



 本文介绍了如何使用Bluemix、Node-RED和IBM Analytics for Hadoop服务,无需编写代码即可收集、分析Twitter数据。通过设置Bluemix服务,构建Node-RED ETL工作流,分析推文并生成可视化图表,展示了大数据分析的便捷性。
本文介绍了如何使用Bluemix、Node-RED和IBM Analytics for Hadoop服务,无需编写代码即可收集、分析Twitter数据。通过设置Bluemix服务,构建Node-RED ETL工作流,分析推文并生成可视化图表,展示了大数据分析的便捷性。
本文是使用Bluemix经典界面编写的。 随着技术的飞速发展,某些步骤和插图可能已更改。
您是否认为您可以从分析社交数据中学到多少,但由于没有足够的时间或资源来构建所需的内容而没有采取行动? 在本教程中,我们向您展示了使用IBM Bluemix™中的Node-RED工作流编辑器捕获社交数据提要(Twitter提要)然后从该数据构建Hadoop分布式文件系统(HDFS)文件是多么容易。 我们还将向您展示如何使用IBM Analytics for Hadoop服务来分析数据并生成汇总图表。 您会惊讶于将未知数据集转换为可以使用的信息有多么容易。
“您会惊讶于将未知数据集转换为可以使用的信息如此容易。 ”
构建应用程序所需的条件
步骤1:设置Bluemix服务
为了实现提取,转换和加载(ETL)工作流,您将使用Bluemix中的Node-RED功能。 要开发流程,您首先需要创建一个Node-RED应用程序并将IBM Analytics for Hadoop服务添加到其中。
- 登录到您的Bluemix帐户 (或注册免费试用版 )。
- 单击目录 。
- 搜索,然后选择Node-RED Starter 。
- 在右侧的“ 名称”字段(也显示在“ 主机”字段中)中为您的应用程序输入示例名称,然后单击“ 创建” 。
等待您的Node-RED应用程序启动。 在使用该应用程序之前,您还需要向其添加IBM Analytics for Hadoop服务。
- 在左侧,单击Back to Dashboard ,然后单击您创建的Node-RED应用程序。
- 单击添加服务或API 。
- 在左侧的“ 类别”下,选中“ 大数据” 。 然后,在右侧,选择IBM Analytics for Hadoop 。
- 在右侧,单击App ,然后选择您的Node-RED应用程序。
- 单击创建 ,然后在出现提示时单击RESTAGE 。 等待应用程序重新启动并运行。
- 在顶部的Routes旁边,单击您的Node-RED应用程序的名称,例如sampleName .mybluemix.net(其中sampleName是您使用的名称),以使用您的Node-RED应用程序打开一个新的浏览器窗口。
- 单击标有转到您的Node-RED流编辑器的大按钮。
步骤2.在Node-RED中构建ETL工作流程
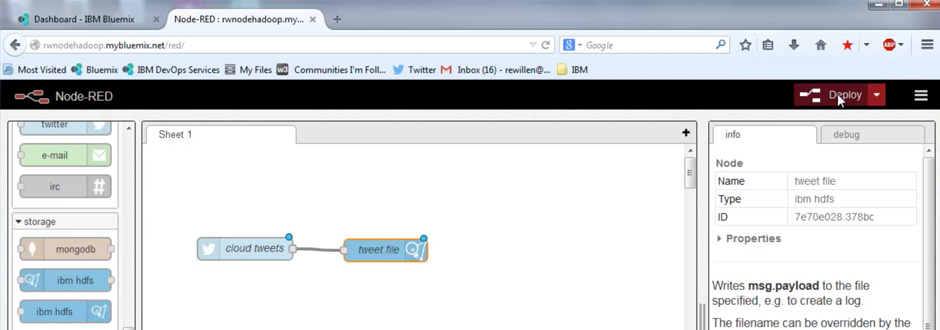
接下来,您将使用Node-RED工作流编辑器来构建ETL。 该流程从Twitter获取推文,并动态构建Hadoop分布式文件系统(HDFS)文件。 您将在下一步中使用此文件来分析推文。 Node-RED工作流程编辑器中完成的工作流程如下所示:
- 滚动面板,然后在social下,将Twitter输入节点拖到画布上。
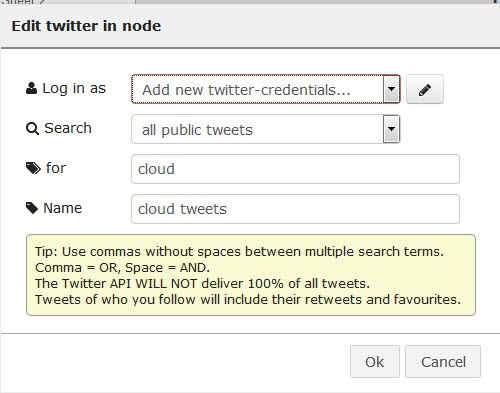
- 双击Twitter节点进行配置:
- 在“ 登录身份”下拉列表中,选择“ 添加新的Twitter凭据” ,然后单击铅笔图标。 单击按钮以对Twitter进行身份验证。 输入您的Twitter凭据,然后单击“ 授权应用程序” ,然后关闭该窗口。
- 确认已显示您的Twitter ID,然后单击添加 。
- 在for文本字段中,输入
cloud。 - 在“ 名称”字段中,输入
cloud tweets,然后单击“ 确定” 。
- 滚动面板,然后在storage下,选择第二个ibm hdfs节点(写)并将其拖到画布上。
- 使用鼠标将Twitter节点与hdfs节点连接。
- 双击ibm hdfs节点进行配置:
- 在“ 文件名”字段中,输入应用程序动态创建的文件的名称(例如
sampleTwitterData/stream)。 该文件包含符合您条件的推文。 - 单击确定 。
- 在“ 文件名”字段中,输入应用程序动态创建的文件的名称(例如
- 在Node-RED工作流程编辑器的右上角,单击Deploy 。
- 关闭浏览器窗口。
您的服务正在运行。 Twitter数据正在收集并写入文件。 该文件存在于Hadoop(BigInsights)服务的HDFS中,并且可以增长到20 GB,这是免费BigInsights服务在HDFS中的存储限制。
由于HDFS支持线性扩展,因此文件大小仅受预算限制。 您可以选择一个更高级的计划以获取更多存储空间。 已知最大的HDFS是Yahoo,运行455 PB,因此您可以看到Hadoop确实可以扩展。 Bluemix中的高级Hadoop集群在SoftLayer的裸机硬件上运行。 最小的是18 TB,但是如果需要,可以扩展到多个PB。
步骤3.使用IBM Analytics for Hadoop分析推文
既然ETL已经完成并且已经收集了数据,您就可以使用Bluemix中的IBM Analytics for Hadoop控制台来分析数据了。
- 返回到Bluemix。 在应用程序的“ 服务”部分中,单击“ IBM Analytics for Hadoop服务”。
- 在服务页面,单击启动开拓BigInsights控制台。
- 在IBM InfoSphere BigInsights中,单击“ 文件”选项卡,然后浏览文件浏览器以找到您创建的文件:
/user/biblumixsampleTwitterData/stream
- 选择文件上方的Sheet ,然后选择文件。
“工作表”按钮将打开BigSheets导入器。 您可以将BigSheets视为一个电子表格样式的Web应用程序,它能够分析多达PB的数据。 它通过在少量数据样本上定义实际的数据处理工作流,然后将数据处理工作流作为MapReduce流程推送到Hadoop集群,来管理大量数据。
- 单击另存为主工作簿 。
- 在名称字段中,输入
tweets - 单击保存 ,这将自动将您移至BigSheets选项卡。
- 在名称字段中,输入
- 单击“ 构建新工作簿” 。 您必须执行此步骤,因为默认情况下,您无法在BigSheets中修改初始工作簿中的数据,因为永远不会修改该工作簿所基于的原始文件。 创建新工作簿后,可以修改基础数据(如以下两个步骤所示)。
- 从下拉列表中选择添加图纸 ,然后选择功能 。
- 在“新建工作表:函数”对话框中,单击“ 类别” ,然后单击“ 实体” 。
- 滚动列表,然后单击“ 组织” 。 选择“组织”时,将使用内置的BigInsights(基于Watson / NLP)功能从数据中提取公司名称以进行分析。
- 从“ 填写参数”下拉列表中,选择“ 标题” ,然后单击绿色的复选标记。
表格的第一列(默认名称为Header)将用作基于IBM Watson技术的功能的输入,该功能从推文中提取公司名称。
- 在“组织”下显示在推文中与“云”一词一起提及的不同公司的列表。 该列表仅代表数据的一部分,可帮助您设计和测试分析。 单击保存 > 保存并退出 ,然后单击保存 。
- 在窗口中间,单击运行 。 现在,MapReduce作业将分析应用于HDFS文件中所有收集的推文。 等待直到窗口右上方的进度条显示100%。
- 单击添加图表 > 云 > 气泡云 ,然后单击绿色的复选标记。
最初,基于样本数据绘制图表。
- 再次单击“运行”以计算HDFS中所有数据的聚合。 等待直到窗口右上方的进度条显示100%。
最终结果显示了按组织分析的最近10分钟提到云的推文的计数分布。
这是运行应用程序时的示例图表; 您的图表会有所不同,因为您的Twitter流来自不同的时间段,并且社会影响可能非常动态,这就是为什么良好的分析如此重要的原因。 当您分析不同的时间片时,您可能会看到非常不同的结果。
例如,下图显示了在拉斯维加斯举行的IBM互连大会之后的图表:
现在,您可以关闭IBM InfoSphere BigInsights应用程序以及IBM Bluemix。
结论
本教程向您展示了如何使用Node-RED快速构建ETL工作流,以及如何分析使用IBM Analytics for Hadoop收集的数据。 整个项目都使用IBM Bluemix服务,因此您不必编写任何代码。 现在,您可以使用Node-RED构建其他工作流程,并可以分析使用Hadoop分析功能收集的任何数据。
翻译自: https://www.ibm.com/developerworks/analytics/library/ba-collect-analyze-social-data-app/index.html

















 1620
1620

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









