 C语言编译链接过程详解与调试工具gdb、自动化构建makefile介绍
C语言编译链接过程详解与调试工具gdb、自动化构建makefile介绍




 文章详细阐述了C语言从源文件到可执行文件的编译链接过程,包括预处理、编译、汇编和链接四个步骤,以及静态链接和动态链接的区别。同时介绍了调试工具gdb的基本使用,如设置断点、查看变量等。此外,还讨论了makefile和make在项目构建中的作用,以及缓存区的概念和其在输出控制中的影响。最后,给出了一个简单的进度条实现示例。
文章详细阐述了C语言从源文件到可执行文件的编译链接过程,包括预处理、编译、汇编和链接四个步骤,以及静态链接和动态链接的区别。同时介绍了调试工具gdb的基本使用,如设置断点、查看变量等。此外,还讨论了makefile和make在项目构建中的作用,以及缓存区的概念和其在输出控制中的影响。最后,给出了一个简单的进度条实现示例。
一. 编译链接再认识
主要针对gcc展开
一个文件从源文件编译成可执行文件大致要经历四个步骤
- 预处理(进行宏替换)
- 编译(生成汇编)
- 汇编(生成机器可识别代码)
- 链接(生成可执行文件或库文件)
现有如下源码,下面展示几个阶段此源码会到达的阶段
#include<stdio.h>
2 #define M 9
3 #define DEBUG
4 int main()
5 {
6
7 printf("hello world %d !\n",M);
8 printf("这是一个测试\n");
9 //这是一个注释,是否会被去除
10 #ifdef DEBUG
11 printf("hello debug!\n");
12 #else
13 printf("hello release!\n");
14 #endif
15 return 0;
16 }
1.预处理
命令行:gcc -E test.c -o test.i
预处理的主要功能包括宏定义,文件包含,条件编译,去注释等
预处理的指令是以#开头的代码行
-E:使得gcc在预处理结束之后停止编译
-o:值生成的目标文件
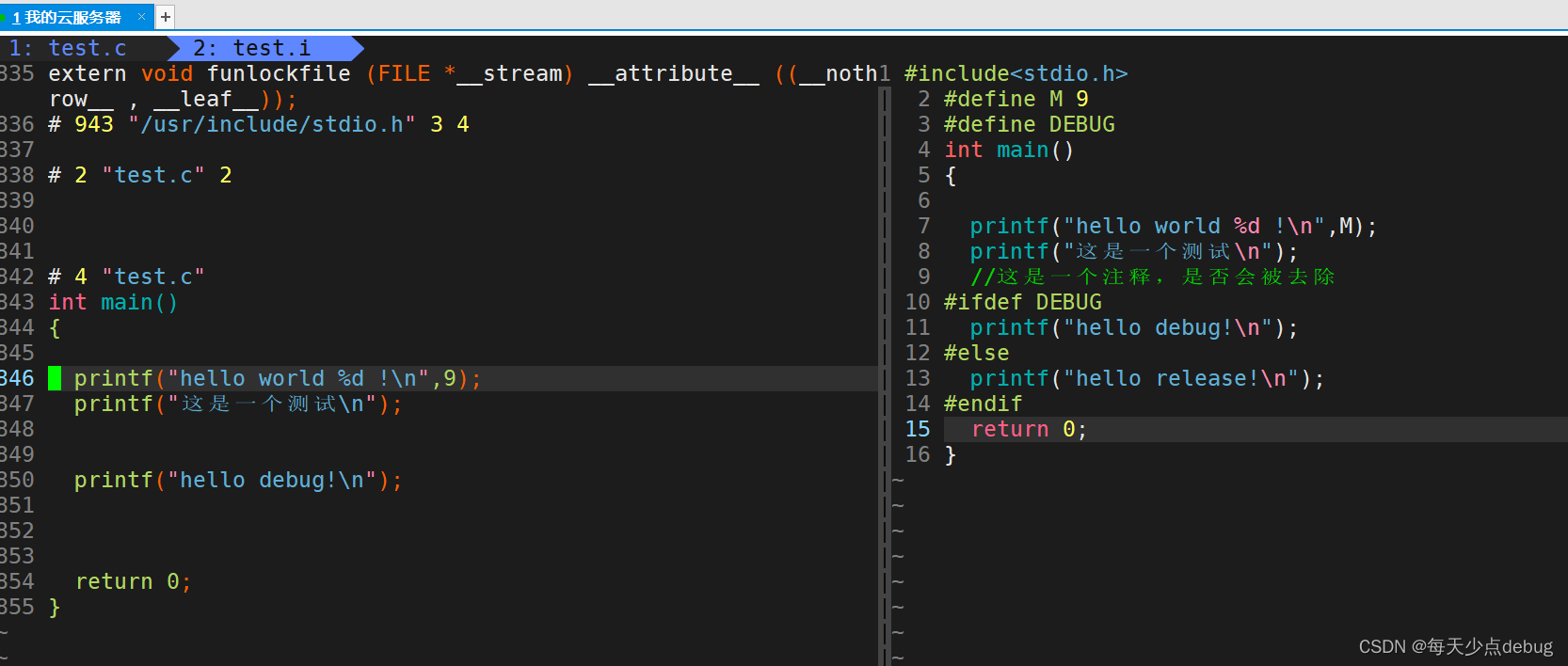
根据上述可以发现,前面800多行都是头文件预处理展开的结果,预处理去掉了宏定义同时,条件编译也没了,注释也没了
注意:编译器内部都必须通过一定的方式,知道你所包含头文件所在路径
Linux所有源文件都会安装在/usr/include/

2.编译
gcc -S test.i -o test.s
从现在开始进行程序的翻译,编译完成之后就停下来
同时在这个阶段gcc首先要检查代码的规范性,是否有语法错误
检查无误后将代码翻译成汇编语言
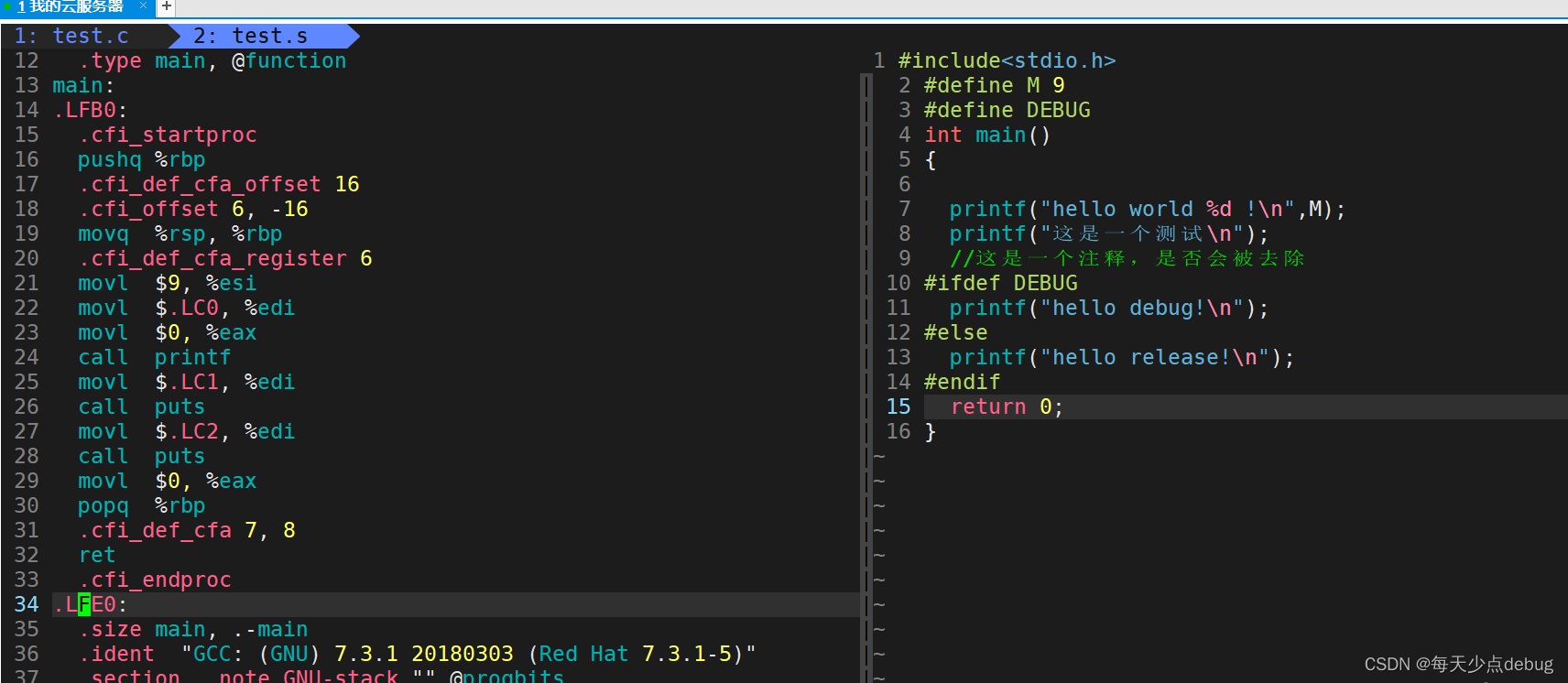
可以发现上述已经生成了汇编语言
3.汇编
gcc -c test.s -o test.o
汇编阶段将编译生成的.s文件转化成目标文件
将汇编语言翻译成机器可识别的可重定位的二进制文件.o
在链接之前,我们要思考一个问题:
我们上述三步编译的是谁的代码?
只编译了自己的代码,我们代码中还有printf库函数,我们没有编译,我们只是调用了一下,
所以:如何和目标的printf的实现产生关联呢?
链接
4.链接
gcc test.o -o test
预编译中的“stdio.h”中只有该函数的申明没有该函数的实习,即使知道函数的视线是在库中,如何找到?
系统把这些函数实现都放在名为lib.so.6的库文件中,在没有特别指定时,gcc会到系统默认的搜索路径/usr/lib下
进行查找,也就是连接到lib.so.6的库函数中去寻找,这样就能找到上述printf函数的定义了。
链接是链接到函数库,函数库一般有两种:动态库和静态库,所有链接也就有两种
静态链接和动态链接
1.静态链接
gcc test.c -o test_static -static
-static:表示此时编译链接是链接静态库的
编译链接时,将库中的相关代码,直接拷贝到可执行程序中。
优点:不依赖任何库,程序可以独立执行
缺点:产生的文件比较大,比较浪费资源
静态库的后缀名一般是".a"
2.动态链接
编译链接时:没有把库文件的代码加入到可执行文件中,而是在程序执行时,由运行时链接文件加载库,节省系统的开销,
动态库的后缀一般是".so"
优点:大家共享一个库
缺点:一旦其中有一个库缺失,会导致几乎所有的程序失效
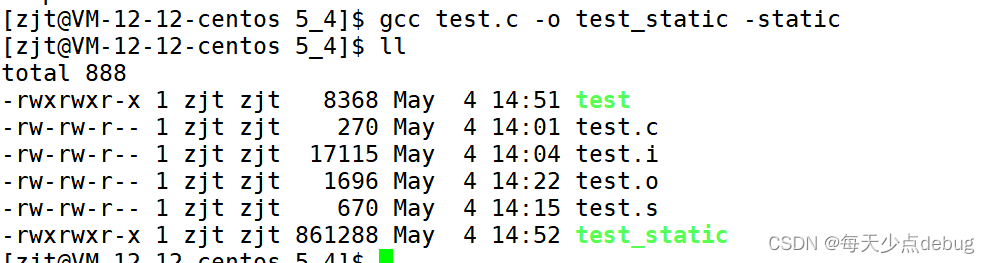
根据上述可以看到,静态链接的文件比动态链接的文件要大很多
**ps:**默认gcc是动态链接的
二.gdb
程序发布有两种方式:
debug+release
Linux gcc/g++出来的二进制程序,默认是release模式
而调试只能是debug模式下的二进制程序
在编译链接时要加 -g选项
gcc test.c -o test_g -g
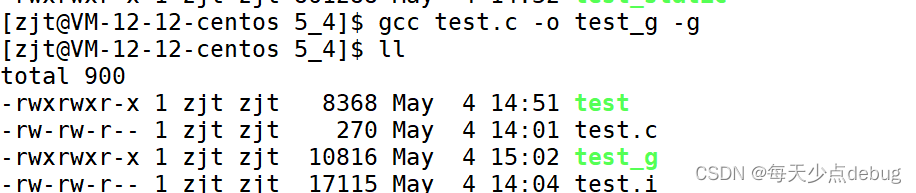
发现debug的二进制文件比release下的二进制文件大,因为添加了调试信息
上述代码不便于调试,另写源码调试
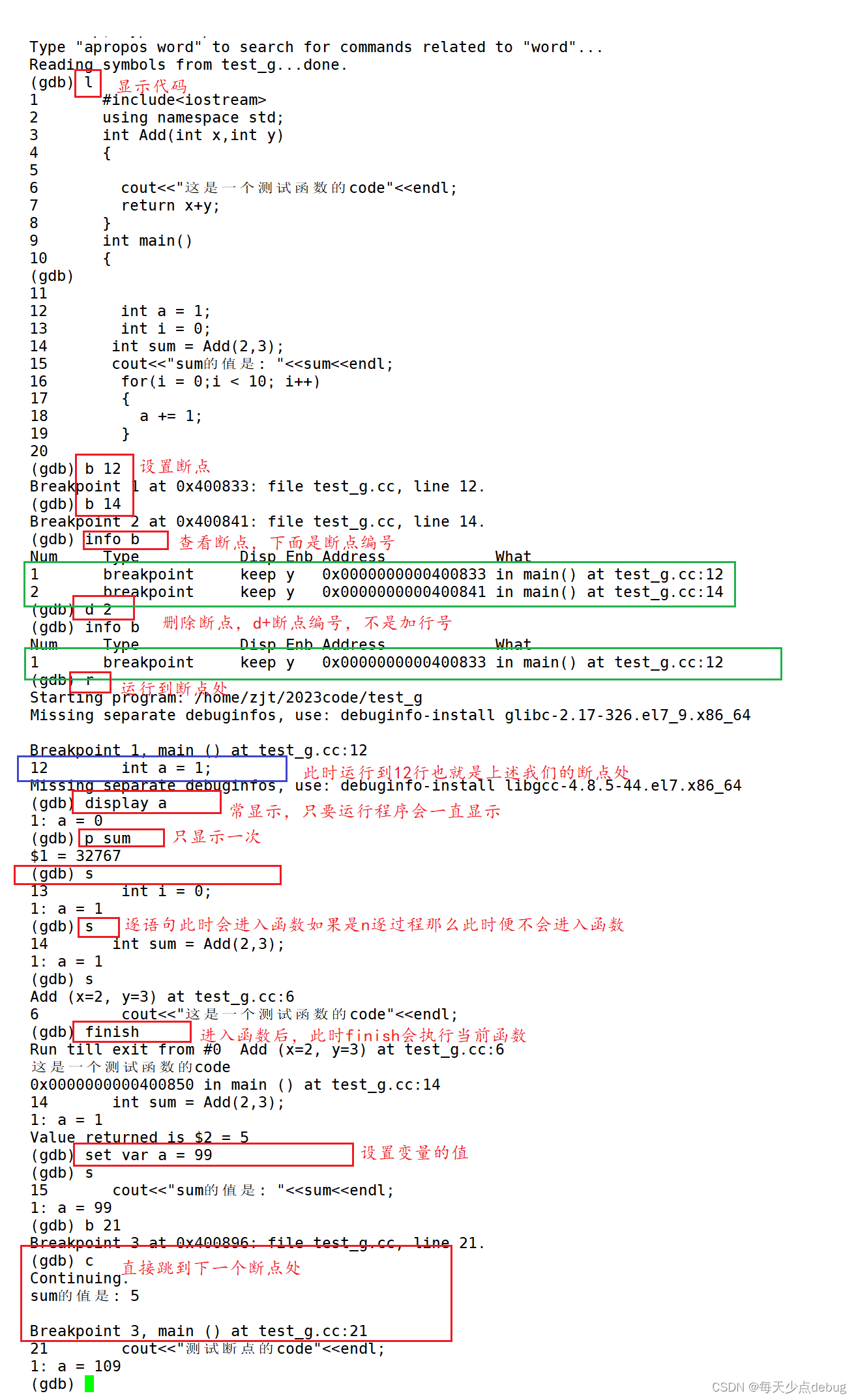
gdb需要掌握以下几点就可以了,不用完全掌握
使用了解:
gdb filename 开始使用
quit:退出
l 行号:显示代码
b 行号:在某一行打断点
d 断点编号:取消断点
s :step,逐语句(进入函数)
n:next,逐过程
display&&undisplay:常显示或取消常显示
until 行号:跳转到指定行
r:运行程序,没有断点直接运行完,有断点运行到第一个断点处
c:从一个断点,之间跳转到另外一个断点
finish:当在一个函数时,执行完一个函数就停下来
info break:查看断点信息
p 变量:打印变量的值
set val:改变变量的值
三.makefile/make
是什么?
make和makefile是软件开发中非常重要的工具,可以自动化构建和管理项目代码,提高开发效率和代码质量.
make是一个命令工具,是一个解析makefile的命令工具,根据文件的依赖关系,自动编译源代码。
makefile是一个文本文件,包含了一系列规则,用于告诉make如何构建。在makefile中还可以定义变量,变量用于
存储一些常量或者配置信息
总结:make会根据makefile中的依赖关系调用对应的依赖方法,生成对应的可执行文件
为什么需要他们?
如果我们一个项目有多个源文件,源文件之间先编译哪个,后编译哪个关系很难捋清楚,
如何构成可执行程序需要我们手动维护,如果其中一个源文件修改了一部分,我们还是需要
全部编译一遍,用make虽然也要手动维护,但是只需要维护一次就可以了。只要我们维护好了
文件与文件之间的关系,生成可执行文件的时候只需要make一下就可以了。
怎么做?如何使用make编译生成可执行文件
下列是一个最简单的makefile,通过这个简单的makefile来展示


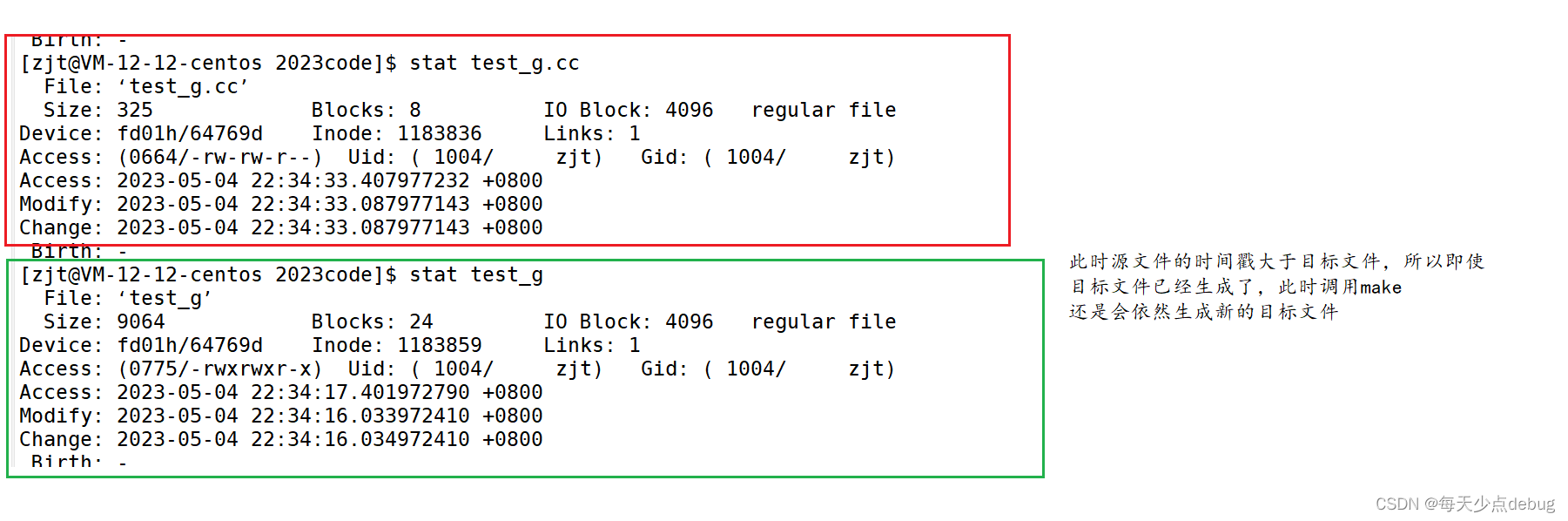
上述提到,如果给目标文件也加.PHONY
那么输入命令make的时候目标文件都会被生成的,但一般不会加.PHONY
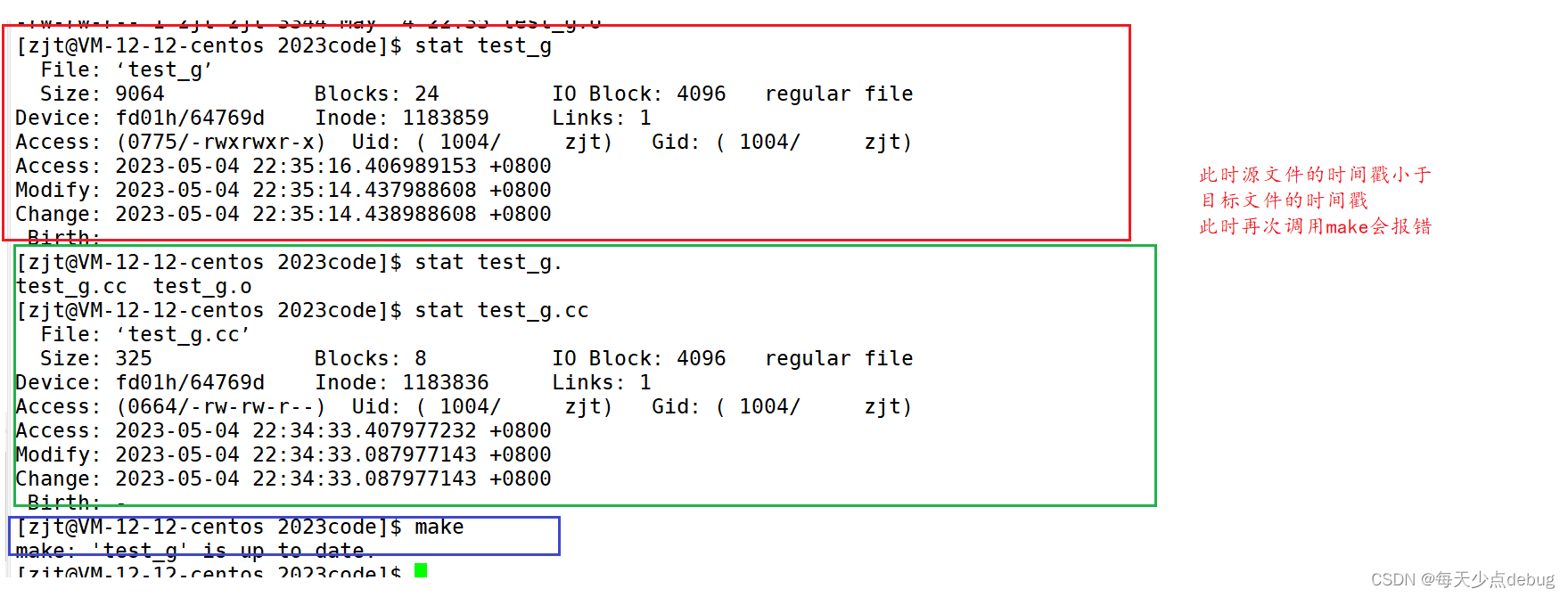
此时只有目标文件不存在或者其中一个依赖文件的时间戳比目标文件的时间戳更新的时候,
make才会执行依赖方法生成目标文件。
ps:如果源文件改了,那么依赖文件的时间戳肯定比目标文件的时间戳更新,此时make
又可以生成新的目标文件了
四.缓存区的理解
#include<stdio.h>
2 #include<unistd.h>
3 int main()
4 {
5 printf("hello world!");
6 sleep(2);
7 printf("\n");
8 return 0;
9 }
上述代码在执行之后,会发现是过了两秒hello world才会被打印出来
为什么会这样呢?
因为缓冲区的存在,缓冲区在计算机中通常指的是一块内存区域,用于存储临时数据,提高数据读写的效率和稳定,不然来一点数据就要发送,效率太低,因此只要在缓冲区满了或者是达到一定条件时,才会将数据输出。而在c语言中这个条件是行刷新或者缓冲区满了,或者程序退出了也可以强制刷新到标准输出上:fflush(stdout)
拓展:
缓存区的大小可以根据需要设置,一般情况下,缓冲区的大小越大,可以存储的数据量越多,读写效率也越高,这也意味着会消耗更多的内存资源,因此在设置缓冲区大小的时候要权衡内存资源和读写之间的关系。
五. 进度条的实现
#include<iostream>
2 #include<unistd.h>
3 #include<cstring>
4 using namespace std;
5 #define NUM 101
6 #define STYLE '#'
7 int main()
8 {
9
10 char bar[NUM];
11 memset(bar,'\0',sizeof(bar));
12 const char *lable = "|/-\\";//假装在转动
13 int cnt = 0;
14 while(cnt <= 100)
15 {
16 printf("加载中: %-100s %d%% %c\r",bar,cnt,lable[cnt%4]);
17 fflush(stdout);
18 bar[cnt++] = STYLE;
19 usleep(20000);//微秒
20 }
21 printf("\n");
22
23
24 return 0;
25 }
运行截图
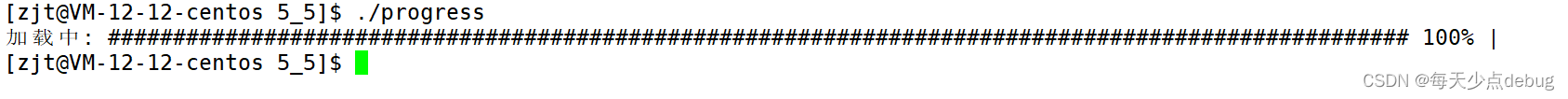


















 832
832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











