





Monitoring databases for optimal query performance, creating and maintaining required indexes, and dropping rarely-used, unused or expensive indexes is a common database administration task. As administrators, we’ve all wished, at some point, that these tasks were simpler to handle.
监视数据库以获得最佳查询性能,创建和维护所需的索引以及删除很少使用,未使用或昂贵的索引是一项常见的数据库管理任务。 作为管理员,我们都希望在某些时候,这些任务更易于处理。
SQL Server 2017 can now assist database administrators in performing some of these routine operations by identifying problematic query execution plans and fixing problems with the SQL plan performance. Automatic tuning starts with continuously monitoring the database and learning about the workload that it serves. Automatic tuning is based on Artificial Intelligence, which makes managing the performance of the system flexible.
SQL Server 2017现在可以通过确定有问题的查询执行计划并修复SQL计划性能问题来帮助数据库管理员执行其中的一些常规操作。 自动调整开始于连续监视数据库并了解其服务的工作负载。 自动调整基于人工智能,这使得管理系统性能变得灵活。
SQL Server can use different strategies (or SQL plans) to execute a T-SQL query. SQL Server analyzes possible plans that can be used to execute a T-SQL query and chooses the optimal plan. The plans for most of the successfully executed queries are cached and reused when the same query is executed. The plan is retained in the cache until the SQL Database Engine decides to recompile the plan and find a new one (e.g. when statistics change, index is added or removed, etc.).
SQL Server可以使用不同的策略(或SQL计划)来执行T-SQL查询。 SQL Server分析可能用于执行T-SQL查询的计划,然后选择最佳计划。 执行同一查询时,大多数成功执行的查询的计划将被缓存并重新使用。 该计划将保留在缓存中,直到SQL数据库引擎决定重新编译该计划并找到一个新计划为止(例如,当统计信息更改,添加或删除索引等时)。
The most traditional way to troubleshoot performance issues is by measuring the wait statistics. These metrics are further classified into various categories. When SQL Server is executing and waiting for the resources, the corresponding entry is made in the system objects. We can query the system objects using DMV (Dynamic Management View) sys.dm_os_wait_stats. The nature of the DMV output is cumulative; it provides an aggregated value. It keeps adding the values at frequent intervals of time. The workaround for keeping track of values during each check or get a trend is by creating a repository and pull the data from the DMV and store it at frequent intervals of time for later querying. This gives the data for specific time period for performance analysis and troubleshooting the issues. This process is a little cumbersome; most administrators do not automate the process until they deep-dive into a particularly problematic situation. However, we can track the wait stats in the Query Store with a few simple steps. There are several options available to configure the Query Store. The wait stats are further grouped into wait categories. (There are over 900+ wait types available in SQL Server.) We can query the DMV sys.query_store_wait_stats to get the wait information. The wait categories are stored in the query store along with the date and the timestamp.
解决性能问题的最传统方法是测量等待统计信息。 这些指标进一步分为各种类别 。 当SQL Server执行并等待资源时,将在系统对象中进行相应的输入。 我们可以使用DMV(动态管理视图)sys.dm_os_wait_stats查询系统对象。 DMV输出的性质是累积的; 它提供了一个汇总值。 它会经常以一定的时间间隔添加值。 在每次检查或获取趋势期间跟踪值的解决方法是创建一个存储库,并从DMV中提取数据,并以一定的时间间隔存储该数据以供以后查询。 这样可以提供特定时间段的数据,以进行性能分析和问题排查。 这个过程有点麻烦。 大多数管理员只有在深入研究一个特别有问题的情况后,才能自动化该过程。 但是,我们可以通过几个简单步骤跟踪查询存储区中的等待状态。 有几个选项可用于配置查询存储。 等待统计信息进一步分为等待类别 。 (SQL Server中提供了900多种等待类型。)我们可以查询DMV sys.query_store_wait_stats以获取等待信息。 等待类别与日期和时间戳记一起存储在查询存储中。
The Query Store feature was introduced in SQL Server 2016. The SQL Server Query Store allows storing the history of queries, multiple plans, run time statistics, etc., and provides an insight into the query plan and performance of the database. This feature allows us to find regressed queries more easily. If a plan is not optimal and if there were plans that performed better, then we can unforce the plan, and use the more-optimal plan. This can be done using the stored procedures, sp_query_store_force_plan and sp_query_store_unforce_plan.
SQL Server 2016中引入了查询存储功能。SQLServer查询存储允许存储查询的历史记录,多个计划,运行时统计信息等,并提供对查询计划和数据库性能的深入了解。 此功能使我们可以更轻松地查找回归查询。 如果一个计划不是最佳计划,并且有一些计划的执行情况更好,那么我们可以取消该计划,而使用更优化的计划。 这可以使用存储过程sp_query_store_force_plan和sp_query_store_unforce_plan来完成。
Automatic plan correction is a new automatic tuning feature in SQL Server 2017 that identifies SQL query plans that are worse than the previous one, and fixes performance issues by applying the previous good plan instead of the regressed one. Doing so allows the database engine to identify opportunities where alterations to the execution plans might increase the performance of the system. By default, the Automatic Plan Correction feature is disabled.
自动计划更正是SQL Server 2017中的一项新的自动调整功能,可识别比上一个更差SQL查询计划,并通过应用以前的良好计划而不是回归计划来解决性能问题。 这样做可以使数据库引擎识别机会,对执行计划进行更改可能会提高系统性能。 默认情况下,自动计划更正功能处于禁用状态。
Also, automatic tuning can actually apply any suggested alterations according to its predictions. Finally—and this is the really smart part—automatic tuning continues to monitor the performance of the system after a change is made, to ensure that the expected results are achieved. If the change is found to not actually increase performance (or worse, found to negatively impact performance) it reverts such tuning recommendations.
同样,自动调整实际上可以根据其预测应用任何建议的更改。 最后,这是最聪明的部分,自动调整会在进行更改后继续监视系统的性能,以确保达到预期的结果。 如果发现更改并没有真正提高性能(或更糟的是,发现对性能有负面影响),它将还原此类调整建议。
Automatic Plan Correction(APC) is an extension of sp_query_sotre_force_plan. Forcing a plan is an effort to identify the optimal plan. However, it’s a manual effort in the Query Store to manage the plans (forcing and un-forcing actions are to be taken) for better performance. APC on the other hand is automatic in nature and is available in SQL Server 2017 as well as in Azure SQL Database. It uses the query store telemetry data to select and recommend the optimal plan. This is the reason the Query Store is a prerequisite.
自动计划校正(APC)是sp_query_sotre_force_plan的扩展。 强制执行计划是为了确定最佳计划。 但是,这是查询存储中的一项手动工作,用于管理计划(将执行强制和非强制操作)以提高性能。 另一方面,APC本质上是自动的,并且可在SQL Server 2017和Azure SQL数据库中使用。 它使用查询存储的遥测数据来选择和推荐最佳计划。 这就是查询存储是前提条件的原因。
- Query Store 查询存储中
- The most optimal plan is selected using dm_db_tuning_recommendations 使用dm_db_tuning_recommendations选择最佳计划
- Automatic Plan Correction takes place based on the data 根据数据自动进行计划更正
- The last good plan is reverted to 最后的好计划已还原为
使用SSMS启用查询存储 (Enable the Query Store using SSMS)
- Use Object Explorer to browse the database properties 使用对象资源管理器浏览数据库属性
- Query Store option 查询存储选项
In the Operation Mode (Requested) , select Read Write
在“ 操作模式(请求)”中 ,选择“ 读写”
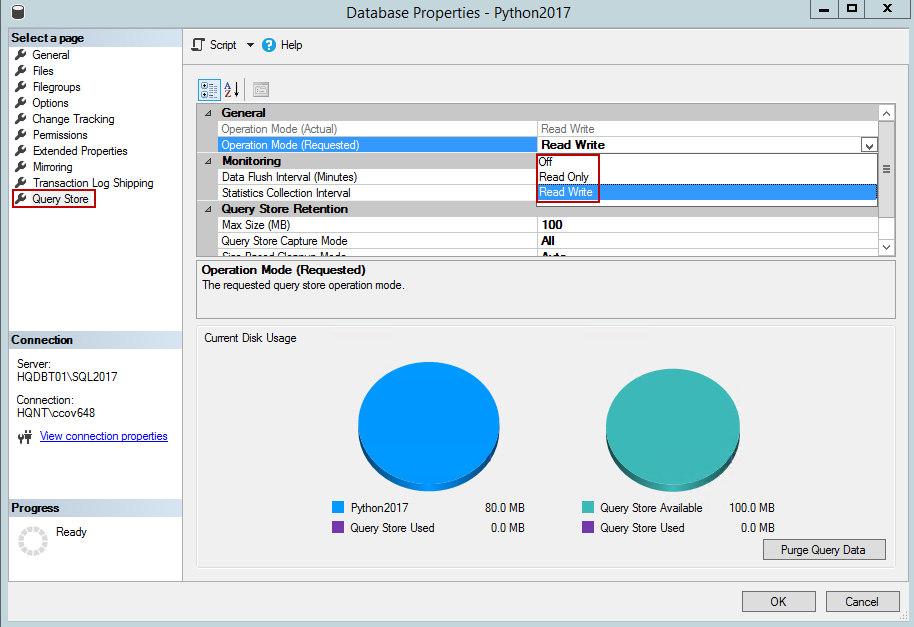
使用T-SQL启用查询存储 (Enable the Query Store using T-SQL)
Use the ALTER DATABASE to enable the query store.
使用ALTER DATABASE启用查询存储。
ALTER DATABASE CURRENT SET QUERY_STORE = ON;
示范 (Demonstration)
We’ll use the WideWorldImporters database for the demonstration.
我们将使用WideWorldImporters数据库进行演示。
- here 此处下载数据库
Clone the data to SalesOrderLines table from sales.OrderLines and Sales.Orders to SalesOrders table
将数据从sales.OrderLines和Sales.Orders克隆到SalesOrderLines表到SalesOrders表
SELECT * INTO SalesOrderLines from sales.OrderLines SELECT * INTO SalesOrders from sales.OrdersEnable and set the values to configure the Query Store
启用并设置值以配置查询存储
ALTER DATABASE CURRENT SET QUERY_STORE = ON; GO ALTER DATABASE CURRENT SET QUERY_STORE ( OPERATION_MODE = READ_WRITE, DATA_FLUSH_INTERVAL_SECONDS = 600, MAX_STORAGE_SIZE_MB = 500, INTERVAL_LENGTH_MINUTES = 30 ); GOClear the Procedure cache using the following T-SQL
使用以下T-SQL清除过程缓存
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE;Clear the Query Store using the following T-SQL
使用以下T-SQL清除查询存储
ALTER DATABASE CURRENT SET QUERY_STORE CLEAR ALL;Enable the Automatic Tuning option on the database
在数据库上启用“自动调整”选项
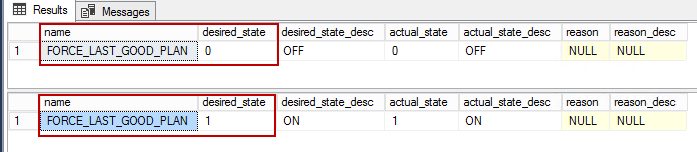
ALTER DATABASE CURRENT SET AUTOMATIC_TUNING (FORCE_LAST_GOOD_PLAN = ON ); GOVerify the database settings and options
验证数据库设置和选项
SELECT * FROM sys.database_automatic_tuning_options
Every parameter and every small change in a query impacts it in some way or the other. Conversely, the performance of a query does not change if there’s no change in the configuration or the underlying data. When a query is executed, SQL Server Engine chooses what it thinks is the best plan, when executing. If a plan was compiled and cached, it can be reused from cache. In some situations, even if a certain plan was not the most optimal, but performed better than the current plan on similar parameters, the SQL Server Engine would use the old plan. This is called a plan regression.
查询中的每个参数和每个小的更改都会以某种方式影响它。 相反,如果配置或基础数据没有变化,则查询的性能不会改变。 执行查询时,SQL Server Engine在执行时会选择它认为是最佳计划。 如果计划已编译并缓存,则可以从缓存中重复使用它。 在某些情况下,即使某个计划不是最佳计划,但在类似参数上的执行效果也要优于当前计划,但SQL Server Engine仍会使用旧计划。 这称为计划回归。
Identifying and forcing the query plan to perform optimally is very complex and tedious job, if it is done manually, but in SQL Server 2017, the Automatic Tuning feature does it efficiently.
如果手动确定查询计划并使其达到最佳状态,则这是非常复杂且繁琐的工作,但是在SQL Server 2017中,自动调整功能可以高效地做到这一点。
Let’s start the SQL workload by executing the following SQL 600-900 times
让我们通过执行以下SQL 600-900次来启动SQL工作负载
EXEC sp_executesql N'select sum([UnitPrice]*[Quantity])
from SalesOrderLines SL inner join salesorders SO on SL.OrderID=SO.OrderID
where PackageTypeID = @ptid', N'@ptid int',
@ptid = 7;
GO 600
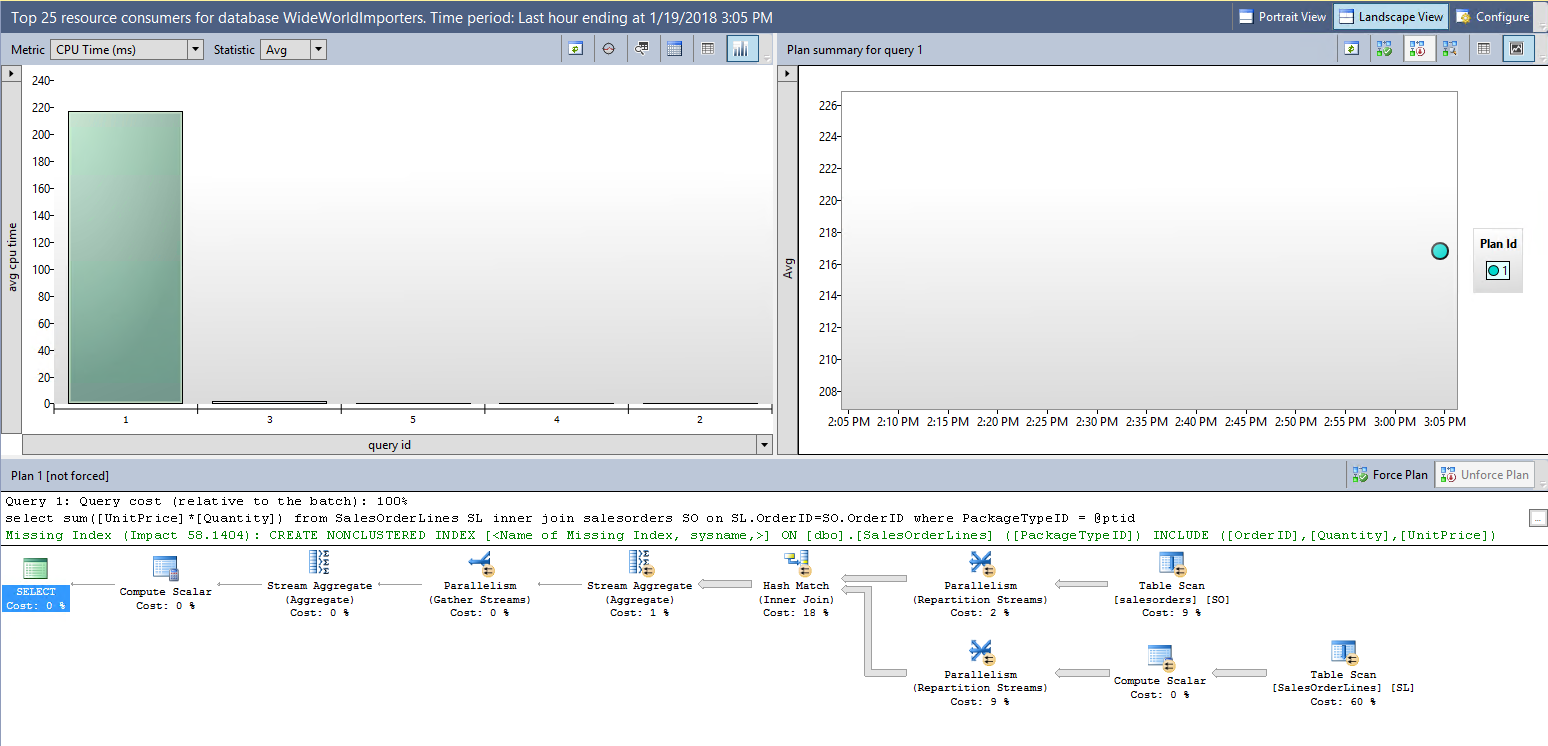
To view the Query Store performance dashboard, browse the database, explore the Query Store component and select the Top Resource Consuming Queries option
要查看查询存储性能仪表板,请浏览数据库,浏览查询存储组件,然后选择“ 最消耗资源的查询”选项
介绍回归 (Introduce regression)
In this case we clear the cache using ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE before I execute the query. SQL Server must recompile the query and generate the new query plan.
在这种情况下,我们在执行查询之前使用ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE清除缓存。 SQL Server必须重新编译查询并生成新的查询计划。
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE;
EXEC sp_executesql N'select sum([UnitPrice]*[Quantity])
from SalesOrderLines SL inner join salesorders SO on SL.OrderID=SO.OrderID
where PackageTypeID = @ptid', N'@ptid int',
@ptid = 0;
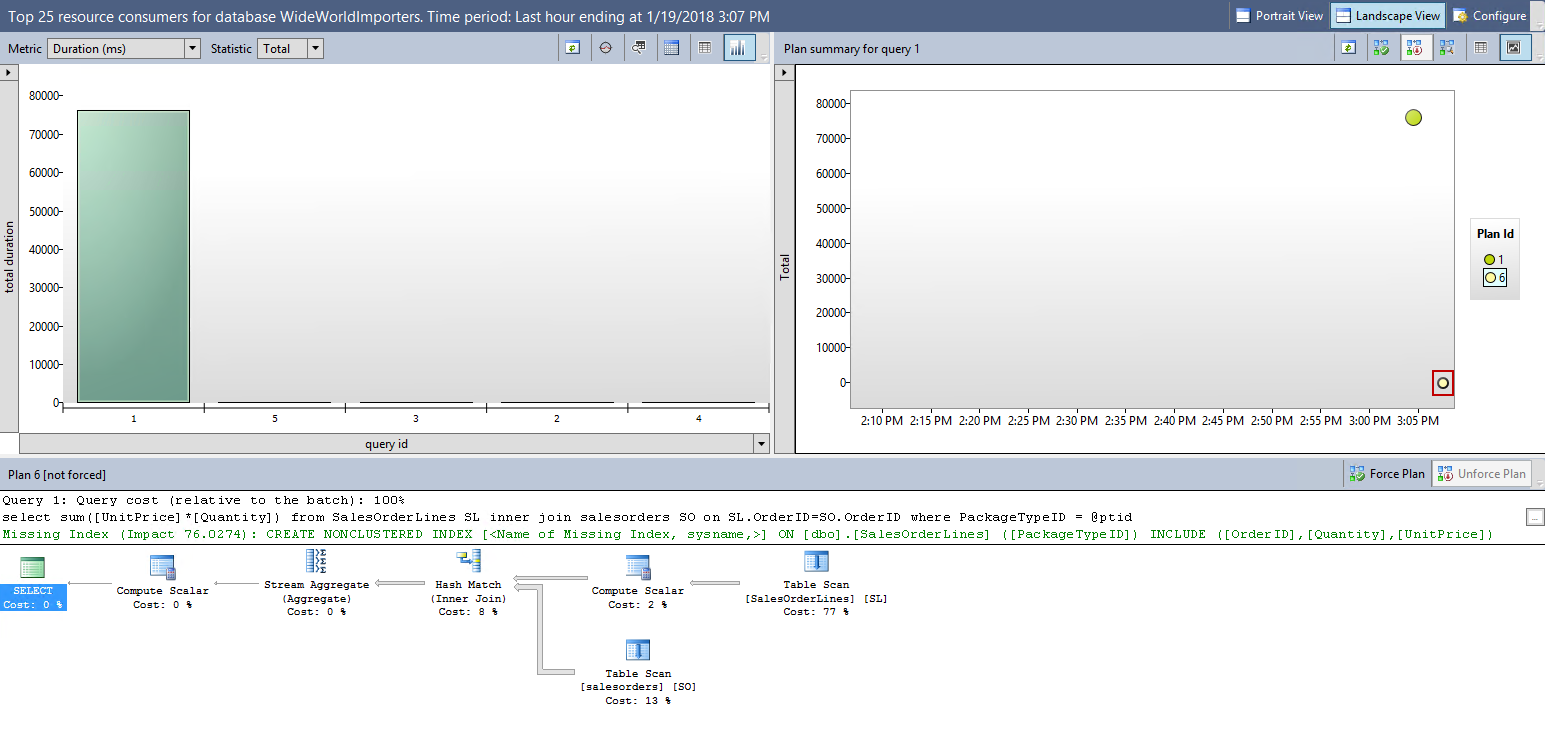
Start the SQL workload process
启动SQL工作负载过程
EXEC sp_executesql N'select sum([UnitPrice]*[Quantity])
from SalesOrderLines SL inner join salesorders SO on SL.OrderID=SO.OrderID
where PackageTypeID = @ptid', N'@ptid int', @ptid = 7;
go 20
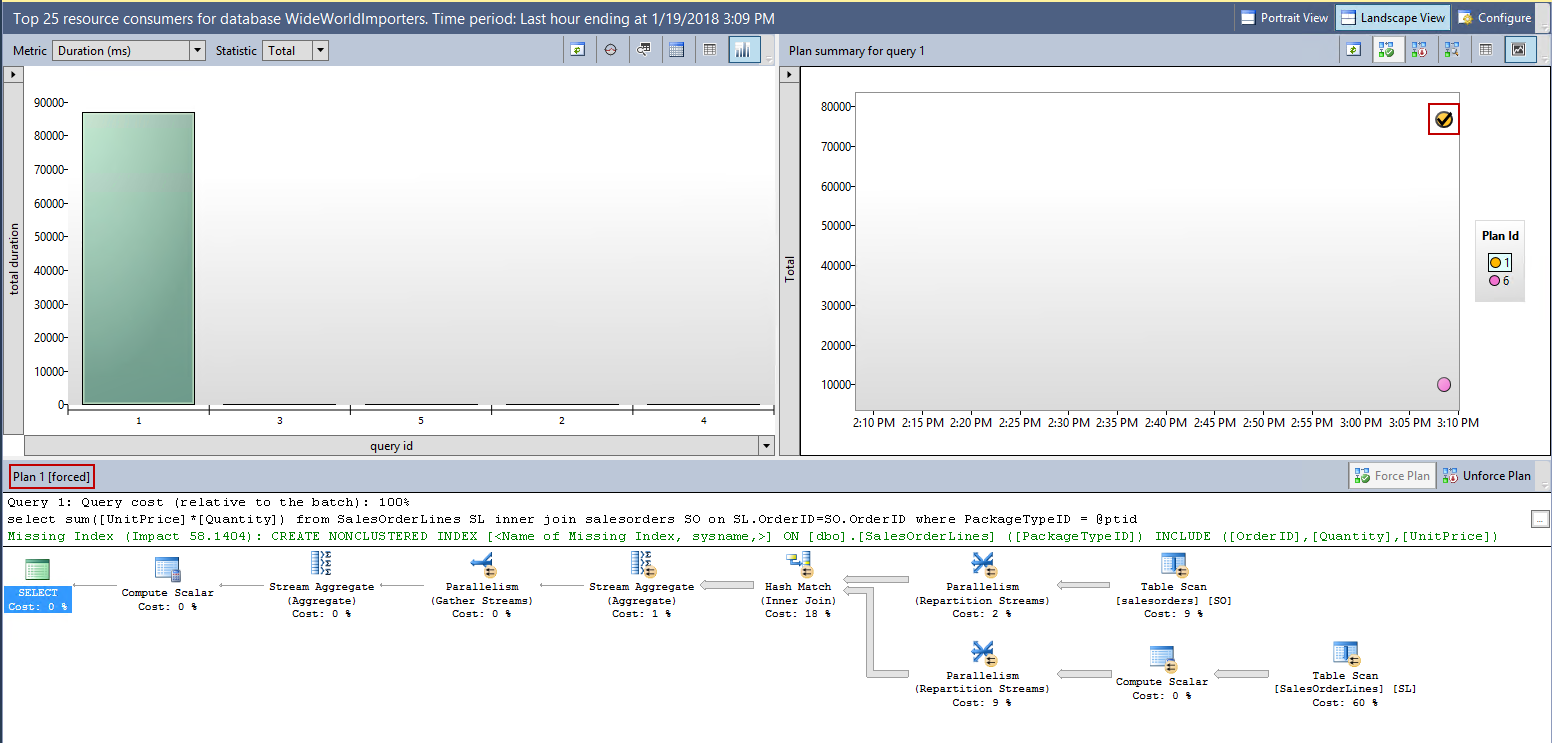
We can see in this case that that plan 1 is forced.
在这种情况下,我们可以看到该计划1是强制性的。
SQL Server 2017 provides a new system view, sys.dm_db_tuning_recommendations, which shows all the identified plan regressions.
SQL Server 2017提供了一个新的系统视图sys.dm_db_tuning_recommendations ,该视图显示了所有已识别的计划回归。
SELECT
reason,
score,
JSON_VALUE(state, '$.currentValue') state,
JSON_VALUE(state, '$.reason') state_transition_reason,
script = JSON_VALUE(details, '$.implementationDetails.script'),
[current plan_id],
[recommended plan_id],
is_revertable_action,
rever
estimated_gain = (regressedPlanExecutionCount+recommendedPlanExecutionCount)
*(regressedPlanCpuTimeAverage-recommendedPlanCpuTimeAverage)/1000000
FROM sys.dm_db_tuning_recommendations
CROSS APPLY OPENJSON (Details, '$.planForceDetails')
WITH ( [query_id] int '$.queryId',
[current plan_id] int '$.regressedPlanId',
[recommended plan_id] int '$.recommendedPlanId',
regressedPlanExecutionCount int,
regressedPlanCpuTimeAverage float,
recommendedPlanExecutionCount int,
recommendedPlanCpuTimeAverage float
) as planForceDetails;
;

The state column of the sys.dm_db_tuning_recommendations DMV indicates that the recommendation is applied and a validation is in progress, upon comparing the performance of the forced plan and regressed plan.
sys.dm_db_tuning_recommendations DMV的状态列指示在比较强制计划和回归计划的性能后,已应用建议并且正在进行验证。
Let’s create the missing indexes named NCI_SalesOrderLines_PTID on salesorderlines table. The schema of the salesorderline object is thus modified.
让我们在alesorderlines表上创建名为NCI_SalesOrderLines_PTID的缺失索引。 因此,对salesorderline对象的方案进行了修改。
CREATE NONCLUSTERED INDEX [NCI_SalesOrderLines_PTID]
ON [dbo].[SalesOrderLines] ([OrderID],[PackageTypeID])
INCLUDE ([Quantity],[UnitPrice])
Now, run the aforementioned SQL query to check the status
现在,运行上述SQL查询以检查状态

Expired in the state column indicates that the recommended plan has expired and is now invalid. The state column can have different values such as Active, Verifying, Success, Reverted and Expired.
“ 状态”列中的“ 过期 ”表示推荐的计划已过期,现在无效。 状态列可以具有不同的值,例如“活动”,“正在验证”,“成功”,“已还原”和“过期”。
Active | Active recommendation but yet to be applied. |
Verifying | In this state, the performance of forced plan v/s regressed plan is calculated. |
Success | The plan is successfully applied. |
Reverted | Unforce the plan since there is no significant performance improvement |
Expired | Recommendation is expired |
活性 | 积极推荐,但尚未应用。 |
验证中 | 在这种状态下,计算强制计划对回归计划的执行情况。 |
成功 | 该计划已成功应用。 |
已还原 | 取消计划,因为性能没有明显改善 |
已过期 | 推荐已过期 |
摘要 (Summary)
SQL Server 2017 introduces an automatic tuning feature, which is like a safety net for you workload. It prevents performance degradation of query plans. More information on the automatic tuning feature in SQL Server 2017 is available here.
SQL Server 2017引入了自动调整功能,就像您工作负载的安全网一样。 它可以防止查询计划的性能下降。 有关SQL Server 2017中自动调整功能的更多信息,请参见此处 。
The SQL Server Engine can compare and correct bad plan choices, which also happen to be one of the prime reasons to push for the upgrade/migration of SQL Server to SQL Server 2017. When the SQL Server Engine encounters a plan performance regression, the last good plan is forced upon, thereby improving performance. Also, if the forced plan does no good to the performance, the query is recompiled.
SQL Server Engine可以比较和纠正错误的计划选择,这也是促使SQL Server升级/迁移到SQL Server 2017的主要原因之一。当SQL Server Engine遇到计划性能下降时,最后一个强制执行良好的计划,从而提高性能。 另外,如果强制计划对性能不利,则将重新编译查询。
One point to keep in mind is to not clear the procedure cache on a production system because it will affect all queries! Also, since the data is not persisted in the DMV, the process of capturing the necessary information and transferring it to a permanent table for analysis and reporting should be carried out. However, this can be automated.
要记住的一点是,不要清除生产系统上的过程高速缓存,因为它将影响所有查询! 另外,由于数据未保留在DMV中,因此应执行捕获必要信息并将其传输到永久表以进行分析和报告的过程。 但是,这可以自动化。
目录 (Table of contents)
翻译自: https://www.sqlshack.com/understanding-automatic-tuning-in-sql-server-2017/


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









