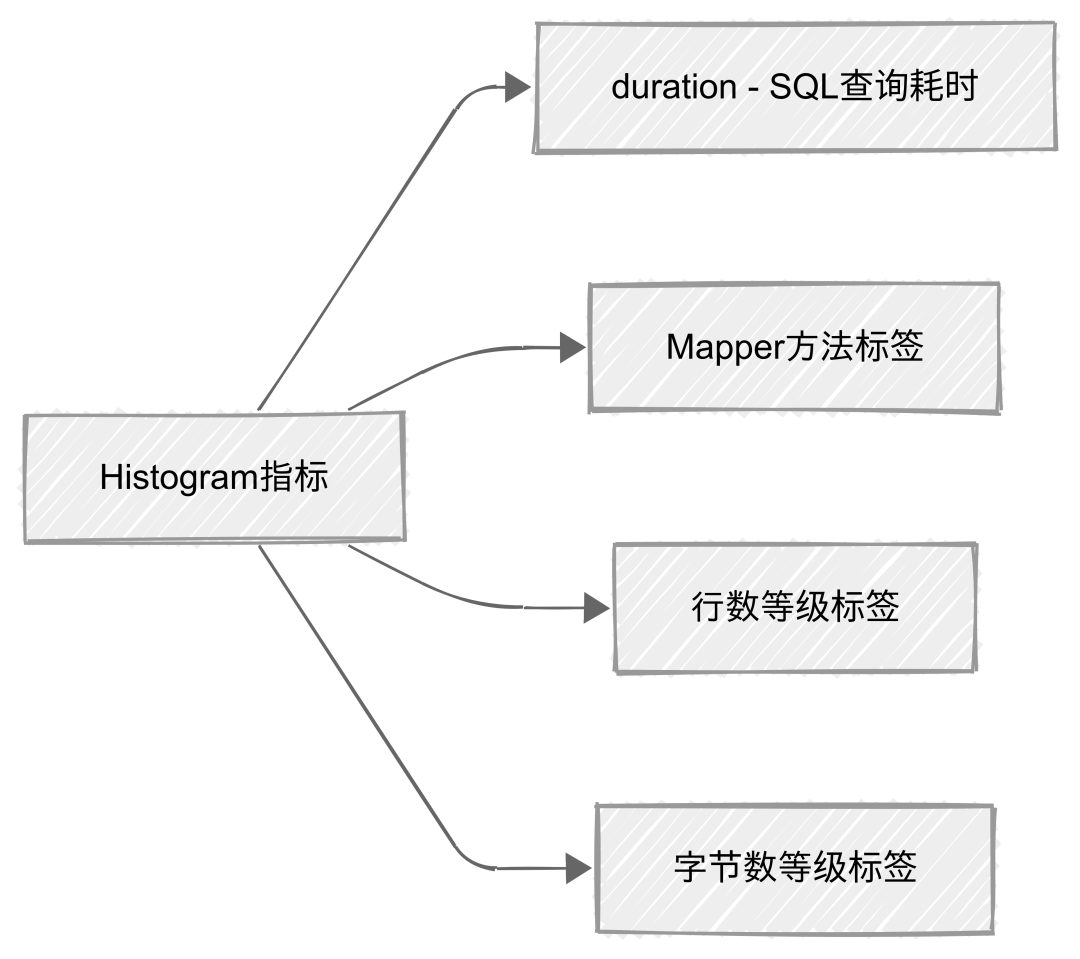
-
Mapper方法:SQL对应的Mapper方法
-
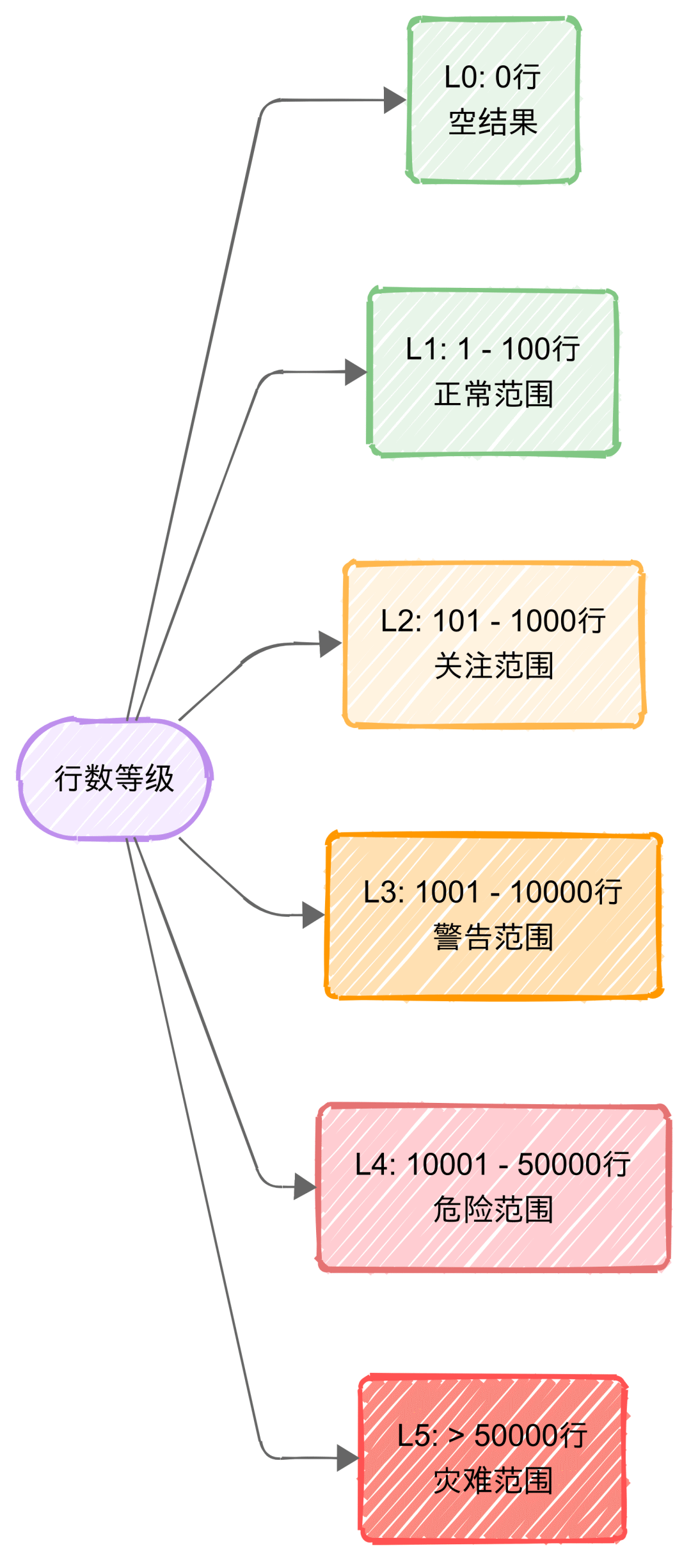
行数等级:结合业务实际场景,将SQL查询结果的行数划分为5级(L0~L5)。
-
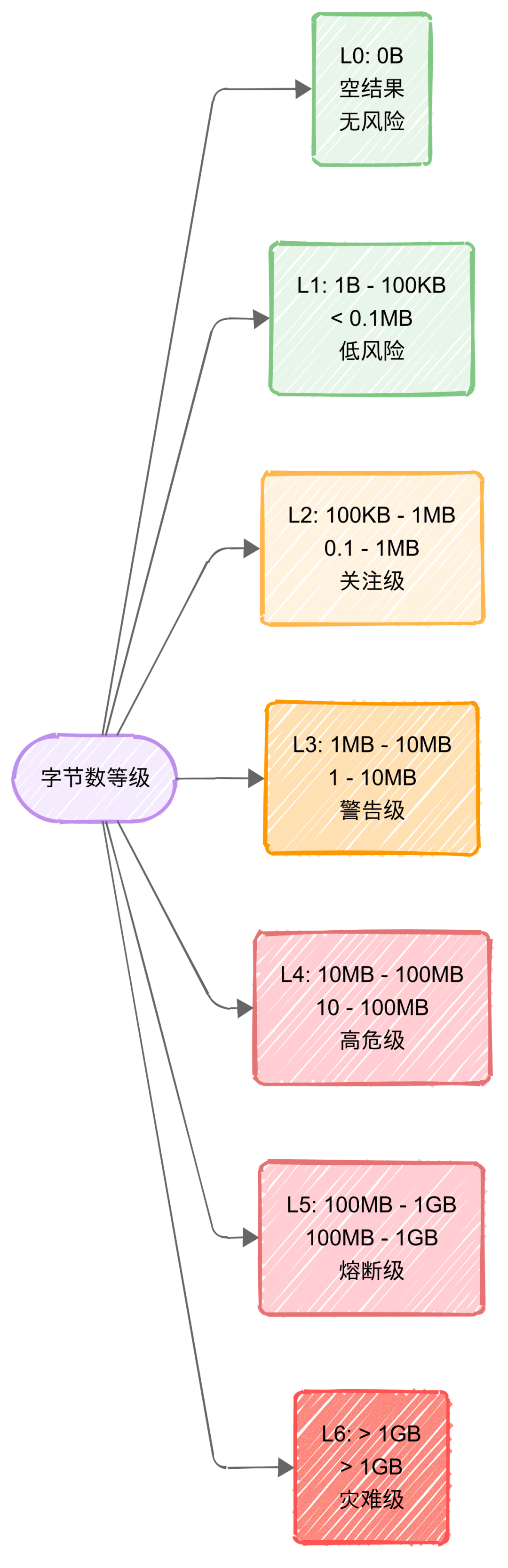
字节数等级:结合业务实际场景,将SQL查询结果的字节大小划分为6级(L0~L6)
不同等级对应不同的风险程度,有助于监控查询结果的数据量对系统的影响。
-
行数等级:
-
聚焦数据量维度
-
有效预防全表扫描
-
核心指标:L3为性能拐点,L4+需强制限制
-
-
字节数等级:
-
聚焦单行数据大小
-
识别大对象问题
-
关键阈值:L3(1MB)为内存警戒线
-
行数等级划分
行数等级划分
字节数等级划分
字节数等级划分
指标定义
public class SqlExecutionMetrics {
// 统一Histogram指标
staticfinal Histogram SQL_QUERY_STATS = Histogram.build()
.name("sql_query_stats")
.help("SQL执行综合统计")
.labelNames("dao_method", "row_level", "byte_level")
.buckets(10, 50, 100, 500, 1000, 5000) // 耗时桶
.register();
// 行数等级映射规则
privatestaticfinalint[] ROW_LEVELS = {0, 100, 1000, 10000, 50000};
// 字节等级映射规则 (单位: KB)
privatestaticfinalint[] BYTE_LEVELS = {0, 100, 1024, 10240, 102400, 1024000};
}
3.3 拦截器执行全流程
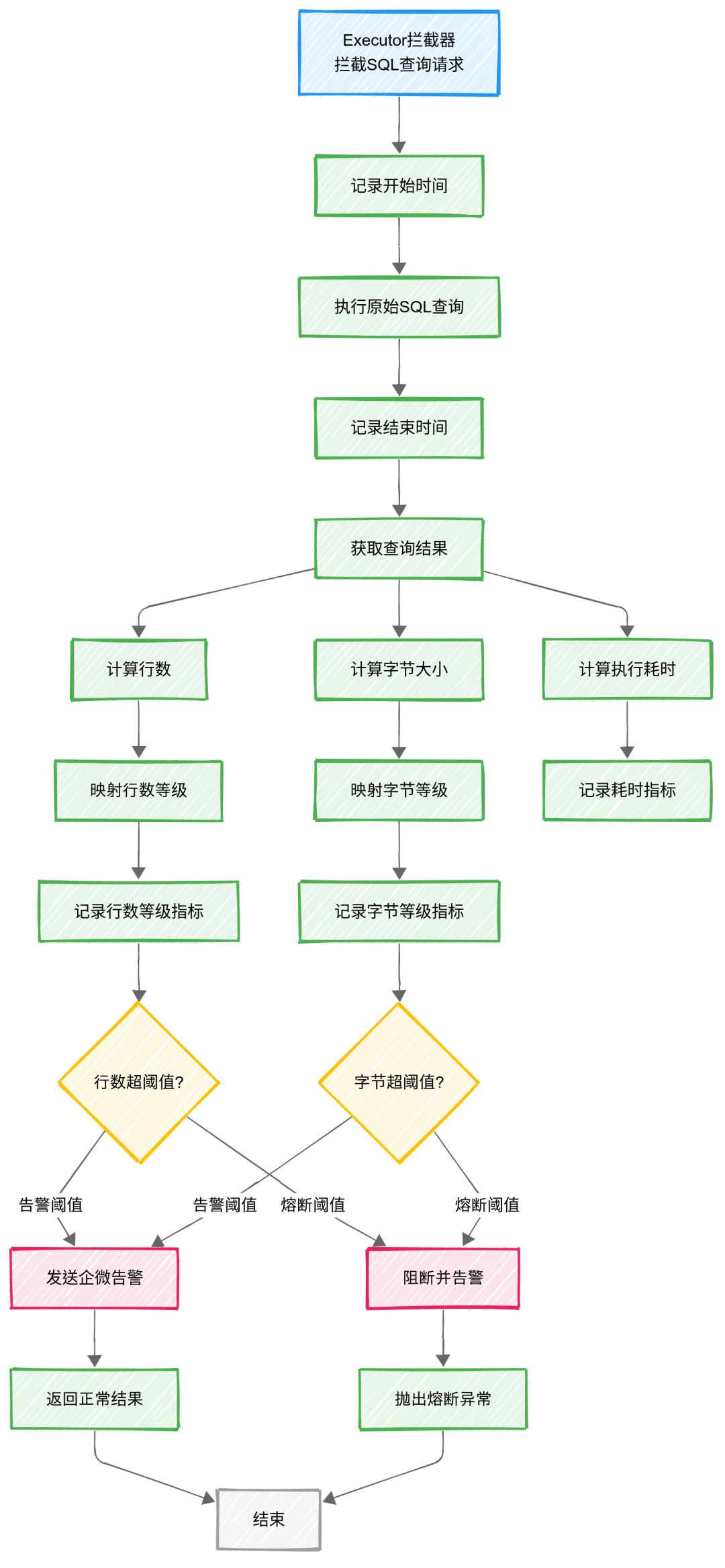
主要通过拦截Executor的query方法,在SQL执行前后嵌入相关逻辑。
3.4 拦截器基础版关键代码
@Slf4j
@Intercepts({
@Signature(type = Executor.class, method = "query", args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class}),
@Signature(type = Executor.class, method = "query", args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class, CacheKey.class, BoundSql.class})
})
public class EnhancedMemoryGuardInterceptor implements Interceptor {
// 双阈值配置
privateint rowWarnThreshold = 3000;
privateint rowBlockThreshold = 10000;
privatelong byteWarnThreshold = 5 * 1024 * 1024; // 5MB
privatelong byteBlockThreshold = 10 * 1024 * 1024; // 10MB
@Override
public Object intercept(Invocation invocation) throws Throwable {
long startTime = System.currentTimeMillis();
// 执行原始SQL
Object result = invocation.proceed();
long endTime = System.currentTimeMillis();
try {
long duration = endTime - startTime;
String sqlId = getSqlId(invocation);
// 结果集行数
int rowCount;
if (result instanceof Collection) {
rowCount = ((Collection<?>) result).size();
} else {
rowCount = result == null ? 0 : 1;
}
// 结果字节数
long byteSize = MemoryMeasurer.measureBytes(result);
// 等级映射
int rowLevel = mapToLevel(rowCount, SqlExecutionMetrics.ROW_LEVELS);
int byteLevel = mapToLevel(byteSize / 1024, SqlExecutionMetrics.BYTE_LEVELS);
// Prometheus埋点
recordMetrics(sqlId, rowLevel, byteLevel, duration);
// 双阈值检测
checkRowThresholds(sqlId, rowCount, duration);
checkByteThresholds(sqlId, byteSize, duration);
} catch (MemoryGuardException e) {
throw e;
} catch (Exception e) {
log.error("EnhancedMemoryGuardInterceptor unknow error", e);
}
return result;
}
// 等级映射算法
private int mapToLevel(long value, int[] thresholds) {
for (int i = 0; i < thresholds.length; i++) {
if (value <= thresholds[i]) {
return i;
}
}
return thresholds.length;
}
// 行数阈值检测
private void checkRowThresholds(String sqlId, int rowCount, long duration) {
if (rowCount > rowWarnThreshold) {
String warnMsg = String.format(
"[行数告警] SQL:%s 返回%d行(阈值:%d) 耗时:%dms",
sqlId, rowCount, rowWarnThreshold, duration
);
// 发送企微告警
WeComAlarm.send(warnMsg);
if (rowCount >= rowBlockThreshold) {
thrownew MemoryGuardException(warnMsg + "\n[已熔断] 超过阻断阈值:" + rowBlockThreshold);
}
}
}
// 字节阈值检测
private void checkByteThresholds(String sqlId, long byteSize, long duration) {
if (byteSize > byteWarnThreshold) {
String warnMsg = String.format(
"[字节告警] SQL:%s 占用%.2fMB(阈值:%dMB) 耗时:%dms",
sqlId, byteSize / (1024.0 * 1024.0),
byteWarnThreshold / (1024 * 1024), duration
);
// 发送企微告警
WeComAlarm.send(warnMsg);
if (byteSize >= byteBlockThreshold) {
thrownew MemoryGuardException(warnMsg + "\n[已熔断] 超过阻断阈值:" +
byteBlockThreshold / (1024 * 1024) + "MB");
}
}
}
// 记录Prometheus指标
private void recordMetrics(String sqlId, int rowLevel, int byteLevel, long duration) {
SqlExecutionMetrics.SQL_QUERY_STATS.labels(sqlId, String.valueOf(rowLevel), String.valueOf(byteLevel))
.observe(duration);
}
}
3.5 查询结果大小统计
计算对象大小的方案:
-
轻量级估算字节大小(基于类型大小映射,累加对象每个字段的字节大小)
-
序列化后获取字节大小(使用ByteArrayOutputStream)
-
JSON序列化获取字节大小(例如使用Jackson)
不同方案对比
|
特性 |
轻量级估算 |
ByteArrayOutputStream |
JSON序列化 |
|---|---|---|---|
| 实现原理 |
基于类型映射的快速计算 |
Java对象序列化为字节流 |
对象转为JSON字符串 |
| 计算方式 |
字段遍历+类型映射 |
完整对象序列化 |
对象转为JSON文本 |
| 性能 |
极高 (纳秒级) |
低 (微秒级) |
中 (微秒级) |
| 精度 |
中等 (估算值) |
高 (精确序列化大小) |
高 (文本字节大小) |
| 内存消耗 |
极低 |
高 |
中高 |
| 适用对象 |
简单POJO/Map |
Serializable对象 |
所有对象 |
| 特殊类型 |
需特殊处理 |
自动处理 |
需自定义序列化 |
| 是否改变对象 |
否 |
否 |
否 |
| 额外依赖 |
无 |
无 |
JSON库(Jackson等) |
在MyBatis拦截器这种性能敏感的场景中,轻量级估算方案明显优于序列化方法,它能以极小的性能开销提供足够准确的大小估算,满足监控和日志记录的需求。
轻量级估算实现
public abstractclass MemoryMeasurer {
/**
* 对象大小计算器接口
*/
@FunctionalInterface
publicinterface SizeCalculator {
long calculate(Object obj);
}
// 类型估算器注册表
privatestaticfinal Map<Class<?>, SizeCalculator> SIZE_CALCULATORS = new ConcurrentHashMap<>();
static {
// 注册基本类型估算器
SIZE_CALCULATORS.put(Byte.class, obj -> 1);
SIZE_CALCULATORS.put(Short.class, obj -> 2);
SIZE_CALCULATORS.put(Integer.class, obj -> 4);
SIZE_CALCULATORS.put(Long.class, obj -> 8);
SIZE_CALCULATORS.put(Float.class, obj -> 4);
SIZE_CALCULATORS.put(Double.class, obj -> 8);
SIZE_CALCULATORS.put(Boolean.class, obj -> 1);
SIZE_CALCULATORS.put(Character.class, obj -> 2);
// 注册常用对象类型估算器
SIZE_CALCULATORS.put(String.class, obj ->
((String) obj).getBytes(StandardCharsets.UTF_8).length);
SIZE_CALCULATORS.put(BigDecimal.class, obj ->
obj.toString().getBytes(StandardCharsets.UTF_8).length);
// 注册日期时间类型估算器
SIZE_CALCULATORS.put(Date.class, obj -> 8);
SIZE_CALCULATORS.put(java.sql.Date.class, obj -> 8);
SIZE_CALCULATORS.put(java.sql.Time.class, obj -> 8);
SIZE_CALCULATORS.put(java.sql.Timestamp.class, obj -> 8);
SIZE_CALCULATORS.put(LocalDate.class, obj -> 6);
SIZE_CALCULATORS.put(LocalTime.class, obj -> 5);
SIZE_CALCULATORS.put(LocalDateTime.class, obj -> 12);
SIZE_CALCULATORS.put(Instant.class, obj -> 12);
SIZE_CALCULATORS.put(ZonedDateTime.class, obj -> 20);
SIZE_CALCULATORS.put(OffsetDateTime.class, obj -> 16);
// 注册字节数组类型
SIZE_CALCULATORS.put(byte[].class, obj -> ((byte[]) obj).length);
}
/**
* 估算结果集大小
*/
public static long measureBytes(Object result) {
if (result == null) {
return0;
}
if (result instanceof List) {
List<?> list = (List<?>) result;
if (list.isEmpty()) {
return0;
}
// 遍历所有行进行估算
long totalSize = 0;
for (Object row : list) {
totalSize += estimateRowSize(row);
}
return totalSize;
}
// 单个对象结果
return estimateRowSize(result);
}
/**
* 估算单行大小
*/
private static long estimateRowSize(Object row) {
if (row == null)
return0;
long rowSize = 0;
if (row instanceof Map) {
// Map类型结果(如selectMap)
Map<?, ?> rowMap = (Map<?, ?>) row;
for (Object value : rowMap.values()) {
rowSize += estimateValueSize(value);
}
} else {
// 实体对象类型
List<Field> cachedFields = getCachedFields(row.getClass());
for (Field field : cachedFields) {
try {
field.setAccessible(true);
Object value = field.get(row);
rowSize += estimateValueSize(value);
} catch (IllegalAccessException e) {
// 忽略无法访问的字段
}
}
}
// 加上对象头开销(约16字节)
return rowSize + 16;
}
/**
* 估算单个值的大小
*/
private static long estimateValueSize(Object value) {
if (value == null) {
return0;
}
Class<?> valueClass = value.getClass();
// 查找精确匹配的估算器
SizeCalculator calculator = SIZE_CALCULATORS.get(valueClass);
if (calculator != null) {
return calculator.calculate(value);
}
// 尝试父类或接口匹配
for (Map.Entry<Class<?>, SizeCalculator> entry : SIZE_CALCULATORS.entrySet()) {
if (entry.getKey().isAssignableFrom(valueClass)) {
return entry.getValue().calculate(value);
}
}
// 默认处理:使用toString的字节长度
return value.toString().getBytes(StandardCharsets.UTF_8).length;
}
// 缓存字段反射结果
privatestaticfinal Map<Class<?>, List<Field>> FIELD_CACHE = new ConcurrentHashMap<>();
/**
* 获取类的字段映射(包括父类)
*/
private static List<Field> getCachedFields(Class<?> clazz) {
return FIELD_CACHE.computeIfAbsent(clazz, k -> {
List<Field> fields = new ArrayList<>();
Class<?> current = clazz;
while (current != Object.class) {
Collections.addAll(fields, current.getDeclaredFields());
current = current.getSuperclass();
}
return fields;
});
}
}
针对各种Java类型提供专门的估算逻辑:
|
数据类型 |
估算大小 (字节) |
说明 |
|---|---|---|
|
基本类型 |
固定大小 |
byte(1), short(2), int(4), long(8)等 |
|
字符串 |
UTF-8字节长度 |
使用 |
|
BigDecimal/BigInteger |
字符串表示长度 |
使用 |
|
日期时间 |
固定大小 |
LocalDate(6), LocalTime(5), LocalDateTime(12)等 |
|
其他对象 |
toString()长度 |
默认处理方式 |
3.6 扩展功能
异步监控机制
仅监控,不使用熔断功能场景:线程池异步处理大小估算、行数统计及等级判定,避免阻塞主线程。
配置化管理
配置中心或自定义注解或Spring配置支持
-
告警阈值配置(表级别)
-
熔断阈值配置(表级别)
-
是否打印详细日志
-
采样比例
-
白名单/黑名单判断
深度统计分析
对象的字节数统计信息支持到字段级别,包括:每个字段的总大小、平均大小、最大值、最小值。
通过字段级别的大小分布,可识别以下问题:哪些字段占用空间最多、是否存在异常大字段、数据分布是否均匀。
动态阈值调整
根据历史数据自动调整等级阈值或熔断阈值
public void adjustLevelThresholds() {
// 获取最近7天行数P95值
double p95Rows = queryThresholdP95FromPrometheus();
// 调整行数等级阈值
ROW_LEVELS[3] = (int)(p95Rows * 0.8); // 降低20%
ROW_LEVELS[4] = (int)(p95Rows * 1.2); // 提高20%
// 调整字节等级阈值...
}
高风险查询识别
支持识别高风险查询组合
-
应用服务增加多维度告警
// 行数+字节双维度熔断策略
for (LevelConfig config : levelConfigs) {
if (byteLevel >= config.byteLevel && rowLevel >= config.rowLevel) {
blockAndAlert("高危组合: 行数" + rowCount + " 字节" + byteSize + "MB");
}
}
-
Prometheus告警中心自定义告警
# L3+行数等级且L3+字节数等级的查询
sum by (dao_method) (
rate(sql_query_stats{row_level=~"[3-5]", byte_level=~"[3-5]"}[5m])
) > 10
慢查询告警
根据SQL执行耗时做定制化的有更多上下文的慢查询告警
四、价值与收益:内存防护方案的核心价值与效果收益
4.1 核心价值
1. 多维度监控
-
方法粒度:精确到每个Mapper方法
-
行数维度:识别数据量风险(如全表扫描、大范围in查询)
-
字节数维度:发现大对象问题(如超长文本字段、大JSON字段)
2. 安全预警
-
基于等级变化趋势提前预警(如L3级行数占比突增30%)
-
触发熔断阈值时主动阻断高危查询
3. 根因定位
通过Prometheus标签组合快速定位问题SQL
4. 容量规划
基于历史等级分布数据预测内存/CPU资源需求
4.2 效果收益
1. 系统稳定性提升
通过对数据库查询结果集大小的精细化管控(如限制行数、字节数),直接遏制了因大数据集返回导致的内存异常风险。
-
避免JVM堆内存突发飙升引发的Full GC频繁触发、服务响应延迟等连锁问题
-
降低系统因内存溢出(OOM)导致的非计划停机概率,使服务运行状态更平稳
2. 资源利用优化
减少不必要的大数据集加载对CPU、内存等硬件资源的过度消耗:
-
避免个别查询占用过多资源而挤压其他业务请求的资源空间
-
让系统资源更合理地分配到核心业务逻辑处理中,提升整体资源利用率和服务承载能力
3. 问题排查效率提高
拦截器收集的行数、字节数、执行耗时等多维度指标,为开发人员提供了精准的排查依据:
-
可快速定位存在性能隐患的SQL查询 -- 通过“行数等级”“字节数等级”等标签,直观识别高风险查询操作(如全表扫描、大对象查询)
-
为SQL优化、表结构调整等工作提供明确方向,缩短问题诊断周期
4. 业务连续性保障
熔断机制与告警机制协同作用,保障核心业务流程正常运转:
-
熔断机制:在查询结果超过阻断阈值时主动阻断危险查询,防止其对系统造成更大范围影响
-
告警机制:及时将潜在风险(如接近阈值的查询)通知相关人员,使其有充足时间介入处理,将问题解决在萌芽状态,减少了因系统故障对业务造成的损失
5. 开发规范强化
拦截器形成隐性约束,推动团队开发习惯优化:
-
促使开发人员在编写SQL时更注重结果集大小控制,培养“按需查询”的良好习惯
-
间接推动SQL优化、分页查询等规范落地,从源头减少高风险查询的产生
五、总结
MyBatis拦截器可以以极低成本防止服务因失控查询崩溃,在内存防护中充当“安全闸门”,在关键时刻:
-
感知危险操作
-
拦截潜在风险
-
传递关键信息
一个完善的拦截器体系,可显著提升系统稳定性,有效降低因大数据集查询导致的故障概率。MyBatis拦截器的价值不在于它处理了多少请求,而在于它阻止了多少灾难的发生。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









