



 Innopolis大学学生与Acronis合作开发ActiveRestore服务,通过理论与实践结合,成功完成项目。项目涉及实验设计、代码编写、系统架构等环节,最终成果显著。
Innopolis大学学生与Acronis合作开发ActiveRestore服务,通过理论与实践结合,成功完成项目。项目涉及实验设计、代码编写、系统架构等环节,最终成果显著。

Acronis started the development of the Active Restore in-house, but being Innopolis University students, we participated in this process as an academic and industrial project. Daulet Tumbayev, my supervisor (and now colleague), has already discussed the project idea and architecture in his post. Today my story is about how we prepared the service on the Innopolis side.
Acronis开始内部开发Active Restore,但作为Innopolis大学的学生,我们作为一个学术和工业项目参与了此过程。 我的主管(现在是同事)Daulet Tumbayev在其帖子中已经讨论了项目构想和体系结构。 今天,我的故事是关于我们如何在Innopolis方面准备服务的。
It all started in summer when we were informed that during our first term we would have a visit from IT companies: they were to offer us their ideas for practical work. In December 2018, we were presented with 15 various projects, and by the end of the month, we had the priorities sorted out and got an idea of what we liked best.
一切始于夏天,当时我们得知在第一学期我们将拜访IT公司:他们将为我们提供有关实际工作的想法。 在2018年12月,我们收到了15个不同的项目,到月底,我们已经对优先事项进行了梳理,并了解了我们最喜欢的项目。
All undergraduates filled out a form, where they had to choose four projects in which they wanted to participate. The choice had to be motivated: why me and why those projects. For example, I stated that I had experience in system programming and C/C++ development. Most importantly, the project allowed me to further develop my skills and to continue growing.
所有的本科生都填写了一份表格,在那里他们必须选择他们想参加的四个项目。 必须激励选择:为什么选择我,为什么选择这些项目。 例如,我说我有系统编程和C / C ++开发的经验。 最重要的是,该项目使我能够进一步发展自己的技能并继续发展。
Two weeks later, we got our assignments, and our work on the projects started in the beginning of the second term. The team was assembled. At our first meeting, we assessed each other's strengths and weaknesses, and defined roles.
两个星期后,我们得到了任务,我们在第二个学期开始时就开始了项目工作。 团队集结了。 在我们的第一次会议上,我们评估了彼此的优缺点,并确定了角色。
- Roman Rybkin, Python/C++ developer. Roman Rybkin,Python / C ++开发人员。
- Eugene Ishutin, Python/C++ developer responsible for the company contacts. Eugene Ishutin,负责公司联系人的Python / C ++开发人员。
- Anastasia Rodionova, Python/C++ developer responsible for writing documentation. Anastasia Rodionova,负责编写文档的Python / C ++开发人员。
- Brandon Acosta, environment setup, preparing the stand for experiments and testing. 布兰登·阿科斯塔(Brandon Acosta),环境设置,为试验和测试准备架子。
During the first two weeks, we had to launch the process. We established contacts with the customer, formalized the project requirements, launched the iterative process, and set up the working environment.
在最初的两个星期中,我们必须启动该过程。 我们与客户建立了联系,正式确定了项目要求,启动了迭代过程,并建立了工作环境。
By the way, our collaboration with the customer intensified when we started to take elective courses. The thing is, that Acronis experts are teaching a few elective courses at the Innopolis University (and others). Alexei Kostyushko, the leading developer of the Kernel team, is a regular lecturer on two courses: Reverse Engineering and Windows Kernel Architecture and Drivers. As far as I know,system programming and multithreaded computing courses are planned for the future. Most importantly, all of those courses are built to help the students carry out their industrial projects. They significantly enhance your understanding of the subject matter thus facilitating your work on the project.
顺便说一下,当我们开始选修课程时,我们与客户的合作就更加紧密。 事实是,Acronis的专家正在Innopolis大学(和其他机构)教授一些选修课程。 内核团队的领先开发人员Alexei Kostyushko是两门课程的定期讲师:反向工程和Windows内核体系结构和驱动程序。 据我所知,系统编程和多线程计算课程计划在将来进行。 最重要的是,所有这些课程都是为了帮助学生进行工业项目而设计的。 它们极大地增强了您对主题的理解,从而促进了您在项目上的工作。
That allowed us to start more «brightly» than other teams, and interaction with Acronis became stronger. Alexei Kostyushko was our Product Owner sharing with us the necessary expertise in the domain. His elective courses enhanced our hard skills significantly, and prepared us well to perform our task.
这使我们可以比其他团队更“明亮地”开始比赛,并且与Acronis的互动更加牢固。 Alexei Kostyushko是我们的产品负责人,与我们分享了该领域的必要专业知识。 他的选修课大大提高了我们的硬技能,为我们做好执行任务的准备。
从思考到项目 (From Reflections to the Project)
For all teams, the first month was the most challenging. Everyone was lost, and nobody knew what to start with. Should we write the documentation first or plunge straight into coding? Comments received from our University supervisors and mentors often contradicted those made by the company representatives.
对于所有团队来说,第一个月是最具挑战性的。 每个人都迷路了,没人知道从什么开始。 我们应该先编写文档还是直接投入编码? 我们大学主管和导师的评论经常与公司代表的评论相矛盾。
When things settled down (at least, in my head), it became clear that the University mentors helped us build relationships within the team and prepare documentation. However, the real breakthrough point was Daulet’s visit in March. We just sat down and spent our weekend working on the project. That was the moment when we reconceived the project, «hit the reset button», re-prioritized the tasks, and rushed forward. We understood what we needed to launch the experiment (discussed below) and to develop the service. Since then, our general understanding has transformed into a clear plan. We actually started coding, and in 2 weeks, we developed the first version of the test stand, which included virtual machines, necessary services, and the code for automating the experiment and collecting data.
当事情安定下来(至少在我的脑海中)时,很明显,大学的导师帮助我们在团队中建立了关系并准备了文件。 但是,真正的突破点是Daulet在三月的访问。 我们只是坐下来,度过了整个项目的周末时间。 那一刻,我们重新构思了该项目,“按下了重置按钮”,重新确定了任务的优先级,然后冲上前去。 我们了解了启动实验(如下所述)和开发服务所需要的。 从那时起,我们的一般理解已转变为明确的计划。 我们实际上开始编码,在两周内,我们开发了测试台的第一个版本,其中包括虚拟机,必要的服务以及用于自动化实验和收集数据的代码。
It should be noted that, along with working on our industrial project, we also attended the academic courses, which enabled us to build the right architecture for our projects and to organize Quality Management. At first, these activities had consumed 70 to 90% of our weekly time, but those time investments later proved to be necessary to avoid issues during development. The University’s goal was to teach us to properly organize the development process, while companies, as customers, were mostly interested in the result. This certainly added some commotion but helped us blend our theoretical knowledge with practical skills. We were motivated by the reasonably high complexity and workload, and that resulted in a successful project.
应当指出的是,除了从事我们的工业项目外,我们还参加了学术课程,这使我们能够为我们的项目构建正确的体系结构并组织质量管理。 最初,这些活动占用了我们每周70%至90%的时间,但后来证明这些时间对避免开发期间的问题是必要的。 该大学的目标是教我们如何正确组织开发过程,而公司(作为客户)对结果最感兴趣。 这无疑增加了一些动荡,但帮助我们将理论知识与实践技能融为一体。 我们受到相当高的复杂性和工作量的激励,从而导致了一个成功的项目。
Initially, two people in our team engaged in the development, one person was charged with the documentation, and another one plunged into the environment setup. However, later three other bachelors joined us, and we formed a well-knit team. The University decided to launch a trial industrial project for third-year students. Expanding the team from four to seven people significantly accelerated the process, as our bachelors could easily perform development-related tasks. Ekaterina Levchenko helped us with Python code and batch scripts for the test stand. Ansat Abirov and Ruslan Kim acted as developers; they selected and optimized algorithms.
最初,我们团队中有两个人从事开发工作,一个人负责文档,另一人负责环境设置。 但是,后来又有三个单身汉加入了我们,我们组成了一个组织精良的团队。 大学决定为三年级学生启动一个工业试验项目。 由于我们的单身汉可以轻松地执行与开发相关的任务,因此将团队从四人扩展到七人可以大大加快这一过程。 Ekaterina Levchenko帮助我们为测试台提供了Python代码和批处理脚本。 Ansat Abirov和Ruslan Kim担任开发人员; 他们选择并优化了算法。
We kept this format of working until the end of May when the experiment setup was completed. For the bachelors, that was the end of the industrial project. Two of them started their internships with Acronis and continued working with us. Therefore, after the end of May, we were working as a single team of six people.
我们一直保持这种工作方式,直到5月底完成实验设置为止。 对于单身汉来说,这就是工业项目的结束。 他们中的两个人开始了在Acronis的实习,并继续与我们合作。 因此,在5月底之后,我们作为一个由6个人组成的团队工作。
We had the third term ahead; at Innopolis, it is free from academic activities. We only had two elective courses, while the rest of our time was dedicated to the industrial project. It was during the third term that our work on the service intensified. The development process was established and ongoing and we regularly submitted demos and reports. We were working like that for 1.5 months and, by the end of July, the development part of our work was practically finished.
我们有第三个任期; 在Innopolis,它没有学术活动。 我们只有两门选修课,其余时间则用于工业项目。 在第三学期,我们在服务方面的工作得到加强。 开发过程已经建立并正在进行,我们定期提交演示和报告。 我们像这样工作了1.5个月,到7月底,我们工作的开发部分实际上已经完成。
技术细节 (Technical Details)
At the start, we defined the requirements to the service, which had to adequately liaise with the file system mini-filter driver (to learn what it is, read here) and thought through its architecture. Aiming to simplify further support of our code, we envisaged a module approach right from the start. Our service comprised several managers, agents and handlers, and even before the coding started, we had ensured the possibility of working simultaneously.
首先,我们定义了服务的需求,该需求必须与文件系统微型过滤器驱动程序充分联系(以了解其含义,请在此处阅读)并仔细考虑其体系结构。 为了简化对我们代码的进一步支持,我们从一开始就设想了一种模块方法。 我们的服务包括几个经理,代理和处理人员,甚至在编码开始之前,我们就确保了同时工作的可能性。
However, after we discussed the architecture at a meeting with Acronis people, it was decided to first carry out the experiment, and then turn to the service itself. As a result, the development only took 2.5 months. The rest of the time was dedicated to conducting the experiment in order to find the minimum set of files, which would be enough to run Windows. In a real system, this set of files is generated by the driver; however, we decided to find it heuristically using the bisection method, in order to test the driver's performance.
但是,在与Acronis员工开会时讨论了该体系结构之后,决定先进行实验,然后再转向服务本身。 结果,开发仅用了2.5个月。 剩下的时间专门用于进行实验,以便找到最少的文件集,足以运行Windows。 在实际系统中,这组文件是由驱动程序生成的。 但是,我们决定使用二等分法试探性地找到它,以测试驾驶员的性能。
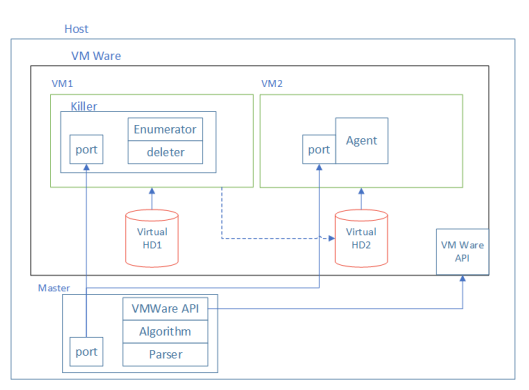
To achieve that, we assembled a stand scripted in Python, comprising two virtual machines. One of them ran Linux, while the other loaded Windows. Two disks were configured for them: Virtual HD1 and Virtual HD2. Both disks were linked to VM1, which ran Linux. On the HD1 of that VM, we installed a Killer application, which «damaged» HD2. «Damage» means deleting some files from the disk. HD2 was the boot disk for VM2 running Windows. Once the disk was «damaged», we tried to start VM2. If we managed to do that, it meant that the files deleted from the disk were not critical for booting.
为了实现这一目标,我们组装了一个用Python编写的脚本,包括两个虚拟机。 其中一个运行Linux,而另一个运行Windows。 为它们配置了两个磁盘:Virtual HD1和Virtual HD2。 两个磁盘都链接到运行Linux的VM1。 在该VM的HD1上,我们安装了一个“损坏” HD2的Killer应用程序。 «损坏»意味着从磁盘上删除一些文件。 HD2是运行Windows的VM2的启动磁盘。 磁盘“损坏”后,我们尝试启动VM2。 如果我们能够做到这一点,则意味着从磁盘上删除的文件对于启动而言并不重要。
In order to automate that process, we tried to use a preliminary elaborated approach, rather than deleting files randomly. The algorithm consisted of three steps:
为了使该过程自动化,我们尝试使用一种详细的初步方法,而不是随机删除文件。 该算法包括三个步骤:
- Split the file list in two halves. 将文件列表分成两半。
- Delete files in one of the two halves. 删除文件中的两个一半。
- Try to boot the system. If the system started, add the deleted files to the «unnecessary» list. Otherwise, go back to step 1. 尝试启动系统。 如果系统启动,则将已删除的文件添加到“不必要”列表中。 否则,请返回步骤1。
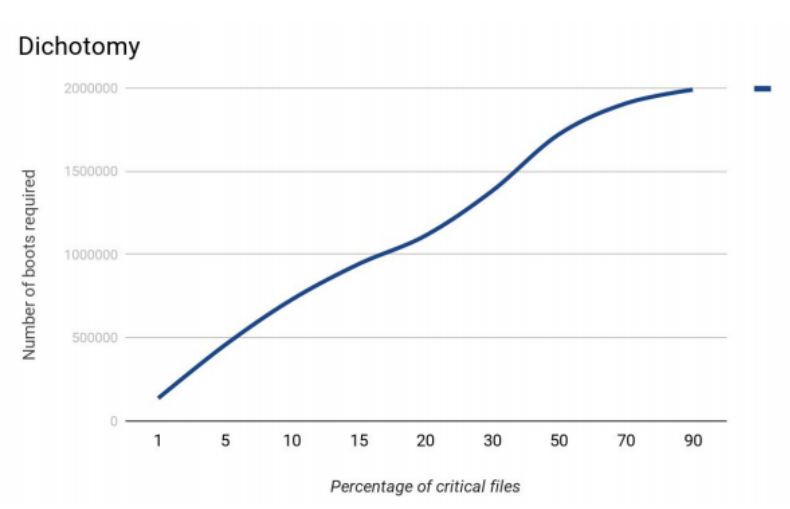
We decided to start with modeling the algorithm functioning. Suppose, there are 1,000,000 files in the file system. In this case, the search of critical files was the most efficient when the number of critical files was around 15% of the total.
我们决定从对算法功能进行建模开始。 假设文件系统中有1,000,000个文件。 在这种情况下,当关键文件的数量约为总数的15%时,搜索关键文件是最有效的。
At first, we had a great deal of problems with our experiment. In two to three weeks, the test stand was ready. Another one to 1.5 months were spent debugging, writing more code, and using various kinds of tricks to make the stand work.
首先,我们的实验存在很多问题。 在两到三周内,测试台已经准备就绪。 另外一到1.5个月的时间用于调试,编写更多的代码以及使用各种技巧来使标准工作。
The most challenging thing was to find a bug related to caсhing disk operations. The experiment was running for two days and produced quite optimistic results, which exceeded those of the simulations manifold. However, the test for critical files failed, the system did not start. It turned out that in case of a forced shutdown of the virtual machine, the delete operations cached by the file system were never executed. Consequently, the disk was not completely erased. That entailed the algorithm producing wrong results, and it took us a couple of days of intensive thinking to puzzle it out.
最具挑战性的事情是找到与缓存磁盘操作相关的错误。 实验进行了两天,产生了非常乐观的结果,超过了模拟流形的结果。 但是,对关键文件的测试失败,系统无法启动。 事实证明,在强制关闭虚拟机的情况下,从未执行过文件系统缓存的删除操作。 因此,磁盘没有完全擦除。 这导致算法产生错误的结果,并且我们花了几天的时间仔细思考才能解决它。
At a certain point, we noted that if the algorithm was running for a long time, it «dug» into one of the file system segments, trying to delete the same files (hoping for a new result). This happened when, having selected a bad interval for deletion, the algorithm was stuck in the areas where the majority of files were critical. At that moment, we decided to add the file list reshuffling, that is, the file list was rebuilt in a few iterations. This helped us to «pull» the algorithm out of such sticking.
在某个时候,我们注意到,如果算法运行了很长时间,它会“挖”入文件系统段之一,试图删除相同的文件(希望获得新结果)。 当选择了错误的删除间隔后,该算法卡在了大多数文件很关键的区域时,就会发生这种情况。 那时,我们决定添加文件列表改组,即文件列表是经过几次迭代重建的。 这帮助我们从这种“粘滞”中“抽出”算法。
When everything was ready, we set those two VMs to run for three days. There were about 600 iterations made, of which over 20 successful bootings. It became clear that the experiment might be launched to run for a long time and on more powerful machines, in order to find the optimal set of files to boot Windows. The work of the algorithm could also be distributed among several machines to further accelerate this process.
一切准备就绪后,我们将这两个VM设置为运行三天。 大约进行了600次迭代,其中有20多次成功启动。 很明显,该实验可以启动运行很长时间,并且可以在功能更强大的计算机上运行,以便找到启动Windows的最佳文件集。 该算法的工作也可以分布在几台机器之间,以进一步加速该过程。
In our case, apart from Windows, the disk only contained Python and our service. It took us three days to reduce the number of files from 70,000 to 50,000. The file list shrank by only 28%, but it became clear that our approach works and allows determining the minimal set of files necessary to boot the OS.
就我们而言,除Windows外,磁盘仅包含Python和我们的服务。 我们花了三天时间将文件数量从70,000减少到50,000。 文件列表仅减少了28%,但是很明显,我们的方法有效,并且可以确定引导操作系统所需的最少文件集。
服务结构 (The Service Structure)
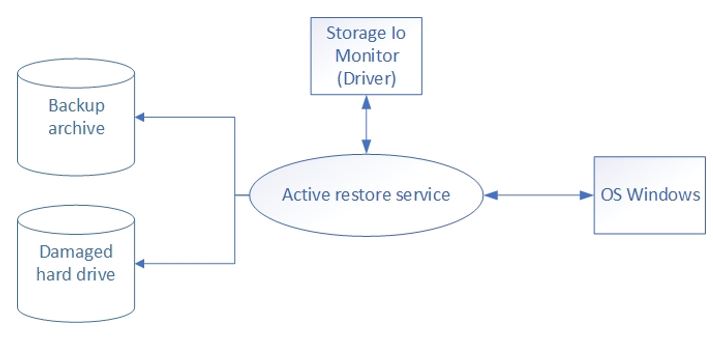
Let us have a look at the service structure. The main module of the service is the sequence manager. Since we receive the file list from the driver, we need to recover files following this list. Therefore, we created our prioritized sequence.
让我们看一下服务结构。 服务的主要模块是序列管理器。 由于我们从驱动程序收到文件列表,因此我们需要恢复此列表之后的文件。 因此,我们创建了优先顺序。
We have a list of files to recover one after another. In case of new access requests, urgently needed files will be prioritized for recovery. Therefore, the files that the user actually needs right now are placed in the head of the sequence, while those that will probably be needed in the future, are put in its end. However, if the user works intensively, it may lead to a «sequence of out-of-sequence objects», and a list of files being recovered right now. In addition, the search operation was to be applied to all those sequences at once. Unfortunately, we were unable to implement a sequence, which would set several priorities for the files, and at the same time support the search option and change priorities «on the go». We did not want to fit into the existing data frameworks; therefore, we had to create our own one, and set it up for working.
我们有一个文件列表,一个接一个地恢复。 如果有新的访问请求,将优先处理急需的文件以进行恢复。 因此,用户现在实际需要的文件放在序列的开头,而将来可能需要的文件放在其末尾。 但是,如果用户忙于工作,可能会导致“顺序不正确的对象”,并立即恢复文件列表。 此外,搜索操作将一次应用于所有这些序列。 不幸的是,我们无法实现一个序列,该序列将为文件设置多个优先级,同时支持搜索选项并“随时”更改优先级。 我们不想适应现有的数据框架。 因此,我们必须创建自己的一个,然后对其进行设置以进行工作。

Our service will first communicate with the driver elaborated by Daulet, and after that, with the components responsible for restoring the files. Therefore, we started with creating a small emulator of the recovery system, which would be able to retrieve files from a removable disk, in order to restore them and test the service.
我们的服务将首先与Daulet阐述的驱动程序进行通信,然后与负责还原文件的组件进行通信。 因此,我们首先创建了恢复系统的小型仿真器,该仿真器将能够从可移动磁盘中检索文件,以便还原它们并测试服务。
Two working modes were envisaged: the normal mode and the recovery mode. In the normal mode, the driver sends us a list of files affected at the OS launch. Then, as the system functions, the driver monitors all operations and files and sends notifications to our service. The service then makes changes to the list of files. In the recovery mode, the driver notifies the service of the necessity to restore the system. The service makes a sequence of files, launches software agents that request backup files, and starts the recovery process.
设想了两种工作模式:正常模式和恢复模式。 在正常模式下,驱动程序会向我们发送在操作系统启动时受影响的文件列表。 然后,随着系统运行,驱动程序将监视所有操作和文件,并向我们的服务发送通知。 然后,该服务对文件列表进行更改。 在恢复模式下,驱动程序会通知服务恢复系统的必要性。 该服务生成一系列文件,启动请求备份文件的软件代理,并开始恢复过程。
期末论文,工作机会和新项目 (Final Thesis, Job Offer and New Projects)
Once the service was ready and tested, we were left with one last project-related activity. We needed to update and streamline all artefacts that we had accumulated, and to present our results to the customer and to the University. For the company, it was another step towards the implementation of the project, while for the University, it was our final thesis.
服务准备就绪并经过测试后,我们将进行与项目有关的最后一项活动。 我们需要更新和简化我们积累的所有人工制品,并将结果呈现给客户和大学。 对于公司来说,这是实施该项目的又一步,而对于大学来说,这是我们的最终论文。
Based on the presentation results, the students received job offers. In a few weeks, I will start my career with Acronis. The project results brought the idea that the service performance could be enhanced by lowering it to the Native Windows Application level. That will be discussed in our next article.
根据演示结果,学生获得了工作机会。 几周后,我将开始Acronis的职业生涯。 该项目的结果提出了可以通过将服务性能降低到本机Windows应用程序级别来增强其性能的想法。 这将在我们的下一篇文章中讨论。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









