





 本文介绍了如何使用Amazon Athena服务查询存储在S3存储桶中的CSV文件数据,以及如何通过SQL Server Management Studio(SSMS)配置链接服务器进行查询。文章详细阐述了Athena的配置步骤,包括创建外部表,并展示了如何在SSMS中查询和下载Athena的查询结果。
本文介绍了如何使用Amazon Athena服务查询存储在S3存储桶中的CSV文件数据,以及如何通过SQL Server Management Studio(SSMS)配置链接服务器进行查询。文章详细阐述了Athena的配置步骤,包括创建外部表,并展示了如何在SSMS中查询和下载Athena的查询结果。
athena sql
This article covers the following topics:
本文涵盖以下主题:
- Overview of the Amazon Athena 亚马逊雅典娜概述
- Query CSV file stored in Amazon S3 bucket using SQL query 使用SQL查询来查询存储在Amazon S3存储桶中的CSV文件
- Create SQL Server linked server for accessing external tables 创建SQL Server链接服务器以访问外部表
介绍 (Introduction)
In the article, Data Import from Amazon S3 SSIS bucket using an integration service (SSIS) package, we explored data import from a CSV file stored in an Amazon S3 bucket into SQL Server tables using integration package. Amazon S3 is an object storage service, and we can store any format of files into it.
在文章“ 使用集成服务(SSIS)包从Amazon S3 SSIS存储桶中导入数据”中,我们探讨了使用集成包将存储在Amazon S3存储桶中的CSV文件中的数据导入SQL Server表中。 Amazon S3是一种对象存储服务,我们可以将任何格式的文件存储到其中。
Suppose we want to analyze CSV file data stored in Amazon S3 without data import. Many Cloud solution providers also provide a serverless data query service that we can use for analytical purposes. Amazon launched Athena on November 20, 2016, for querying data stored in the S3 bucket using standard SQL.
假设我们要分析存储在Amazon S3中的CSV文件数据而不导入数据。 许多云解决方案提供商还提供了无服务器数据查询服务,我们可以将其用于分析目的。 亚马逊于2016年11月20日推出了Athena,用于使用标准SQL查询存储在S3存储桶中的数据。
Athena can query various file formats such as CSV, JSON, Parquet, etc. but that file source should be S3 bucket. Customers do not manage the infrastructure, servers. They get billed only for the queries they execute. We also do not need to worry about infrastructure scaling. Amazon Athena automatically scales up and down resources as required. It can execute queries in parallel so that complex queries provide results quickly. We can also use it to analyze unstructured, semi-structured, and structured data from the S3 bucket.
雅典娜可以查询各种文件格式,例如CSV,JSON,Parquet等,但该文件源应为S3存储桶。 客户不管理基础架构服务器。 他们只为执行的查询付费。 我们也无需担心基础架构的扩展。 Amazon Athena会根据需要自动扩展资源。 它可以并行执行查询,以便复杂的查询快速提供结果。 我们还可以使用它来分析来自S3存储桶的非结构化,半结构化和结构化数据。
It also integrates with another AWS service Quicksight that provides data visualizations using business intelligence tools.
它还与另一个AWS服务Quicksight集成,该服务使用商业智能工具提供数据可视化。
We will use the Amazon Athena service for querying data stored in the S3 bucket. We will also use SSMS and connect it with Athena using linked servers.
我们将使用Amazon Athena服务来查询存储在S3存储桶中的数据。 我们还将使用SSMS,并使用链接服务器将其与Athena连接。
先决条件 (Prerequisites)
We have the following data in a CSV format file:
我们在CSV格式文件中包含以下数据:
Upload this file into an Amazon S3 bucket
将此文件上传到Amazon S3存储桶
If you do not have an Amazon S3 bucket, follow Data Import from Amazon S3 SSIS bucket using an integration service (SSIS) package
如果您没有Amazon S3存储桶,请遵循使用集成服务(SSIS)包从Amazon S3 SSIS存储桶导入数据的操作
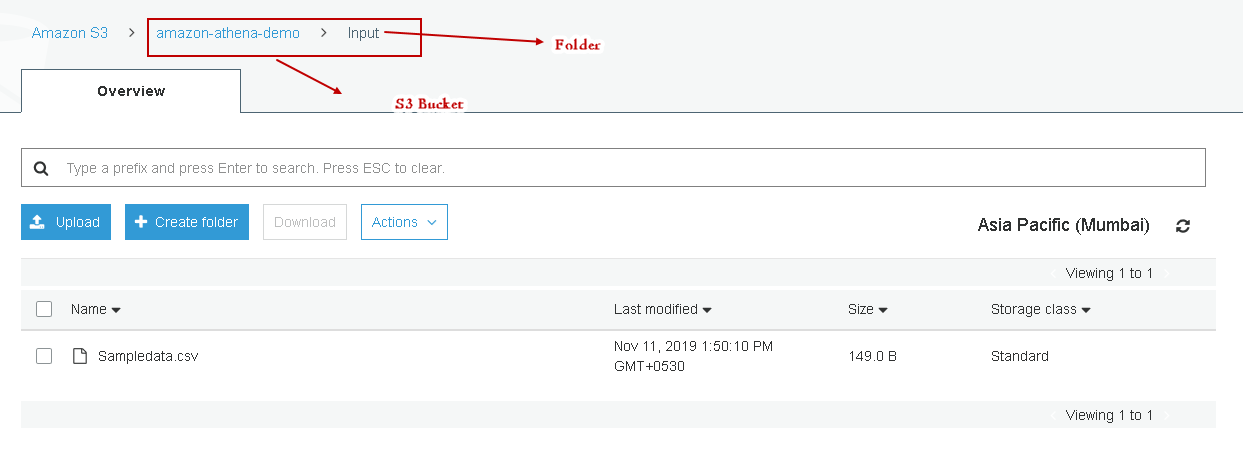
In this screenshot, we can see the following:
在此屏幕截图中,我们可以看到以下内容:
- S3 Bucket Name: amazon-athena-demo S3存储桶名称:amazon-athena-demo
- Filename: Sampledata.csv 文件名:Sampledata.csv
Amazon Athena的配置 (Configuration of Amazon Athena)
Navigate to services in AWS console, and you can find Athena under the Analytics group as shown below:
导航到AWS控制台中的服务,您可以在Analytics组下找到Athena,如下所示:
Click on Athena, and it opens the homepage of Amazon Athena, as shown below. It shows a brief description of the service and gives you high-level steps:
单击Athena ,它将打开Amazon Athena的主页,如下所示。 它显示了该服务的简要说明,并为您提供了高级步骤:
- Select a data set 选择一个数据集
- Create a table 建立表格
- Query data 查询数据
Click on Get Started button below the description:
单击说明下方的“入门”按钮:
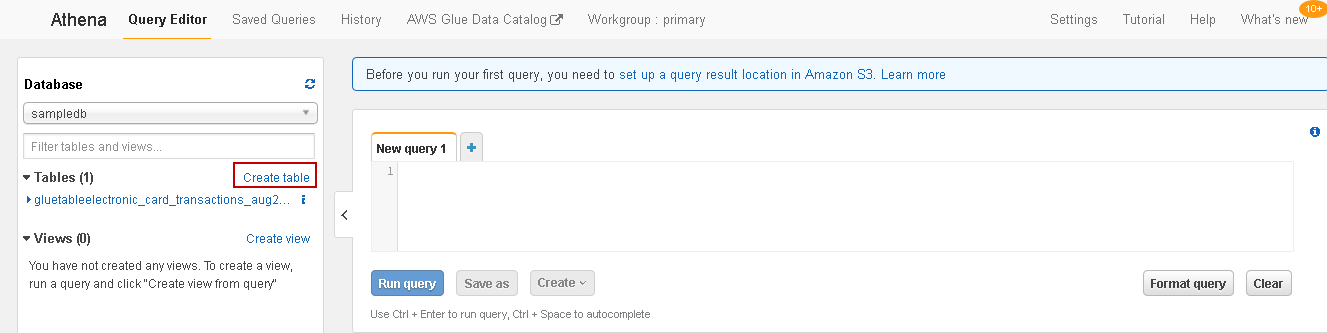
It opens the following screen. Click on Create table as highlighted above:
它打开以下屏幕。 单击创建表,如上面突出显示的那样:
It gives the following options:
它提供以下选项:
- Create a table from S3 bucket data 根据S3存储桶数据创建表
- Create a table from AWS Glue crawler 从AWS Glue搜寻器创建表
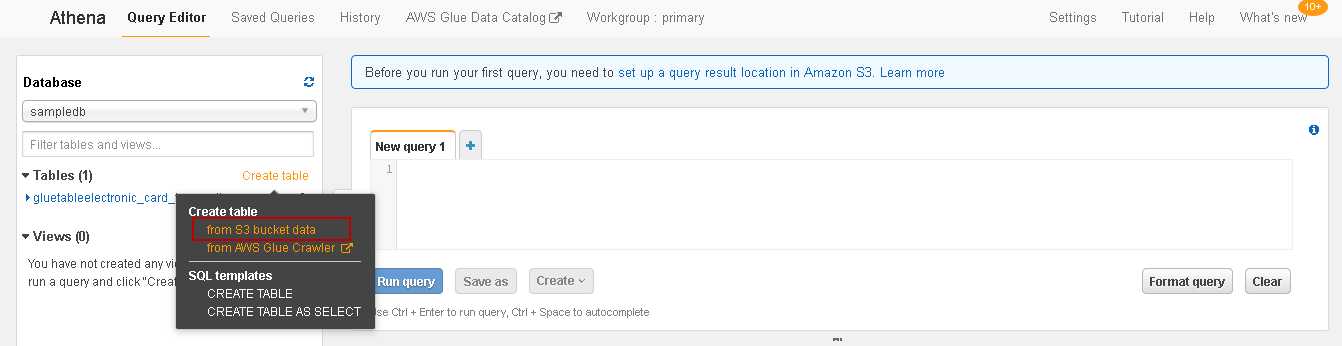
We have a CSV file stored in the Amazon S3 bucket, therefore, click on Create table from S3 bucket data. It opens a four-step wizard, as shown below:
我们有一个CSV文件存储在Amazon S3存储桶中,因此,单击根据S3存储桶数据创建表 。 它会打开一个四步向导,如下所示:
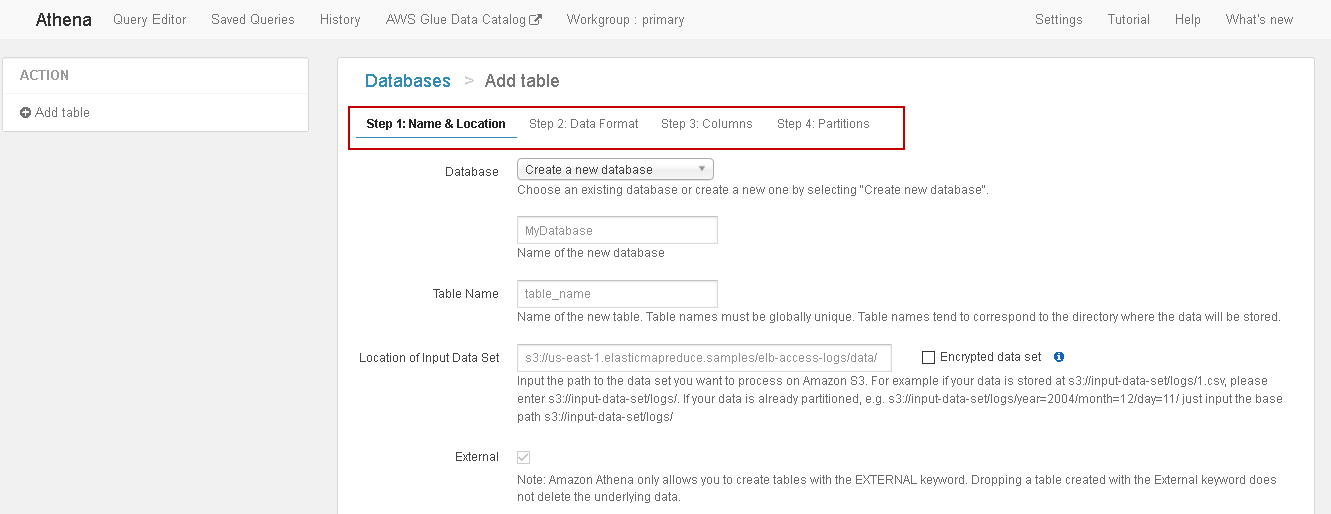
步骤1:名称和位置 (Step 1: Name & Location)
In this step, we define a database name and table name.
在此步骤中,我们定义数据库名称和表名称。
- Database: If you already have a database, you can choose it from the drop-down 数据库:如果您已经有一个数据库,则可以从下拉菜单中选择它
We do not any database, therefore, select Create a new database option and specify the desired database name.
我们没有任何数据库,因此,选择“ 创建新数据库”选项并指定所需的数据库名称。
- Table Name: Specify the name of the new table. It should be unique to the S3 bucket 表名称:指定新表的名称。 它对于S3存储桶应该是唯一的
- Location of input data set: Specify the location of the Amazon S3 bucket 输入数据集的位置:指定Amazon S3存储桶的位置
You need to enter the location in the following format:
您需要以以下格式输入位置:
S3://BucketName/folder name
S3:// BucketName /文件夹名称
In my example, the location is S3://amazon-athena-demo/ as can be seen in the 4th step:
在我的例子中,位置是S3://亚马逊雅典娜-演示/如可在第 4步骤中可以看出:
Click on Next, and it moves the wizard to the next page.
单击“ 下一步” ,它将向导移至下一页。
步骤2:资料格式 (Step 2: Data Format)
In this step, select the file format from the given options. In my example, we have a CSV file stored in the S3 bucket. Therefore, let’s choose the CSV format:
在此步骤中,从给定的选项中选择文件格式。 在我的示例中,我们在S3存储桶中存储了一个CSV文件。 因此,让我们选择CSV格式:
步骤3:栏 (Step 3: Columns)
In this step, we specify the column names and data type for each column available in the CSV:
在此步骤中,我们为CSV中可用的每一列指定列名称和数据类型:
It might be a tedious job to specify the column name and their data types for each column, especially we have a large number of columns. We can use bulk add columns to specify columns quickly.
为每一列指定列名及其数据类型可能是一件繁琐的工作,尤其是我们有大量的列。 我们可以使用批量添加列来快速指定列。
步骤4:分区 (Step 4: Partitions)
We do have complex data and do not require data partition. We can skip this step for this article.
我们确实有复杂的数据,不需要数据分区。 我们可以在本文中跳过此步骤。
In the next step, it shows the external table query. You can verify the database name that we specified in step 1:
在下一步中,它将显示外部表查询。 您可以验证我们在步骤1中指定的数据库名称:
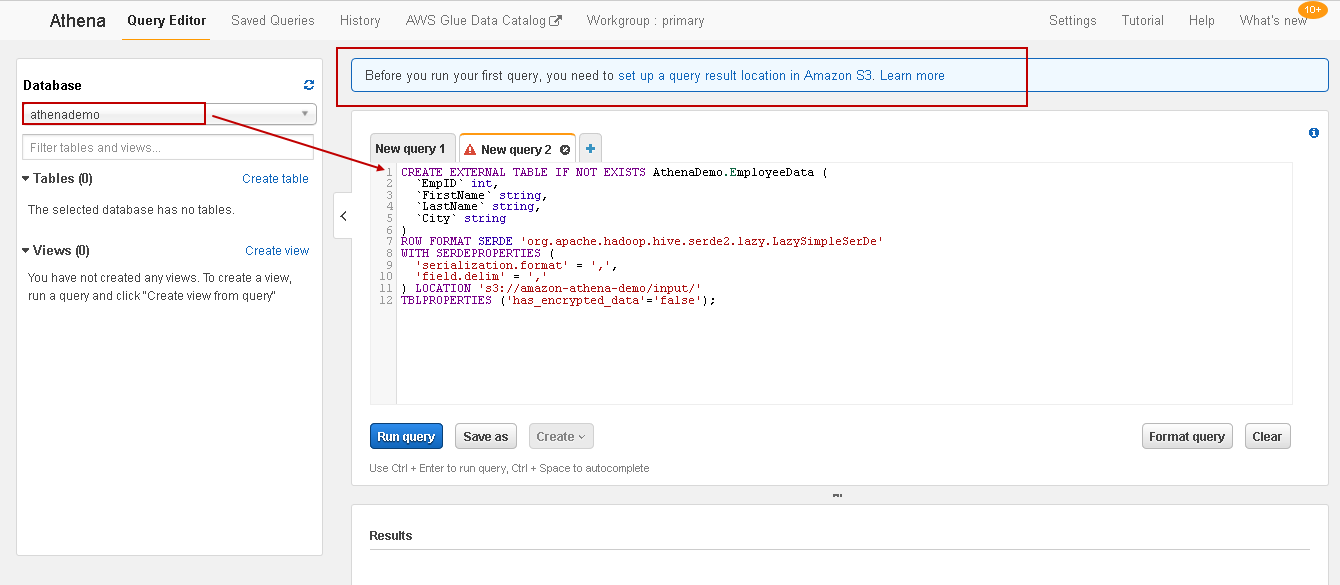
Before we execute the query, we need to specify the location of the query results, as shown in the highlighted message. Click on it, and it opens the pop-up box, as shown below:
在执行查询之前,我们需要指定查询结果的位置,如突出显示的消息所示。 单击它,它会打开弹出框,如下所示:
Specify the Query result location and save it.
指定查询结果位置并保存。
Query result format S3://bucketname/folder
查询结果格式S3:// bucketname / folder
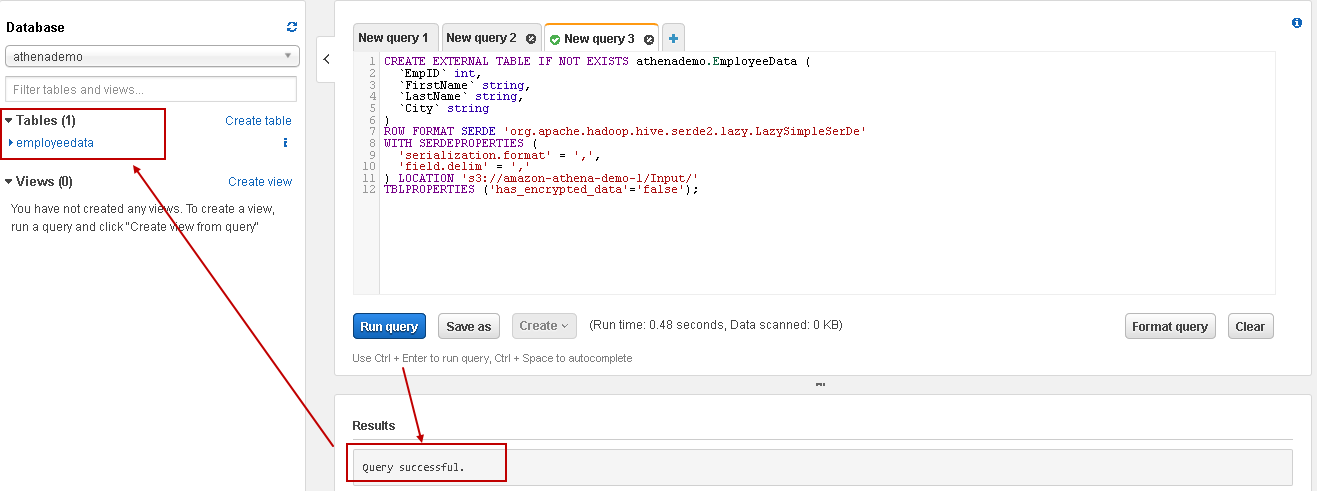
Now click on Run query, and it executes the query successfully for creating an external table. We can also see the newly created table in the tables list:
现在,单击Run query ,它将成功执行查询以创建外部表。 我们还可以在表列表中看到新创建的表:
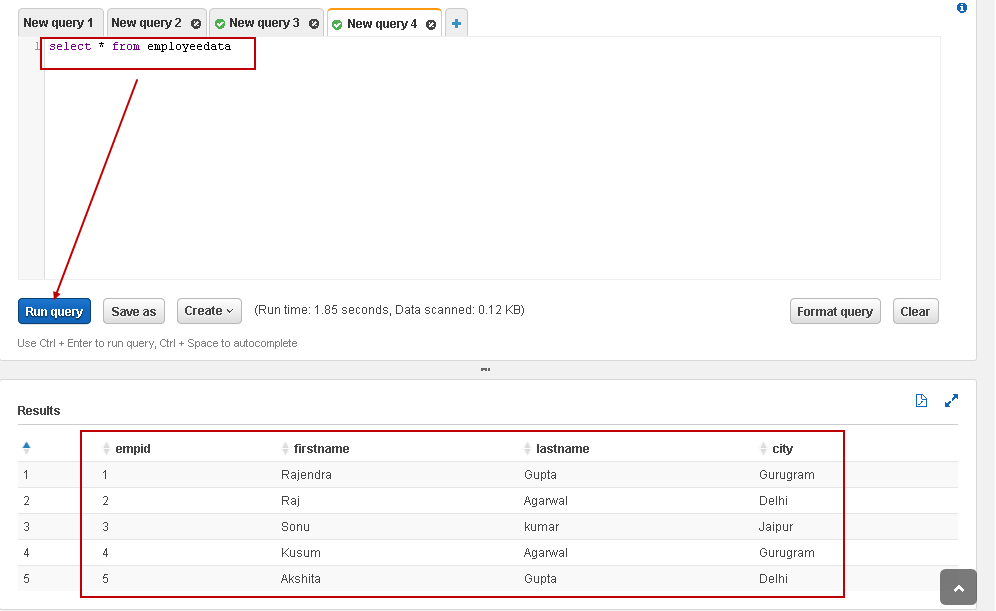
In the new query window, execute the following Select statement to view records from CSV file:
在新的查询窗口中,执行以下Select语句以查看CSV文件中的记录:
SELECT * FROM employeedata
In the following screenshot, we can see the data from the external table that is same as of the CSV file content:
在以下屏幕截图中,我们可以从外部表中看到与CSV文件内容相同的数据:
Let’s execute another query to filter the employee records belonging to Gurugram city:
让我们执行另一个查询以过滤属于Gurugram市的员工记录:
SELECT *
FROM employeedata
WHERE city='Gurugram';
Similarly, we can use SQL COUNT to check the number of records in the table:
同样,我们可以使用SQL COUNT来检查表中的记录数:
SELECT count(*) as NumberofRecords
FROM employeedata
It is a cool feature, right! We can directly query data stored in the Amazon S3 bucket without importing them into a relational database table. It is convenient to analyze massive data sets with multiple input files as well.
这是一个很酷的功能,对! 我们可以直接查询存储在Amazon S3存储桶中的数据,而无需将其导入关系数据库表中。 同样,使用多个输入文件分析海量数据集也很方便。
使用SSMS通过Amazon Athena查询S3存储桶数据 (Use SSMS to query S3 bucket data using Amazon Athena )
In this part, we will learn to query Athena external tables using SQL Server Management Studio.
在这一部分中,我们将学习使用SQL Server Management Studio查询Athena外部表。
We can access the data using linked servers.
我们可以使用链接的服务器访问数据。
配置链接服务器的步骤 (Steps for configuring linked server)
Download 64-bit Simba Athena ODBC driver using this link:
使用此链接下载64位Simba Athena ODBC驱动程序:
Click on Next and follow the installation wizard:
单击下一步,然后遵循安装向导:
Once installed, open the 64-bit ODBC Data source. It opens the following ODBC configuration. You can see a sample Simba Athena ODBC connection in the System DSN:
安装后,打开64位ODBC数据源。 它打开以下ODBC配置。 您可以在系统DSN中看到一个示例Simba Athena ODBC连接:
Click on Add and select the driver as Simba Athena ODBC Driver:
单击添加,然后选择驱动程序作为Simba Athena ODBC驱动程序 :
Click Finish, and it asks you to provide a few inputs:
点击完成 ,它要求您提供一些输入:
- Data Source Name: Specify any name of your choice for this ODBC connection 数据源名称 :为此ODBC连接指定您选择的任何名称
- AWS Region: It is the region of the S3 bucket that we use in the external table AWS区域 :这是我们在外部表中使用的S3存储桶的区域
- Schema: It is the external table name 模式 :这是外部表名称
- S3 Output Location: It is the S3 bucket location where the output will be saved S3输出位置 :这是将保存输出的S3存储桶位置
Authentication Option: Click on the authentication options and specify the access key, a private key for the IAM user. You can read more about the IAM user, access key and private key using the article Data Import from Amazon S3 SSIS bucket using an integration service (SSIS) package
身份验证选项 :单击身份验证选项,然后指定访问密钥,该密钥是IAM用户的私钥。 您可以使用使用集成服务(SSIS)软件包从Amazon S3 SSIS存储桶中的数据导入一文,了解有关IAM用户,访问密钥和私钥的更多信息。
Click OK and test the connection. It shows successful status if all entries are okay:
单击确定并测试连接。 如果所有输入都正确,它将显示成功状态:
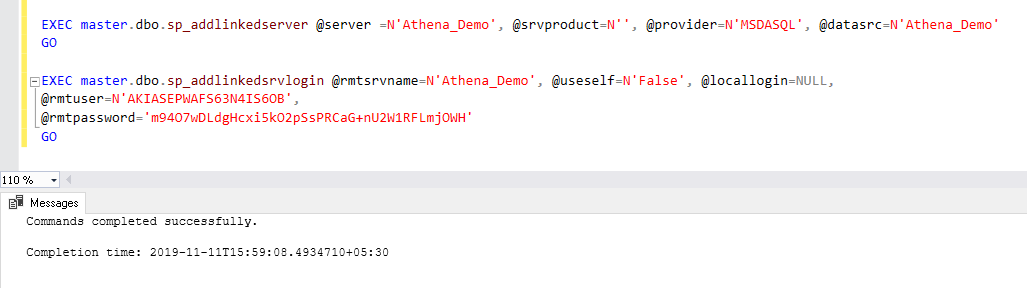
Let’s create the linked server for Amazon Athena using the ODBC connection we configured using the following query:
让我们使用通过以下查询配置的ODBC连接为Amazon Athena创建链接服务器:
EXEC master.dbo.sp_addlinkedserver @server =N'Athena_Demo', @srvproduct=N'', @provider=N'MSDASQL', @datasrc=N'Athena_Demo'
GO
EXEC master.dbo.sp_addlinkedsrvlogin @rmtsrvname=N'Athena_Demo', @useself=N'False', @locallogin=NULL,
@rmtuser=N'AKIASEPWAFS63N4IS6OB',
@rmtpassword='m94O7wDLdgHcxi5kO2pSsPRCaG+nU2W1RFLmjOWH'
GO
In this query, you can make changes in the following parameters:
在此查询中,您可以更改以下参数:
- @Server and @datasrc should contain an ODBC data source name @Server和@datasrc应该包含ODBC数据源名称
- @rmtuser should contain the Access key @rmtuser应该包含访问密钥
- @rmtpassword should contain the secret key @rmtpassword应包含密钥
Expand the Server objects, and we can see the linked server. Right-click on the linked server and click on test connection. In the following screenshot, we can see a successful linked server connection:
展开服务器对象,我们可以看到链接的服务器。 右键单击链接的服务器,然后单击测试连接。 在以下屏幕截图中,我们可以看到成功的链接服务器连接:
Now, expand the linked server, and we can see an external table:
现在,展开链接的服务器,我们可以看到一个外部表:
- Athena_Demo: Linked server name Athena_Demo:链接的服务器名称
- AWSDataCatalog: linked server catalog name AWSDataCatalog:链接服务器目录名称
- Athenademo.employeedata: external table name Athenademo.employeedata:外部表名称
To query an external table using a linked server, we query the table in the following format:
要使用链接服务器查询外部表,我们以以下格式查询表:
Select * from [1].[2].[3]
Here [1],[2] and [3] refers to objects as specified in the image above:
[1],[2]和[3]指的是上图中指定的对象:
We can view the actual execution plan of this query by pressing CTRL+M before executing the query. In the execution plan, we can see a remote query operator. We can hover the mouse over this operator and view the remote query operator property, query:
我们可以在执行查询之前按CTRL + M来查看此查询的实际执行计划。 在执行计划中,我们可以看到一个远程查询运算符。 我们可以将鼠标悬停在该运算符上,并查看远程查询运算符属性,查询:
Let’s execute another query for data filtering and view the actual execution plan:
让我们执行另一个查询以进行数据过滤并查看实际的执行计划:
Select * from [Athena_Demo].[AwsDataCatalog].[athenademo].[employeedata]
where empid>3
It filters the records at the Amazon Athena and does not cause SQL Server to filter records. It is an excellent way to offload data aggregation, computation over the data source:
它过滤Amazon Athena处的记录,并且不会导致SQL Server过滤记录。 这是卸载数据聚合,通过数据源进行计算的绝佳方法:
下载Amazon Athena查询结果 (Download Amazon Athena query results)
We can download the output of a query in AWS Athena in the following ways.
我们可以通过以下方式在AWS Athena中下载查询的输出。
查询编辑器控制台 (Query editor console)
Once we execute any query, it shows results as shown below. You can click on an icon to download the results in a CSV format:
一旦执行任何查询,它就会显示结果,如下所示。 您可以单击图标以CSV格式下载结果:
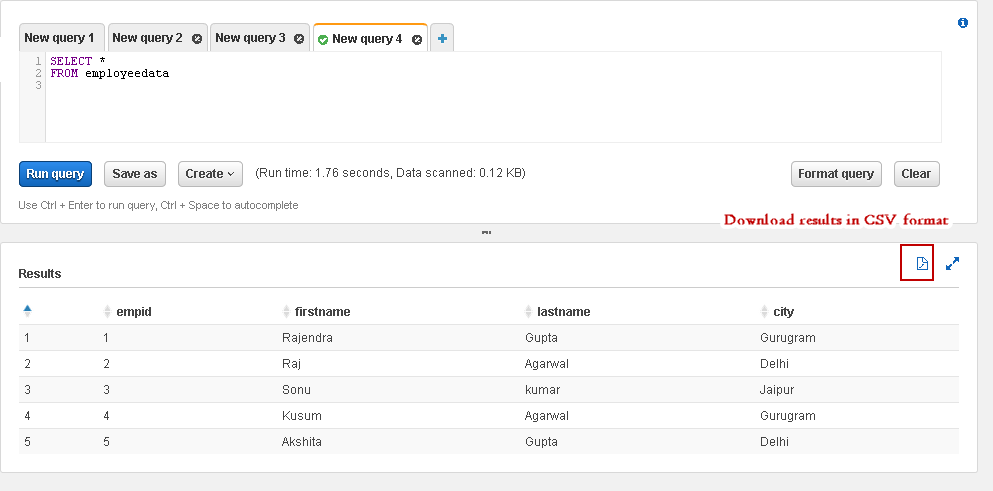
历史 (History)
We can use the history tab to view query history along with the query, status, run time, data size and download result in CSV format:
我们可以使用“历史记录”选项卡以CSV格式查看查询历史记录以及查询,状态,运行时间,数据大小和下载结果:
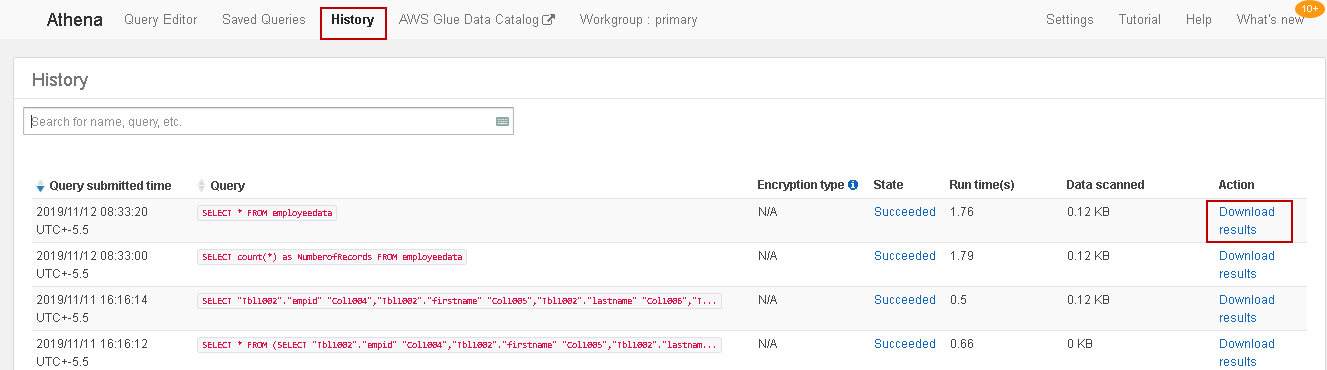
Amazon Athena的限制 (Restrictions of Amazon Athena)
- We can use it for DML operations only. We cannot use it for data definition language(DDL), Data Control Language(DCL ) queries 我们只能将其用于DML操作。 我们不能将其用于数据定义语言(DDL),数据控制语言(DCL)查询
- It works with external tables only 它仅适用于外部表
- We cannot define a user-defined function, procedures on the external tables 我们无法在外部表上定义用户定义的函数,过程
- We cannot use these external tables as a regular database table 我们不能将这些外部表用作常规数据库表
结论 (Conclusion)
In this article, we explored Amazon Athena for querying data stored in the S3 bucket using the SQL statements. We can use it in integration with SQL Server linked server as well. It is a handy feature for data analysis without worrying about the underlying infrastructure and computation requirements.
在本文中,我们探索了Amazon Athena,以使用SQL语句查询存储在S3存储桶中的数据。 我们也可以将其与SQL Server链接服务器集成使用。 它是用于数据分析的便捷功能,无需担心基础架构和计算需求。
翻译自: https://www.sqlshack.com/query-amazon-athena-external-tables-using-sql-server/
athena sql

















 1124
1124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









