




 本文通过掷骰子实例深入浅出地介绍了隐马尔科夫模型(HMM)的基础概念及其三大核心问题:概率计算问题、学习问题与预测问题。并通过Java代码实现了解决概率计算与预测问题的具体算法。
本文通过掷骰子实例深入浅出地介绍了隐马尔科夫模型(HMM)的基础概念及其三大核心问题:概率计算问题、学习问题与预测问题。并通过Java代码实现了解决概率计算与预测问题的具体算法。
转自:http://luchi007.iteye.com/blog/2269548
隐马尔科夫模型,Hidden Marcov Model,是可用于标注问题的统计学习模型,描述由隐藏的马尔科夫链随机生成观测序列的过程,属于生成模型,是一种比较重要的机器学习方法,在语音识别等领域有重要的应用。
本文不打算使用书面的一大堆公式来说明,本人对公式无感,能用例子说明的根本不想碰公式,不知道是不是霍金说过,多加一条公式就会损失一大片读者。PS:不管有没有说过了,是这个意思,whatever
首先说明一下基本概念,概念来自李航《统计学习方法》第十章【1】

然后根据书中的例子,来具体说明一下HMM的三要素功能
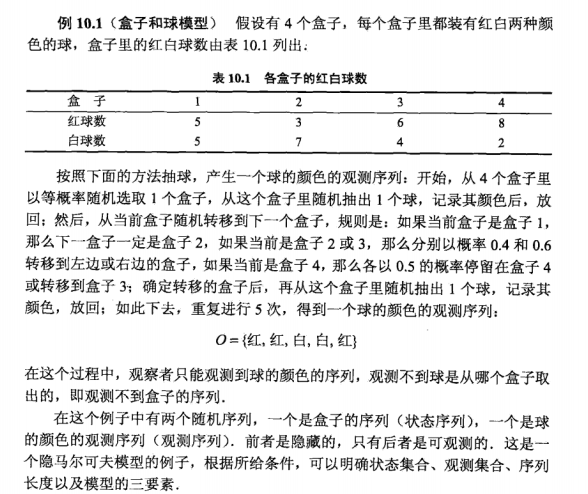

书中的例子举得很明白,所以现在应该也了解了隐马尔科夫模型的三个要素了
下面通过博客园博主Skyme的博文《一文搞懂HMM》【2】的例子对HMM做一个代码上的解释,需要说明的是,我无意侵犯其知识产权,只是觉得该文举得例子比较好,所以就想拿过来用,毕竟自己画图举例什么的太过麻烦,博文原地址我也给出来了,算是论文里面的引用吧。
好的言归正传,我们来看一下HMM需要解决的基本的三个问题,仍然是使用【1】书的内容:

结合具体的问题,来看一下这三个问题究竟是什么。
假设我手里有三个不同的骰子。第一个骰子是我们平常见的骰子(称这个骰子为D6),6个面,每个面(1,2,3,4,5,6)出现的概率是1/6。第二个骰子是个四面体(称这个骰子为D4),每个面(1,2,3,4)出现的概率是1/4。第三个骰子有八个面(称这个骰子为D8),每个面(1,2,3,4,5,6,7,8)出现的概率是1/8。
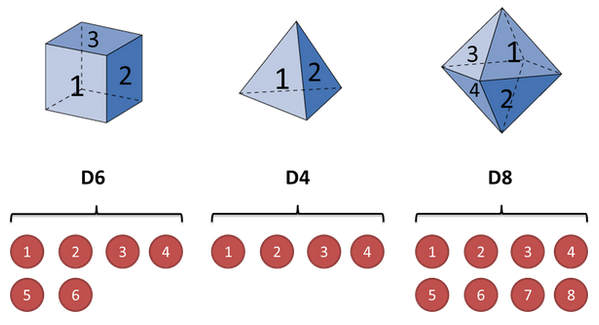
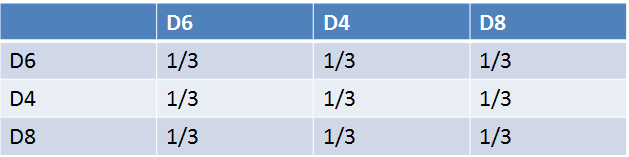
我们假设开始掷骰子的时候的初始概率是一样的也就是1/3,则初始状态是 PI={1/3,1/3,1/3} 分别对应于D6,D4,D8, 为了方便阐述,我们假设每个状态的转移概率都是1/3,则转移矩阵(也就是上文提到的A矩阵)是
然后观测结果集合是{1,2, 3, 4,5, 6, 7, 8}
每个状态的观测概率矩阵,也就是上文提到的B矩阵是
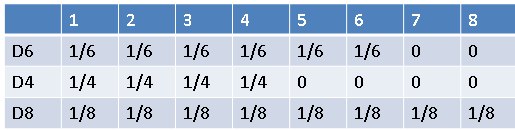
到此,PI,A,B 这HMM三要素都到齐了,至于观测序列,则根据具体的问题具体说明
现在模型已经给出了,让我们看一下HMM的三个问题对于这个问题的具体实现
[1],概率计算问题:我们已知上面的HMM模型参数,也知道现在的观测序列,现在我们想知道从原始模型到这个观测序列的概率是多少。
现在我们假设现在的观测序列是 1-6-3
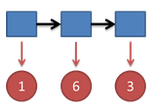
我现在想知道从之前的模型参数值(PI,A,B)掷骰子到1-6-3的概率有多大
解决办法:
如果使用最原始的首先枚举出每个可能的状态集然后分别求概率,然后把这些概率想加,这种办法的效率太低,因此需要使用一种更加好的算法来计算
这里使用的是前向算法,计算理论推导在【1】书中有详细的过程,这里使用【2】举得例子

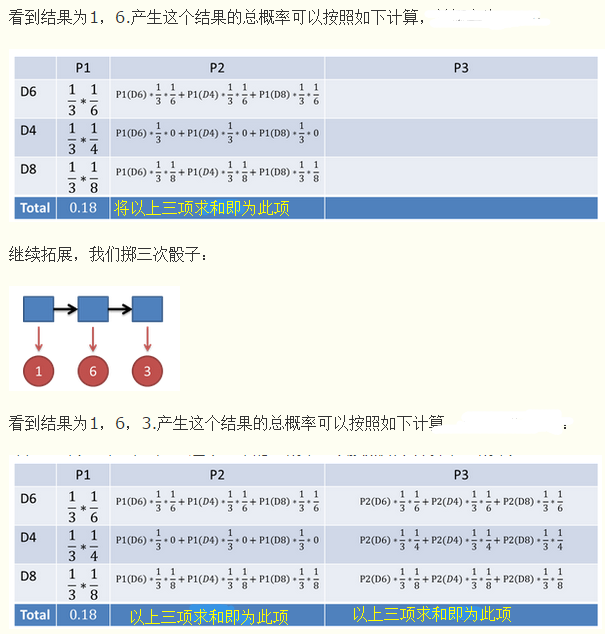
需要说明的是原文的计算结果似乎是有错误,所以这里讲原文的求和数据省去了,但是方法还是一样计算,这下应该是很明了的的计算方法,就像一条计算链条,多长的结果都能计算出来,下面是代码实现过程:

- package com.luchi.hmm;
- import com.luchi.hmm.problem1.status;
- /*
- * @description
- * 隐马尔科夫模型主要解决的是三个问题
- * 1,预测问题,也就是解码问题,已知模型lambda=(A,B,PI)和观测序列,其给定观测序列条件概率P(I|O)最大的状态序列I
- * 2,概率计算问题:给定模型lambda=(A,B,PI)和观测序列O,计算在该模型lambda下观测序列O出现的概率P(O|lambda)
- * 3,学习问题,已知观测序列O,估计模型lambda=(A,B,PI)的参数
- *
- * 这里解决的是第二个问题,也就是计算概率问题,这里使用了前向算法
- * @author:luchi
- */
- public class problem2 {
- //定义状态转移矩阵
- double [][]trans=new double[][]{
- {0.33,0.33,0.33},
- {0.33,0.33,0.33},
- {0.33,0.33,0.33},
- };
- //状态名称
- enum status{
- D6,
- D4,
- D8
- };
- //总状态数
- int status_length=3;
- //掷骰子事件分别是1,2,3,4,5,6
- //每个状态下掷骰子事件发生概率
- double[][] emission_probability = new double[][]{
- {0.167, 0.167, 0.167,0.167,0.167,0.167,0,0},
- {0.250,0.250,0.250,0.250,0,0,0,0},
- {0.125,0.125,0.125,0.125,0.125,0.125,0.125,0.125}
- };
- int activity_length=emission_probability[0].length;
- //观察序列为
- int []observation=new int[]{1,6,3};
- //初始序列
- double[]start=new double[]{0.33,0.33,0.33};
- //计算出现的概率
- public void calcuProb(){
- double[][]midStore=new double[observation.length][status_length];
- double totalProb=0.0;
- //初始化第一个概率
- for(int i=0;i<status_length;i++){
- double temp=start[i]*emission_probability[i][observation[0]-1];
- midStore[0][i]=temp;
- totalProb+=temp;
- }
- if(observation.length>=1){
- for(int i=1;i<observation.length;i++){
- totalProb=0.0;
- int desPos=observation[i]-1;
- for(int j=0;j<status_length;j++){
- double temp=0.0;
- for(int t=0;t<status_length;t++){
- temp+=midStore[i-1][t]*trans[t][j]*emission_probability[j][desPos];
- }
- midStore[i][j]=temp;
- totalProb+=temp;
- }
- System.out.println(totalProb);
- }
- }
- }
- public static void main(String[]args){
- problem2 p=new problem2();
- p.calcuProb();
- }
- }
算出来的结果是:0.003082643085456001
[2],学习问题:知道骰子有几种(隐含状态数量),不知道每种骰子是什么(转换概率),观测到很多次掷骰子的结果(可见状态链),我想反推出每种骰子是什么(转换概率)。
也就是不知道上面所描述的HMM模型参数(PI,A,B),现在需根据观测结果O 来反推HMM的参数,这是一个学习过程,也是一个比较重要的问题,一般使用E-M算法进行推导,因为可以把HMM的状态模型看作是未知参数,因此就有了E步和M步,因为本人对EM算法的理解还处于高斯混合模型GMM阶段,并不算很熟悉,所以不打算详细介绍,有兴趣的话可以看【1】的第181-184的推导
[3].预测问题:知道HMM的参数(PI,A,B)也已知观测掷骰子的结果O(o1,o2,o3,o4...),现在想知道o1,o2,o3...是由哪些骰子(D6,D4,D8)掷出来的
这里使用的是维特比算法,维特比算法实际上是用动态规划求解隐马尔科夫预测问题,也就是使用动态规划求解概率最大路径,这个时候一条路径对应的一个状态序列。下面通过一个例题说明:

由此可见,维特比算是其实是一个类似回溯算法一样的计算过程,每个阶段都储存上一个阶段到这个阶段概率最大的状态,然后到达最终态的时候回溯找到状态序列
还是以文章的掷骰子为题为例,HMM的模型(PI,A,B)都不变,现在观察到的点数(观测序列)是(1 6 3 5 2 7 3 5 2 4),然后我们根据维特比算法来求解最大概率的掷到这个点数序列的状态集
(也就是是哪个筛子掷的的集合),根据上图例10.3的维特比算法的说明可以将这个问题用以下代码实现
- package com.luchi.hmm;
- /*
- * @description
- * 隐马尔科夫模型主要解决的是三个问题
- * 1,预测问题,也就是解码问题,已知模型lambda=(A,B,PI)和观测序列,其给定观测序列条件概率P(I|O)最大的状态序列I
- * 2,概率计算问题:给定模型lambda=(A,B,PI)和观测序列O,计算在该模型lambda下观测序列O出现的概率P(O|lambda)
- * 3,学习问题,已知观测序列O,估计模型lambda=(A,B,PI)的参数
- *
- * 这个首先解决的是第一个问题,也就是预测问题,主要有两种算法,一个是近似算法,一个是维特比算法,这里使用了viterbi算法
- @author:luchi
- * */
- public class problem1 {
- //定义状态转移矩阵
- double [][]trans=new double[][]{
- {0.33,0.33,0.33},
- {0.33,0.33,0.33},
- {0.33,0.33,0.33},
- };
- //状态名称
- enum status{
- D6,
- D4,
- D8
- };
- //总状态数
- int status_length=3;
- //掷骰子事件分别是1,2,3,4,5,6
- //每个状态下掷骰子事件发生概率
- double[][] emission_probability = new double[][]{
- {0.167, 0.167, 0.167,0.167,0.167,0.167,0,0},
- {0.250,0.250,0.250,0.250,0,0,0,0},
- {0.125,0.125,0.125,0.125,0.125,0.125,0.125,0.125}
- };
- int activity_length=emission_probability[0].length;
- //观察序列为
- int []observation=new int[]{1,6,3,5,2,7,3,5,2,4};
- //初始序列
- double[]start=new double[]{0.33,0.33,0.33};
- //维特比算法求解
- public void viterbi(){
- //初始化存储中间矩阵
- double[][]midStore=new double[observation.length][status_length];
- int[][]traceBack=new int[observation.length][status_length];
- //初始化第一个数据
- for(int i=0,desPos=observation[0]-1;i<status_length;i++){
- midStore[0][i]=start[0]*emission_probability[i][desPos];
- }
- //从第二个观测序列开始计算
- for(int i=1;i<observation.length;i++){
- int desPos=observation[i]-1; //注意数组是从0开始的,而不是1
- for(int j=0;j<status_length;j++){
- double maxProb=-1;
- int traceStatus=0;
- //比较前面的序列
- for(int t=0;t<status_length;t++){
- double tempProb=midStore[i-1][t]*trans[t][j]*emission_probability[j][desPos];
- if(tempProb>maxProb){
- maxProb=tempProb;
- traceStatus=t;
- }
- }
- midStore[i][j]=maxProb;
- traceBack[i][j]=traceStatus;
- }
- }
- //比较最后一个阶段的最大概率
- int max_end_status=0;
- double max_end_prob=-1;
- for(int end_status=0;end_status<status_length;end_status++){
- double prob=midStore[observation.length-1][end_status];
- if(prob>max_end_prob){
- max_end_prob=prob;
- max_end_status=end_status;
- }
- }
- //回溯输出最大概率状态模型
- int []path=new int[observation.length];
- path[observation.length-1]=max_end_status;
- int curStatus=max_end_status;
- for(int i=observation.length-1;i>=1;i--){
- int preStatus=traceBack[i][curStatus];
- path[i-1]=preStatus;
- curStatus=preStatus;
- }
- for(int i=0;i<path.length;i++){
- System.out.println(status.values()[path[i]]);
- }
- }
- public static void main(String[]args){
- problem1 p=new problem1();
- p.viterbi();
- }
- }
预测的结果是:D4 D6 D4 D6 D4 D8 D4 D6 D4 D4
恩,这就是我对Hidden Morcov Model的浅见,不足之处还望指正
参考文献:
【1】李航 《统计学习方法》
【2】skyme 《一文搞懂HMM》 http://www.cnblogs.com/skyme/p/4651331.html#commentform
点击打开链接3 http://www.cnblogs.com/kaituorensheng/archive/2012/12/01/2797230.html

















 1097
1097

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









