 DP算法全面解析
DP算法全面解析







文章目录
前言
这里面包含了我写的所有有关 DP 的文章,总体有点长,如果你对其中一部分感兴趣,可以直接点击标题下的连接跳转至那篇文章。
DP 入门
原文章链接:https://blog.youkuaiyun.com/cwplh/article/details/147159803?spm=1011.2415.3001.5331
基础知识
在这之前,我们先讲一下基础知识。
DP 的本质
DP 的本质是什么?很简单,一句话概括:用旧的状态推出新的状态的过程叫 DP。说的再直白一点,就是递推与递归。因为两者为互逆运算,所以 DP 自然就有了这两种写法。
我至今记得我们小学老师教我的关于 DP 的一句话:过去改变现在,现在改变未来,但过去改变不了未来。听着很深奥,感觉都已经上升到哲学层面了,实际上我一解释就很明了了,所以我决定就不解释了,让你们自己悟,等到哪天突然想起来了这句话后再回来看看。(顺便涨点阅读量)
DP的两种实现方法
上面我们已经说过:DP 的两种实现方式就是递推与递归。
那有的同学就会说:那那个递归的时间复杂度不是远远高于递推吗,怎么他俩还放一起了?那是因为你忘了一个东西:记忆化搜索。没错,这里的 DP 就是拿来记忆化的。
举个例子,就拿斐波那契数列( 1 , 2 , 3 , 5 , 8 , … 1,2,3,5,8,\dots 1,2,3,5,8,…)来讲吧。
递推写法:
cin>>n;//求第n个斐波那契数
dp[1]=1,dp[2]=2;
for(int i=3;i<=n;i++)
{
dp[i]=dp[i-1]+dp[i-2];
}
cout<<dp[n];
记忆化搜索写法:
void dfs(int x)
{
if(x==1)
{
return 1;
}
if(x==2)
{
return 2;
}
if(dp[x]!=-1)
{
return dp[x];
}
return dp[x]=dfs(x-1)+dfs(x-2);
}
这下就很明了了,如果觉得还是很模模糊糊的同学可以再理解理解上面的两种写法。
空间优化 DP
空间优化 DP 是 DP 十分十分重要但又很基础的一个东西,因为 DP 的空间优化几乎就只有一种:滚动数组。
滚动数组,顾名思义,就是让 DP 数组“滚起来”,比如这样一个 DP:dp[i][j]=max(dp[i][j],dp[i][j-1]),这时 DP 数组的第二维就只与这一项和前一项两项有关,所以我可以把 dp[N][M] 改成 dp[N][2],这样就大大减小了空间,有时我们甚至能把这个数组压到一维,在背包里会重点讲。
一维 DP
一维 DP 是 DP 中最最最基本的,为方便讲解,让我们拿出一道水题:
输⼊ n ( n ≤ 100000 ) n(n\le100000) n(n≤100000) 和 n n n 个整数,输出该序列中最⼤的连续⼦序列的和。
(这道题是我从我们训练的题中拿出来的一道水题。)
好家伙,题目越短,事情越大。
我们单独对这 n n n 个整数中的一个看,我们先不思考怎么求最大连续子序列和,我们先思考在以 i i i 为结尾的情况下求连续和有那些情况。
首先我们可以与上一个连续子序列和连在一起,但只能是上一个点的,也可以与之前的断开,自己单独做一个子序列,然后在这两个之间做个选择就行了,由此我们得到了状态转移方程( d p i dp_i dpi 表示以 i i i 为结尾的最大连续子序列和, a i a_i ai 是输入的数组):
d p i = max ( d p i − 1 + a i , a i ) dp_i=\operatorname{max}(dp_{i-1}+a_i,a_i) dpi=max(dpi−1+ai,ai)
然后在所有的子序列中找出最大的就行了。
附上代码:
#include<bits/stdc++.h>
#define int long long
using namespace std;
int n,ans,a[100006],dp[100006];
signed main()
{
cin>>n;
for(int i=1;i<=n;i++)
{
cin>>a[i];
}
for(int i=1;i<=n;i++)
{
dp[i]=max(a[i],dp[i-1]+a[i]);
}
for(int i=1;i<=n;i++)
{
ans=max(ans,dp[i]);
}
cout<<ans;
return 0;
}
怎么样,是不是很简单?别急,这只是开胃菜。洛谷上的题一抓一大把呢。
最长上升子序列(LIS)
最长上升子序列(LIS)是 DP 的经典题目,在正式讲之前,我先说几个概念:
- 子序列:指在一个长度为 n n n 的序列选出 m m m 个数所组成的序列叫做子序列,子序列可以不是连续的,但先后顺序要与原序列中的顺序相符。
- 上升子序列:指保证 i < j i\lt j i<j 且 a i < a j a_i\lt a_j ai<aj( a i a_i ai 指这个子序列的第 i i i 位是什么, a j a_j aj 一样)的子序列。
- 最长上升子序列:指长度最长的上升子序列。
概念可能有点抽象,我们来举个例子:假设有一个序列 A = { 5 , 1 , 3 , 2 , 4 } A=\{5,1,3,2,4\} A={5,1,3,2,4},那么序列 { 5 , 4 } \{5,4\} {5,4} 就是它的子序列,但不是上升子序列, { 3 , 4 } \{3,4\} {3,4} 就是上升子序列,但不是最长上升子序列,而序列 { 1 , 2 , 4 } \{1,2,4\} {1,2,4} 或 { 1 , 3 , 4 } \{1,3,4\} {1,3,4} 就是最长上升子序列。但是 { 2 , 3 } \{2,3\} {2,3} 就不是子序列,应为它俩在原序列中的顺序反了。
解释清楚概念之后,下面的就好讲多了。然后我们就要思考“对于以当前这个点为结尾的最长上升子序列怎么求”这个问题。
很简单,我们设一个 dp[i] 表示以
i
i
i 号位置为结尾的 LIS(为了方便,我后面都写简写),那我们要接上这个点,只有在前面的小于这个点的数的点中找最大的,然后和这个点拼上就行了,状态转移方程如下:
d p i = max j = 1 i − 1 { d p i , d p j + 1 } dp_i=\max_{j=1}^{i-1}\{dp_i,dp_j+1\} dpi=j=1maxi−1{dpi,dpj+1}
代码就不需要我写了吧。
总而言之,LIS 的经典方法就是两层循环套一个 DP,时间复杂度 O ( n 2 ) O(n^2) O(n2)
LIS 优化之二分优化(非 DP 做法)
如果题目中的 n n n 很大,这是又该怎么办呢?很简单,用点贪心的思想就对了。
假设有这样一个序列:
{
5
,
3
,
1
,
2
,
2
,
4
,
3
,
1
}
\{5,3,1,2,2,4,3,1\}
{5,3,1,2,2,4,3,1}。现在要你找它的 LIS,因为我们要尽可能的满足这个条件:
i
<
j
i\lt j
i<j 且
a
i
<
a
j
a_i\lt a_j
ai<aj。那么我们用贪心的思想就可以很容易想到:只要这个子序列的前面越小,整个序列就越有可能是 LIS,所以说我们只需要用一个 queue 或者是数组(建议用数组,因为后面还要二分)保存当前的 LIS,那么一个点如果大于当前的队尾,就可以直接和前面的子序列连上,如果不是,那么就找到最后一个小于它的,因为这样前面的序列就可以更小,更符合后面的发展,而因为整个数组是有序的,所以这个过程我们可以用二分来解决。
核心代码(主要是怕你们抄代码):
int find(int x)//二分查找
{
int l=1,r=cnt,mid;
while(l<=r)
{
mid=l+r>>1;//包不会错的啊
if(q[mid]>=x)
{
r=mid-1;
}
else
{
l=mid+1;
}
}
return l;
}
int main()
{
//一堆输入...
q[++cnt]=a[1];//q 是我先开始说的那个辅助数组,a 是我输入进来的序列
for(int i=2;i<=n;i++)
{
if(a[i]>q[cnt])//直接接入
{
q[++cnt]=a[i];
}
else//换成更有利条件
{
q[find(a[i])]=a[i];
}
}
//又是一大堆输出...
}
感兴趣的同学可以自己下来写一写另一种求 LIS 的方法(反正代码在那)。
二维 DP
讲了一大堆,终于是来到了二维 DP了。
二维 DP 其实比一维 DP 高级不到哪去,也就是多开了一维而已,但它真正的魅力在于:这个新开的这意味不只是图像上的,还可能是数位(数位 DP)、一个二进制编码(状压 DP)、一个开头和一个结尾(区间 DP)、价值(背包 DP)、当前所在节点(树形 DP)等等。可见,二维 DP 就是我们后面要讲的 DP 的基础。
没什么可讲的,直接看一道例题:
棋盘上 A A A 点有⼀个过河卒,需要⾛到⽬标 B B B 点。卒⾏⾛的规则:可以向下、或者向右。同时在棋盘上 C C C 点有⼀个对⽅的⻢,该⻢所在的点和所有跳跃⼀步可达的点称为对⽅⻢的控制点。因此称之为“⻢拦过河卒”。棋盘⽤坐标表示, A A A 点 ( 0 , 0 ) (0, 0) (0,0)、 B B B 点 ( n , m ) (n, m) (n,m),( n , m n,m n,m 为不超过 20 20 20 的整数),同样⻢的位置坐标是需要给出的。现在要求你计算出卒从 A A A 点能够到达 B B B 点的路径的条数,假设⻢的位置是固定不动的,并不是卒⾛⼀步⻢⾛⼀步。
这道题洛谷上有,我们训练的题单里也有,所以我就拿来当例题了。
这是二维 DP 最经典的题目:平面几何上做 DP。因为每个点可以向右走或向下走,所以每个点能走道的路径的方案总数就是它上面的点的方案总数加上左边那个点的方案总数(应为上面的可以走下来,左边的可以往右走走到),所以状态转移方程就推出来了:
d p i , j = d p i , j − 1 + d p i − 1 , j dp_{i,j}=dp_{i,j-1}+dp_{i-1,j} dpi,j=dpi,j−1+dpi−1,j
但这个里面有马拦着啊。这也很好解决,只要马能到的地方不走就行了。
最后记得初始化:马没拦下之前的点都可以初始化为 1 1 1。
AC 代码:
#include<bits/stdc++.h>
using namespace std;
int n,m,b[26][26],i,j,x,y;
long long a[26][26];
int main()
{
cin>>n>>m>>x>>y;
b[x][y]=1;
b[x+2][y+1]=1;
b[x+2][y-1]=1;
b[x+1][y+2]=1;
b[x+1][y-2]=1;
b[x-2][y+1]=1;
b[x-2][y-1]=1;
b[x-1][y+2]=1;
b[x-1][y-2]=1;
for(i=0;i<=n;i++)//马拦下之前的点都是 1
{
if(b[i][0]==1)
{
break;
}
a[i][0]=1;
}
for(j=0;j<=m;j++)
{
if(b[0][j]==1)
{
break;
}
a[0][j]=1;
}
for(i=1;i<=n;i++)
{
for(j=1;j<=m;j++)
{
if(b[i][j]==0)
{
a[i][j]=a[i-1][j]+a[i][j-1];
}
}
}
cout<<a[n][m];
return 0;
}
很简单?别慌,这才橙题,接下来我要开始找一些有难度的题了:
⼀个吉他⼿准备参加⼀场演出。他不喜欢在演出时始终使⽤同⼀个⾳量,所以他决定每⼀⾸歌之前他都需要改变⼀次⾳量。在演出开始之前,他已经做好⼀个列表,⾥⾯写着每⾸歌开始之前他想要改变的⾳量是多少。每⼀次改变⾳量,他可以选择调⾼也可以调低。⾳量⽤⼀个整数描述。输⼊⽂件中整数 beginLevel,代表吉他刚开始的⾳量,整数 maxLevel,代表吉他的最⼤⾳量。⾳量不能⼩于 0 0 0 也不能⼤于 maxLevel。输⼊中还给定了n个整数 c 1 , c 2 , c 3 , . . . , c n c_1,c_2,c_3,...,c_n c1,c2,c3,...,cn,表示在第i⾸歌开始之前吉他⼿想要改变的⾳量是多少。吉他⼿想以最⼤的⾳量演奏最后⼀⾸歌,你的任务是找到这个最⼤⾳量是多少。
这也是我们训练的一道题。
一开始看到这道题时,我也没思路,因为要求最大音量,这 DP 不管怎么设都不好求状态转移方程啊。
但当我再次看向题目,我看到了这句话:⾳量不能⼩于 0 0 0 也不能⼤于 maxLevel。这说明什么?说明音量的最大值就是 maxLevel,而不可能更高了。我只需要从大到小枚举一下那些成立,然后去最大的就行了。这样,我们的 DP 就从求值变成了标记。
那怎么标呢?题目中说了:第 i i i 首歌可以调 c i c_i ci 格音量。所以设 d p i , j dp_{i,j} dpi,j 表示在第 i i i 首歌用 j j j 的音量能否成立,那么从 d p i , j − c i dp_{i,j-c_i} dpi,j−ci 和 d p i , j + c i dp_{i,j+c_i} dpi,j+ci 都可以得到当前音量,由此我们得到了状态转移方程为:
d p i , j = d p i − 1 , j − c i ∣ d p i − 1 , j + c i dp_{i,j}=dp_{i-1,j-c_i}|dp_{i-1,j+c_i} dpi,j=dpi−1,j−ci∣dpi−1,j+ci
但要注意的是: j − c i ≥ 0 , j + c i ≤ m a x L e v e l j-c_i\ge0,j+c_i\le maxLevel j−ci≥0,j+ci≤maxLevel
AC 代码:
#include<bits/stdc++.h>
#define int long long
using namespace std;
int n,bl,ml,a[56],dp[56][1006];
signed main()
{
cin>>n>>bl>>ml;
for(int i=1;i<=n;i++)
{
cin>>a[i];
}
dp[0][bl]=1;
for(int i=1;i<=n;i++)
{
for(int j=0;j<=ml;j++)
{
if(j-a[i]>=0)//我也不知道没声音怎么听演唱会...
{
dp[i][j]=(dp[i][j]|dp[i-1][j-a[i]]);
}
if(j+a[i]<=ml)
{
dp[i][j]=(dp[i][j]|dp[i-1][j+a[i]]);
}
}
}
for(int i=ml;i>=0;i--)
{
if(dp[n][i])
{
cout<<i;
return 0;
}
}
cout<<-1;
return 0;
}
这里再提供一种思路:如果对于上一场中当前音量是可以达到的,那么这一场中的 j + c i j+c_i j+ci 和 j − c i j-c_i j−ci 也是可以达到的,注意事项与上面一样。
最长公共子序列(LCS)
最长公共子序列(LCS)是二维 DP 的经典题目,指的是两个序列的最长的相同的子序列,这是我们一般会定义一个 dp[i][j] 用来表示以第一个序列的第
i
i
i 位为结尾、第二个序列的第
j
j
j 位为结尾的 LCS,具体的状态转移方程如下:
d p i , j = max { d p i − 1 , j , d p i , j − 1 , d p i − 1 , j − 1 ( if a i = b i ) } dp_{i,j}=\max\{dp_{i-1,j},dp_{i,j-1},dp_{i-1,j-1}(\text{if}\ a_i=b_i)\} dpi,j=max{dpi−1,j,dpi,j−1,dpi−1,j−1(if ai=bi)}
我来解释一下:首先不管你这两个序列的这一位相不相等,当前的 LCS 必然是 a a a 序列不要这一位后的 LCS 或 b b b 序列不要这一位后的 LCS,也就是 max \max max 的前半部分,而如果这两个相等,那我们可以在 a a a 序列和 b b b 序列都去掉这一位的情况下多家当前这一位,也就是最后的那个式子。
区间 DP 详解
原文章链接:https://blog.youkuaiyun.com/cwplh/article/details/147073064?spm=1011.2415.3001.5331
区间 DP
区间 DP,就是在对一段区间进行了若干次操作后的最小代价,一般是合并和拆分类型。
分割型
分割型,指把一个区间内的几项分开拆成一份一份的,再全部合起来就是当前答案,可以理解为合并型的另一种(合并型详见下面),它的时间复杂度一般为
O
(
n
3
)
O(n^3)
O(n3),其中我们一般设 dp[i][j] 表示把前
i
i
i 项拆成
j
j
j 份的最小值,而第三层循环则是循环的分割点,表示把前
i
i
i 项从
k
k
k 这里分开来看,这就是“分割”。由此,我们可以得到这样一个状态转移方程:
d p i , j = min { d p i , j , d p k , j − 1 + 代价 } dp_{i,j}=\min\{dp_{i,j},dp_{k,j-1}+\text{代价}\} dpi,j=min{dpi,j,dpk,j−1+代价}
当然,有时我们也会把这个 k k k 当做从 i − 1 i-1 i−1 到 i i i 一共分成了 k k k 份,由此,我们可以得到另一种状态转移方程:
d p i , j = d p i − 1 , j − k + d p i , j dp_{i,j}=dp_{i-1,j-k}+dp_{i,j} dpi,j=dpi−1,j−k+dpi,j
这种情况下一般就不是讨论最小值,而是计数,我们可以看下面这道例题:
⼩明的花店新开张,为了吸引顾客,他想在花店的⻔⼝摆上⼀排花,共 m m m 盆。通过调查顾客的喜好,⼩明列出了顾客最喜欢的 n n n 种花,从 1 1 1 到 n n n 标号。为了在⻔⼝展出更多种花,规定第 i i i 种花不能超过 a i a_i ai 盆,摆花时同⼀种花放在⼀起,且不同种类的花需按标号的从⼩到⼤的顺序依次摆列。试编程计算,⼀共有多少种不同的摆花⽅案。
这就是我们刚刚说的第二种类型,直接套公式即可。注意初始化(初始化就不用我都说了吧,就是 d p i , 0 = 1 dp_{i,0}=1 dpi,0=1 呗),但这种类型很少见,我基本翻遍了全网才找到了这一道题,其余的基本都是第一种,所以各位同学终点记第一种就行,第二种做一个拓展。
AC 代码:
#include<bits/stdc++.h>
#define int long long
using namespace std;
const int mod=1e6+7;
int n,m,a[106],dp[106][106];
signed main()
{
cin>>n>>m;
dp[0][0]=1;//初始化
for(int i=1;i<=n;i++)
{
cin>>a[i];
dp[i][0]=1;
}
for(int i=1;i<=n;i++)//终点
{
for(int j=1;j<=m;j++)//分割份数
{
for(int k=0;k<=min(a[i],j);k++)//i-1 到 i 的分割份数
{
dp[i][j]=(dp[i][j]+dp[i-1][j-k])%mod;
}
}
}
cout<<dp[n][m];
return 0;
}
下面留一道例题供大家练习:
今年是国际数学联盟确定的“2000――世界数学年”,⼜恰逢我国著名数学家华罗庚先⽣诞⾠ 90 周年。在华罗庚先⽣的家乡江苏⾦坛,组织了⼀场别开⽣⾯的数学智⼒竞赛的活动,你的⼀个好朋友 XZ 也有幸得以参加。活动中,主持⼈给所有参加活动的选⼿出了这样⼀道题⽬:
设有⼀个⻓度为 N N N 的数字串,要求选⼿使⽤ K K K 个乘号将它分成 K + 1 K+1 K+1 个部分,找出⼀种分法,使得这 K + 1 K+1 K+1 个部分的乘积能够为最⼤。
同时,为了帮助选⼿能够正确理解题意,主持⼈还举了如下的⼀个例⼦:
有⼀个数字串: 312 312 312, 当 N = 3 , K = 1 N=3,K=1 N=3,K=1 时会有以下两种分法:
- 3×12=36
- 31×2=62
这时,符合题⽬要求的结果是: 31 × 2 = 62 31\times2=62 31×2=62。
现在,请你帮助你的好朋友 XZ 设计⼀个程序,求得正确的答案。
合并型
合并型,一般指把这一个区间内的相邻两项合在一起,每次代价为这两项的和,求最小代价。 这种题,我们只需要一个万能公式就可以搞定,它就是:
d p j , e d = min { d p j , e d , d p j , k + d p k + 1 , e d + 代价 } dp_{j,ed}=\min\{dp_{j,ed},dp_{j,k}+dp_{k+1,ed}+\text{代价}\} dpj,ed=min{dpj,ed,dpj,k+dpk+1,ed+代价}
咳咳,不小心把祖传秘方给说出来了。
其中 j j j 是起点, e d ed ed 是终点, k k k 是分割点,表示从起点到终点中间一个把区间一分为二的点。这时再回去看看那个方程,是不是就明了多了?
这里我要说一下:这里我们一般写三层循环,最外面枚举区间长度,第二层枚举起点,第三层枚举分割点。所以时间复杂度也是 O ( n 3 ) O(n^3) O(n3)。
还有就是 DP 的初始化我们一般都是这样:
for(int i=1;i<=n;i++)
{
dp[i][i]=0;
}
表示你以当前这个点为起点同时为终点合并的代价为 0 0 0。当然,在不同的题中有不同的初始化,一般都是两个区间之间的代价等于多少这种。
为了让大家更好理解,我们拿一道例题来讲一讲(没有洛谷的可以看下面):
设有 N ( 0 ≤ N ≤ 300 ) N(0\le N\le300) N(0≤N≤300) 堆石子排成一排,其编号为 1 , 2 , 3 , … , N 1,2,3,\dots,N 1,2,3,…,N。每堆石子有一定的质量 m i ( m i ≤ 1000 ) m_i(m_i\le1000) mi(mi≤1000)。现在要将这 N N N 堆石子合并成为一堆。每次只能合并相邻的两堆,合并的代价为这两堆石子的质量之和,合并后与这两堆石子相邻的石子将和新堆相邻。合并时由于选择的顺序不同,合并的总代价也不相同。试找出一种合理的方法,使总的代价最小,并输出最小代价。
一道极其经典的合并型区间 DP,让我们套上上面的模版并把代价加入得(其中 s i s_i si 是 m i m_i mi 的前缀和):
d p j , e d = min { d p j , e d , d p j , k + d p k + 1 , e d + s e d − s j } dp_{j,ed}=\min\{dp_{j,ed},dp_{j,k}+dp_{k+1,ed}+s_{ed}-s_j\} dpj,ed=min{dpj,ed,dpj,k+dpk+1,ed+sed−sj}
(代码自己写)。
环形合并
有时候,我们这个合并型可能会在一个环上合并,这时我们不好考虑首位合并的情况,所以就有一种办法:断环成链!我们只需要把这个环变成一条链,然后在后面再接上一次,就可以正常的跑合并型了,具体请看这张图:
[
a
1
,
a
2
,
a
3
,
…
,
a
n
]
,
a
n
+
1
,
a
n
+
2
,
…
,
a
2
n
[a_1,a_2,a_3,\dots,a_n],a_{n+1},a_{n+2},\dots,a_{2n}
[a1,a2,a3,…,an],an+1,an+2,…,a2n
a
1
,
[
a
2
,
a
3
,
…
,
a
n
,
a
n
+
1
]
,
a
n
+
2
,
…
,
a
2
n
a_1,[a_2,a_3,\dots,a_n,a_{n+1}],a_{n+2},\dots,a_{2n}
a1,[a2,a3,…,an,an+1],an+2,…,a2n
a
1
,
a
2
,
[
a
3
,
…
,
a
n
,
a
n
+
1
,
a
n
+
2
]
,
…
,
a
2
n
a_1,a_2,[a_3,\dots,a_n,a_{n+1},a_{n+2}],\dots,a_{2n}
a1,a2,[a3,…,an,an+1,an+2],…,a2n
⋯
\cdots
⋯
a
1
,
a
2
,
a
3
,
…
,
a
n
,
[
a
n
+
1
,
a
n
+
2
,
…
,
a
2
n
]
a_1,a_2,a_3,\dots,a_n,[a_{n+1},a_{n+2},\dots,a_{2n}]
a1,a2,a3,…,an,[an+1,an+2,…,a2n]
(有点抽象,但是因为设备太简陋了,也只能这样做。)
我们还是来看一道例题:
因为题目是一个 pdf 文件,不好取字,所以就把链接放在上面了,偷懒的同学也可以看下面的图片。

这就是一个很经典的环形区间 DP,所以我们可以先断环成链,然后在后面拼上一截,最后直接做区间合并型 DP 就行了。
但要注意的是这里的初始化不是 0 0 0,而是从 i − 1 i-1 i−1 到 i + 1 i+1 i+1 的值为 ∏ k = i − 1 i + 1 a k \prod_{k=i-1}^{i+1}a_k ∏k=i−1i+1ak( ∏ \prod ∏ 是多个数的乘积的意思)
AC 代码:
#include<bits/stdc++.h>
#define int long long
using namespace std;
int n,mx,a[206],dp[206][206];//dp:从i到j的最大方案
signed main()
{
cin>>n;
for(int i=1;i<=n;i++)
{
cin>>a[i];
a[i+n]=a[i];//断环成链并拼上一节,方便后续处理
}
n*=2;
for(int i=2;i<n;i++)//初始化
{
dp[i-1][i+1]=a[i-1]*a[i]*a[i+1];
}
for(int i=4;i<=n;i++)//长度
{
for(int j=1;j<=n-i+1;j++)//起点
{
int ed=i+j-1;
for(int k=j+1;k<ed;k++)//分割点
{
dp[j][ed]=max(dp[j][ed],dp[j][k]+dp[k][ed]+a[j]*a[k]*a[ed]);//这里注意:是 dp[j][k]+dp[k][ed] 而不是 dp[j][k]+dp[k+1][ed],具体原因大家自己想
}
}
}
n/=2;
for(int i=1;i<=n;i++)
{
mx=max(mx,dp[i][i+n]);
}
cout<<mx;
return 0;
}
背包 DP 详解
原文章链接:https://blog.youkuaiyun.com/cwplh/article/details/147160489?spm=1011.2415.3001.5331
背包DP
背包 DP,说白了就是往一个背包里扔东西,求最后的最大价值是多少,一般分为了三种:01 背包、完全背包和多重背包。而 01 背包则是一切的基础。
01 背包
特点:每个物品只有一个,只能选择装这个物品或者不装。
这时我们一般设一个 dp[i][j] 表示前
i
i
i 个物品再总体积为
j
j
j 的情况下装的最大价值是多少。所以 01 背包的时间复杂度为
O
(
n
2
)
O(n^2)
O(n2),这时我们可以得到这样一个状态转移方程:
d p i , j = max { d p i − 1 , j , d p i − 1 , j − v i + w i } dp_{i,j}=\max\{dp_{i-1,j},dp_{i-1,j-v_i}+w_i\} dpi,j=max{dpi−1,j,dpi−1,j−vi+wi}
这里的 v i v_i vi 指当前物品所占的体积, w i w_i wi 指当前物品的价值。
那这是怎么一回事呢?我们可以这样想:我要么不选这件物品,那么总价值就和 d p i − 1 , j dp_{i-1,j} dpi−1,j 一样(即同样的体积在前 i − 1 i-1 i−1 件物品中的最大价值),如果选了,那就和前 i − 1 i-1 i−1 件物品在体积为 j − v i j-v_i j−vi 的情况下的最大价值再加上当前物品的价值 w i w_i wi 一样,那再取其中的最大值就行了。
但是,我们会发现一个问题:如果你的总体积为 V V V,总物品数为 n n n,那你的空间复杂度就是 O ( V n ) O(Vn) O(Vn),这可是一个极其庞大的数字,这是我们就要请上我们的滚动背包!
滚动背包旨在通过观察状态转移方程看看哪些空间没用从而可以省掉。比如说上面的状态转移方程,我们会发现 DP 的第一维只与当前状态与上一状态有关,而与其他的无关,所以其它空间就是被浪费了的,所以我们只需要把第一维开个 2 2 2,而不用开 n n n,这样,空间复杂度就被压到了 O ( 2 V ) O(2V) O(2V),状态转移方程也就变成了这样:
d p i m o d 2 , j = max { d p ( i − 1 ) m o d 2 , j , d p ( i − 1 ) m o d 2 , j − v i + w i } dp_{i\bmod2,j}=\max\{dp_{(i-1)\bmod2,j},dp_{(i-1)\bmod2,j-v_i}+w_i\} dpimod2,j=max{dp(i−1)mod2,j,dp(i−1)mod2,j−vi+wi}
上面这种方法适用于初学者,因为它清楚直观、浅显易懂。
让我们先来看一道例题:
有 N N N 件物品和一个容量是 V V V 的背包。每件物品只能使用一次。
第 i i i 件物品的体积是 v i v_i vi,价值是 w i w_i wi。
求解将哪些物品装入背包,可使这些物品的总体积不超过背包容量,且总价值最大。
输出最大价值。
很经典的一道 01 背包问题,直接用上面的公式就对了。
代码:
#include<bits/stdc++.h>
#define int long long
using namespace std;
int n,vv,v[1006],w[1006],dp[2][1006];
signed main()
{
cin>>n>>vv;
for(int i=1;i<=n;i++)
{
cin>>v[i]>>w[i];
}
for(int i=1;i<=n;i++)
{
for(int j=0;j<=vv;j++)
{
dp[i%2][j]=dp[(i-1)%2][j];
if(j>=v[i])
{
dp[i%2][j]=max(dp[(i-1)%2][j],dp[(i-1)%2][j-v[i]]+w[i]);
}
}
}
cout<<dp[n%2][vv];
return 0;
}
当然,我们也可以在这个的基础上优化成一维滚动背包,但是中间的循环需要颠倒过来一下,具体我们可以这么想:我们上面的状态转移方程再更新时原本的和现在的状态是不会受影响的,而如果我们正着循环,可能就会出现这种情况:

按照我们之前的状态转移方程,我们应该拿原本的旧的状态来更新新的状态,但现在我们却拿我们计算好了的新的状态来更新更新的状态,这是完全不符合的,而倒过来循环正好就能避免这种事情的发生。(想通了的同学继续看,没想通的同学抠破脑袋想。)
所以上面的代码还可以写成这样:
#include<bits/stdc++.h>
#define int long long
using namespace std;
int n,vv,v[1006],w[1006],dp[1006];
int main()
{
cin>>n>>vv;
for(int i=1;i<=n;i++)
{
cin>>v[i]>>w[i];
}
for(int i=1;i<=n;i++)
{
for(int j=vv;j>=v[i];j--)
{
dp[j]=max(dp[j],dp[j-v[i]]+w[i]);
}
}
cout<<dp[vv];
return 0;
}
完全背包
特点:每个物体有无穷多个,可以无限取同一个物品。
这时的改动很小,只需要把上面 01 背包优化成一维时的循环改成正着循环就行了。这又是为啥呢?
我们前面不是说了吗:正着循环会把更新好的状态拿去更新当前状态。如果是 01 背包每种只能用一次,那肯定不行。但是完全背包可以多次放一个物品啊,当前的最新状态对于另一个状态来讲可能只是一个旧状态罢了。
所以,我们把上面的代码稍作改动:
#include<bits/stdc++.h>
#define int long long
using namespace std;
int n,vv,v[1006],w[1006],dp[1006];
int main()
{
cin>>n>>vv;
for(int i=1;i<=n;i++)
{
cin>>v[i]>>w[i];
}
for(int i=1;i<=n;i++)
{
for(int j=v[i];j<=vv;j++)
{
dp[j]=max(dp[j],dp[j-v[i]]+w[i]);
}
}
cout<<dp[vv];
return 0;
}
就水灵灵的 A C \color{green}{AC} AC 了!
(讲的稍微有点快,没看懂的同学可以回去再看。)
多重背包
特点:每件物品有一定数量,所装的物品数量不能超过这个值。
还是拿一道例题讲一下:
有 N N N 种物品和一个容量是 V V V 的背包。第 i i i 种物品最多有 s i s_i si 件,每件体积是 v i v_i vi,价值是 w i w_i wi。
求解将哪些物品装入背包,可使物品体积总和不超过背包容量,且价值总和最大。
输出最大价值。
外面两层循环跟 01 背包一模一样,但是因为有数量限制,里面需要多加一层循环:
for(int k=0;k<=s[i]&&v[i]*k<=j;k++)
这层循环就是循环你要拿或者是不拿 k k k 个物品。
然后我们写状态转移方程:
d p i , j = max { d p i − 1 , j , d p i − 1 , j − k × v i + k × w i } dp_{i,j}=\max\{dp_{i-1,j},dp_{i-1,j-k\times v_i}+k\times w_i\} dpi,j=max{dpi−1,j,dpi−1,j−k×vi+k×wi}
再根据与 01 背包一样的套路优化一下即可。
代码如下:
#include<bits/stdc++.h>
#define int long long
using namespace std;
int n,vv,v[106],w[106],s[106],dp[106];
signed main()
{
cin>>n>>vv;
for(int i=1;i<=n;i++)
{
cin>>v[i]>>w[i]>>s[i];
}
for(int i=1;i<=n;i++)
{
for(int j=vv;j>=v[i];j--)
{
for(int k=0;k<=s[i]&&v[i]*k<=j;k++)
{
dp[j]=max(dp[j],dp[j-v[i]*k]+w[i]*k);
}
}
}
cout<<dp[vv];
return 0;
}
二进制优化
但是(一般一切顺利的时候搜会有个“但是”),我们稍加计算发现它的时间复杂度达到了恐怖的 O ( V × ∑ s i ) O(V\times\sum s_i) O(V×∑si),这个时间复杂度是极高的,为了降低时间复杂度,我们采取了一种优化:转为 01 背包问题。
因为我们有至多 s i s_i si 个,那么我们可以选择的个数有哪些呢?这时,聪明的计算机学家们就想到了一种办法:转二进制。
这个转二进制有什么好处呢?好处可大了去了。因为我们知道任何一个数倍拆成二进制后是可以拼凑出再 s i s_i si 以内的所有数的,而对于当前这个数加不加上又是一个 01 背包问题。
也就是这样:假设 s i = 7 s_i=7 si=7,那么 7 7 7 写成二进制就是 111 111 111,拆成二的幂次相加就是 2 2 + 2 1 + 2 0 2^2+2^1+2^0 22+21+20,而对于每一个数选不选进来凑成一个小于 s i s_i si 的数是个 01 背包问题。于是我们就将多重背包转化成了 01 背包。而对于每一个数再乘 v i v_i vi 表示新的体积,乘 w i w_i wi 表示新的质量,然后做 01 背包就行。
这样我们就将时间复杂度降到了 O ( V × ∑ log 2 ( s i ) ) O(V\times\sum\log_2(s_i)) O(V×∑log2(si)),大大优化了啊!
代码:
#include<bits/stdc++.h>
#define int long long
using namespace std;
struct binary{
int v,w;
};
int n,vv,v[1006],w[1006],s[1006],dp[2006];
vector<binary>v1;
signed main()
{
cin>>n>>vv;
for(int i=1;i<=n;i++)
{
cin>>v[i]>>w[i]>>s[i];
}
for(int i=1;i<=n;i++)
{
for(int j=1;j<=s[i];j*=2)
{
s[i]-=j;
v1.push_back({v[i]*j,w[i]*j});
}
if(s[i]>=0)
{
v1.push_back({v[i]*s[i],w[i]*s[i]});
}
}
for(auto i:v1)
{
for(int j=vv;j>=i.v;j--)
{
dp[j]=max(dp[j],dp[j-i.v]+i.w);
}
}
cout<<dp[vv];
return 0;
}
单调队列优化
注:一般情况下只会卡到二进制优化,所以单调队列优化看不懂的同学可以直接跳过。
二进制优化已经很好了,但还不是最好,真正好的直接优化到了 O ( N × V ) O(N\times V) O(N×V),让我们有请单调队列优化!
~~由于本作者实在是太菜了,竟然没看懂单调队列优化,~~感兴趣的同学可以参考这篇文章。
小结
这篇文章带你梳理了三种基本背包:01 背包、完全背包与多重背包,至于更多的背包模型请大家搜索背包九讲,那里有更多的大佬在等着你们。
数位 DP 详解
原文章链接:https://blog.youkuaiyun.com/cwplh/article/details/147530965?spm=1011.2415.3001.5331
定义
数位 DP 是一种用于数字数位统计的 DP,是一种简单的 DP 套路题。(其实一点都不简单……)
详细做法
数位 DP 的原理其实很简单,就是按照从高到低每一位进行分类,比如说 324 324 324 这个数,按照数位 DP 的方法就会分成这样:
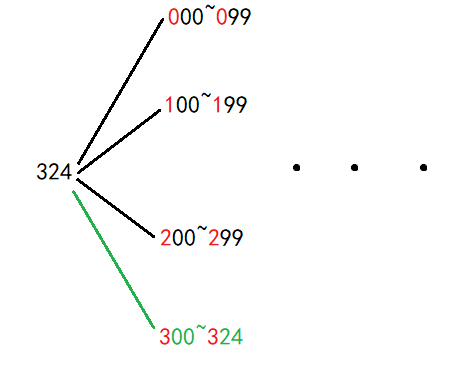
注意看我标红的部分,是不是很直观的体现了数位 DP 的分类方法。
其中,有一段区间我用很显眼的绿色标识了出来,这是为什么呢?
仔细看这一段区间,是不是与其他的都不一样?这就是为什么我要把它标绿,因为其他区间都是整个范围,而只有最后一段区间有一个上限: 324 324 324。因为我们统计的就只有 324 324 324 以内的,如果再算 300 → 399 300\to399 300→399,就不满足题意了,于是我们 DP 的第一个其余参数: l i m i t limit limit(中文意思:限制),出现了!
这个参数是个布尔值,也就是只有两种状态:有限制与无限制。没有限制就可以一直往上走,有了就不行(就像 300 → 324 300\to324 300→324 一样)。
然后我们来看看 DP 数组中的第二个其余参数: l e a d lead lead(中文意思:领导)。我们看第一个区间: 000 → 099 000\to099 000→099,你不觉得奇怪吗? 000 000 000 是什么东西? 099 099 099 又是什么东西?问题就出在了这儿:前导 0 0 0!所以 l e a d lead lead 这个参数也是一个布尔值,就是用来存储有无前导 0 0 0。
我们之前说过:DP 有两种写法,一种递推,一种记忆化搜索。而对于数位 DP 来讲,最常写也最方便的莫过于记忆化搜索写法,递推不是不可以,就是太难理解了。
为了方便讲解,我们拿一道经典例题讲讲:
洛谷 P2602
题目:给定两个正整数 a a a 和 b b b,求在 [ a , b ] [a,b] [a,b] 中的所有整数中,每个数码(digit)各出现了多少次。
输入格式:仅包含一行两个整数 a , b a,b a,b,含义如上所述。
输出格式:包含一行十个整数,分别表示 0 ∼ 9 0\sim 9 0∼9 在 [ a , b ] [a,b] [a,b] 中出现了多少次。
数据规模与约定:
对于 100 % 100\% 100% 的数据,保证 1 ≤ a ≤ b ≤ 10 12 1\le a\le b\le 10^{12} 1≤a≤b≤1012。
对于基础的数位 DP,我们肯定要定义一个 dp[pos],表示当前在第
p
o
s
pos
pos 位,对于这道题,我们还要多定义一维:
s
u
m
sum
sum(英文全称 summation,中文意思:总和),表示当前有多少个指定数字,具体意思详见代码或状态转移方程。
然后我们就可以开始写代码了。
有人问:为啥不写状态转移方程。原因:干写太难写了,结合者代码好点。
代码:
#include<bits/stdc++.h>
#define int long long
using namespace std;
int a,b,now,len,num[16],dp[16][16][2][2];
int dfs(int id,int sum,bool lead,bool limit)
{
int ans=0;
if(id==0)//到第 0 位了……
{
return sum;
}
if(dp[id][sum][lead][limit]!=-1)//经典记忆化搜索
{
return dp[id][sum][lead][limit];
}
int n=(limit?num[id]:9);
//判断这一位有没有限制,如果有,取出当前这一位的数,也就是这一位能达到的最大的数,否则就是 9
for(int i=0;i<=n;i++)//循环当前这一位能取哪些数,记录答案
{
if(i==0&&lead)//有前导 0(前面有,这一位也是 0)
{
ans+=dfs(id-1,sum,true,limit&&i==n);
//如果这一位有限制且正好循环到上限,那么下一位也会有限制
//如 324,如果当前已经到 320(也就是当前这一位最大了),那么接下来的范围就只有 320~324
//如果到了310(也就是当前这一位还没到最大),那就没什么
}
else if(i==now)//算到目标数字了,也没有前导 0
{
ans+=dfs(id-1,sum+1,false,limit&&i==n);//计数加一
}
else if(i!=now)//其他情况,没有前导 0
{
ans+=dfs(id-1,sum,false,limit&&i==n);
}
}
dp[id][sum][lead][limit]=ans;//记忆化搜索
return ans;//返回答案
}
int solve(int x)
{
memset(dp,-1,sizeof(dp));
len=0;
while(x)//求数的长度,以确定当前在哪一位
{
num[++len]=x%10;
x/=10;
}
//为了方便后续写代码,我们一般会在意识里的原数前面多加一位 0,实际上是没有的
return dfs(len,0,true,true);//于是就有了前导 0 与限制
}
signed main()
{
cin>>a>>b;
for(int i=0;i<10;i++)//统计每一个数
{
now=i;
cout<<solve(b)-solve(a-1)<<" ";//一个类似前缀和的做法
}
return 0;
}
如果你看完代码感觉明白了,那恭喜你,你已经大致掌握了数位 DP 了!其他的题目大致就是把这几个参数改来改去就对了。没理解的同学我也没法再跟你解释了,因为数位 DP 就这样,实在不行多读几遍就懂了。(人生导师上线:当时我初学数位 DP 的时候,我直接被绕晕了,一直没搞懂这个上限、前导 0 0 0 的处理,直到翻开书的第三遍,我“不小心”把书翻烂了……不重要,重要的是我学懂了数位 DP。)
例题
洛谷 P2657
题目描述:不含前导零且相邻两个数字之差至少为 2 2 2 的正整数被称为 windy 数。windy 想知道,在 a a a 和 b b b 之间,包括 a a a 和 b b b ,总共有多少个 windy 数?
输入格式:输入只有一行两个整数,分别表示 a a a 和 b b b。
输出格式:输出一行一个整数表示答案。
数据规模与约定:对于全部的测试点,保证 1 ≤ a ≤ b ≤ 2 × 10 9 1 \leq a \leq b \leq 2 \times 10^9 1≤a≤b≤2×109。
跟上面那道例题很像,改一下 s u m sum sum 的意义就行了。
代码:
#include<bits/stdc++.h>
#define int long long
using namespace std;
int a,b,len,num[16],dp[16][16][2][2];
int dfs(int id,int last,bool lead,bool limit)
{
int ans=0;
if(id==0)
{
return 1;
}
if(dp[id][last][lead][limit]!=-1)
{
return dp[id][last][lead][limit];
}
int n=(limit?num[id]:9);
for(int i=0;i<=n;i++)
{
if(abs(i-last)<2)
{
continue;
}
else if(i==0&&lead)
{
ans+=dfs(id-1,-2,true,limit&&i==n);
}
else
{
ans+=dfs(id-1,i,false,limit&&i==n);
}
}
dp[id][last][lead][limit]=ans;
return ans;
}
int solve(int x)
{
memset(dp,-1,sizeof(dp));
len=0;
while(x)
{
num[++len]=x%10;
x/=10;
}
return dfs(len,-2,true,true);
}
signed main()
{
cin>>a>>b;
cout<<solve(b)-solve(a-1)<<" ";
return 0;
}
洛谷 P4124
题目描述:人们选择手机号码时都希望号码好记、吉利。比如号码中含有几位相邻的相同数字、不含谐音不吉利的数字等。手机运营商在发行新号码时也会考虑这些因素,从号段中选取含有某些特征的号码单独出售。为了便于前期规划,运营商希望开发一个工具来自动统计号段中满足特征的号码数量。
工具需要检测的号码特征有两个:号码中要出现至少 3 3 3 个相邻的相同数字;号码中不能同时出现 8 8 8 和 4 4 4。号码必须同时包含两个特征才满足条件。满足条件的号码例如:13000988721、23333333333、14444101000。而不满足条件的号码例如:1015400080、10010012022。
手机号码一定是 11 11 11 位数,且不含前导的 0 0 0。工具接收两个数 L L L 和 R R R,自动统计出 [ L , R ] [L,R] [L,R] 区间内所有满足条件的号码数量。 L L L 和 R R R 也是 11 11 11 位的手机号码。
输入格式:输入文件内容只有一行,为空格分隔的 2 2 2 个正整数 L , R L,R L,R。
输出格式:输出文件内容只有一行,为 1 1 1 个整数,表示满足条件的手机号数量。
数据范围: 10 10 ≤ L ≤ R < 10 11 10^{10}\leq L\leq R<10^{11} 1010≤L≤R<1011。
参数稍微多亿点,注意没有前导 0 0 0!
代码:
#include<bits/stdc++.h>
#define int long long
using namespace std;
int a,b,len,num[16],dp[16][16][16][2][2][2][2];//这数组……
int dfs(int id,int last,int llast,bool x,bool is4,bool is8,bool limit)
//当前在第几位,上一个是什么数,上上个是什么数,是否有三个连续相同的数,出现 4 没有,出现 8 没有,有没有限制
{
int ans=0;
if(is4&&is8)
{
return 0;
}
if(id==0)
{
return x;
}
if(dp[id][last][llast][x][is4][is8][limit]!=-1)
{
return dp[id][last][llast][x][is4][is8][limit];
}
int n=(limit?num[id]:9);
for(int i=0;i<=n;i++)
{
ans+=dfs(id-1,i,last,x||(i==last&&i==llast),is4||i==4,is8||i==8,limit&&i==n);
}
dp[id][last][llast][x][is4][is8][limit]=ans;
return ans;
}
int solve(int x)
{
memset(dp,-1,sizeof(dp));
len=0;
while(x)
{
num[++len]=x%10;
x/=10;
}
if(len!=11)
{
return 0;
}
int ans=0;
for(int i=1;i<=num[len];i++)
{
ans+=dfs(len-1,i,0,0,i==4,i==8,i==num[len]);
}
return ans;
}
signed main()
{
cin>>a>>b;
cout<<solve(b)-solve(a-1)<<" ";
return 0;
}
状压 DP 详解
原文章链接:http://blog.youkuaiyun.com/cwplh/article/details/147670307?spm=1011.2415.3001.5331
简介
状压 DP 其实约等于一个 DP 的小技巧,一般应用在处理一个或多个集合的问题中(因为状压 DP 的下标就是一个集合),而且在 n n n 太大的时候建议不要使用这种方法。(如果你不懂,那么就继续往下看。好吧你本来就不懂。)
做法
状压 DP 的本质就是用一连串的 0 / 1 0/1 0/1 表示一个集合中的每一个元素的状态,很像二进制,所以状压 DP 的下标大小一般都是 2 n 2^n 2n(如果 n n n 很大,那么你就会收到一份 M L E \color{darkblue}{MLE} MLE 大礼包,好吧有时候是 C E \color{yellow}{CE} CE)。
然后我们就可以用位运算来操作与处理,为了方便讲解,我们选择一道例题:
洛谷 P1171
某乡有 n ( 2 ≤ n ≤ 20 ) n\ (2\le n\le 20) n (2≤n≤20) 个村庄,有一个售货员,他要到各个村庄去售货,各村庄之间的路程 s ( 0 < s < 1000 ) s\ (0<s<1000) s (0<s<1000) 是已知的,且 A A A 村到 B B B 村与 B B B 村到 A A A 村的路大多不同。为了提高效率,他从商店出发到每个村庄一次,然后返回商店所在的村,假设商店所在的村庄为 1 1 1,他不知道选择什么样的路线才能使所走的路程最短。请你帮他选择一条最短的路。
这道题一看就知道肯定能写最短路,但是我们讲的是状压 DP,那就拿状压 DP 写吧。
首先确定下标是什么。状压 DP 下标的第一维肯定是当前状态,那是啥的状态呢?一看: n ≤ 20 n\le20 n≤20。这不妥妥的天生状压 DP 之体吗?所以状态就很简单了:当前这个点走没走过(也只能这么定义了,又不可能定义这个点存不存在,如果是这样的话那这个村子都没了还走个什么)。然后第二位就是图上 DP 的经典操作——当前在哪个点——了啊。一算总大小,刚好 10 7 = 10000000 10^7=10000000 107=10000000 左右( 2 20 = 1048576 2^{20}=1048576 220=1048576),不多不少。
那么 dp[i][j] 的定义自然就是在
i
i
i 这个状态下从第
1
1
1 个点到第
j
j
j 个点的最短距离。
其次就是状态转移方程了。首先状压 DP 的标配就是枚举当前状态,即从 00 … 0 ⏟ n 个 0 \underbrace{00\dots0}_{n\ \text{个}\ 0} n 个 0 00…0 到 11 … 1 ⏟ n 个 1 \underbrace{11\dots1}_{n\ \text{个}\ 1} n 个 1 11…1(在十进制下就是从 0 0 0 到 2 n − 1 2^n-1 2n−1,这个减 1 1 1 的原因是因为二进制是从第 0 0 0 位开始算的,不是第 1 1 1 位,所以说最高位实际上是第 n − 1 n-1 n−1 位,正好 2 n − 1 2^n-1 2n−1 就有 n − 1 n-1 n−1 位,且能极好的表达 11 … 1 ⏟ n 个 1 \underbrace{11\dots1}_{n\ \text{个}\ 1} n 个 1 11…1 这个数),这就是第一层循环。
其次肯定要枚举当前在哪个点。那对于当前所在的点我们就要进行分类讨论了:这个点在当前状态下走过还是没走过。现在我们不要管实际上是不是真的走过某个点,我们就认为当前这个状态就是对的。那走过的肯定不用说,走都走过了还有什么好更新的,关键在于没走过的。
没走过的我们就按照类似 Floyd 的方法,即给它找一个中转点(毕竟 Floyd 的本质不就是一个类似于 DP 的东西吗),所以我们只需要再浅浅的加一层循环找一个中转点,当然,这个中转点必须是当前状态下已经走过的点。(你自己都没走过还想帮别人。)
于是我们就可以写出一份伪代码:
memset(dp,0x3f3f3f3f,sizeof(dp));
dp[1][1]=0;//初始化:走过 1 且从 1 到 1 的距离等于没有距离(没走过一个点怎么走?)
for(int i=0;i<(1<<n);i++)
{
for(int j=1;j<=n;j++)
{
if(!((1<<j-1)&i))
{
for(int k=1;k<=n;k++)
{
if((1<<k-1)&i)
{
dp[i|(1<<j-1)][j]=min(dp[i|(1<<j-1)][j],dp[i][k]+a[k][j]);
}
}
}
}
}
有人会说:你这个时间复杂度一看就是 O ( 2 n × n 2 ) O(2^n\times n^2) O(2n×n2) 啊,这不包超时的吗?啊,其实是不会的,因为你看到第 5 5 5 行没有?这一句话会帮我省掉大部分循环,所以总体时间复杂度是肯定没有那么高的,是肯定不会超时的。
于是我们就可以写出完整代码:
#include<bits/stdc++.h>
using namespace std;
int n,ans=0x3f3f3f3f,a[26][26],dp[1050006][26];
signed main()
{
cin>>n;
for(int i=1;i<=n;i++)
{
for(int j=1;j<=n;j++)
{
cin>>a[i][j];
}
}
memset(dp,0x3f3f3f3f,sizeof(dp));
dp[1][1]=0;
for(int i=0;i<(1<<n);i++)
{
for(int j=1;j<=n;j++)
{
if(!((1<<j-1)&i))
{
for(int k=1;k<=n;k++)
{
if((1<<k-1)&i)
{
dp[i|(1<<j-1)][j]=min(dp[i|(1<<j-1)][j],dp[i][k]+a[k][j]);//中转一下
}
}
}
}
}
for(int i=2;i<=n;i++)
{
ans=min(ans,dp[(1<<n)-1][i]+a[i][1]);//在经过了所有点的情况下最后走那个点路程最短呢?
}
cout<<ans;
return 0;
}
以上就是状压 DP 的全部内容了。喜欢的同学们麻烦点个赞、收藏一下,我们下期再见。

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









