



 本文深入探讨了栈和寄存器的工作原理,详细解释了在编程中如何使用它们来存储和处理数据。文章通过具体的汇编语言代码示例,讲解了函数调用过程中的参数传递方式,包括寄存器和栈的使用。此外,还讨论了如何通过特定的技巧读取调用方法的栈,提供了一个虽然不能在实际项目中应用,但有助于理解工作原理的示例。
本文深入探讨了栈和寄存器的工作原理,详细解释了在编程中如何使用它们来存储和处理数据。文章通过具体的汇编语言代码示例,讲解了函数调用过程中的参数传递方式,包括寄存器和栈的使用。此外,还讨论了如何通过特定的技巧读取调用方法的栈,提供了一个虽然不能在实际项目中应用,但有助于理解工作原理的示例。
幕后产品
免责声明 (Disclaimer)
Before proceeding with the story, I strongly recommend you to read the first post about StructLayout, there is an example that will be used in this article.
在继续讲故事之前,我强烈建议您阅读有关StructLayout的第一篇文章,本文中将使用一个示例。
All code behind the high-level one is presented for the
高级别代码背后的所有代码均针对
调试 (debug)
mode, because it shows the conceptual basis. JIT optimization is a separate big topic that will not be covered here.
模式,因为它显示了概念基础。 JIT优化是一个单独的大主题,这里将不涉及。
I would also like to warn that this article does not contain material that should be used in real projects.
我也要警告,本文不包含在实际项目中应使用的材料。
第一-理论 (First — theory)
Any code eventually becomes a set of machine commands. Most understandable is their representation in the form of Assembly language instructions that directly correspond to one (or several) machine instructions.
任何代码最终都会变成一组机器命令。 最容易理解的是它们以直接对应于一个(或多个)机器指令的汇编语言指令的形式表示。

Before turning to a simple example, I propose to get acquainted with stack.
在举一个简单的例子之前,我建议先熟悉一下堆栈。
叠放 (Stack)
is primarily a chunk of memory that is used, as a rule, to store various kinds of data (usually they can be called
通常是一块内存,通常用于存储各种数据(通常可以将它们称为
temporal data). It is also worth remembering that the stack grows towards smaller addresses. That is the later an object is placed on the stack, the less address it will have. 时间数据 )。 还值得记住的是,堆栈向着较小的地址增长。 也就是说,将对象放置在堆栈上的时间越晚,其拥有的地址就越少。Now let's take a look on the next piece of code in Assembly language (I’ve omitted some of the calls that are inherent in the debug mode).
现在,让我们看一下汇编语言的下一段代码(我省略了调试模式中固有的一些调用)。
C#:
C#:
public class StubClass
{
public static int StubMethod(int fromEcx, int fromEdx, int fromStack)
{
int local = 5;
return local + fromEcx + fromEdx + fromStack;
}
public static void CallingMethod()
{
int local1 = 7, local2 = 8, local3 = 9;
int result = StubMethod(local1, local2, local3);
}
}Asm:
ASM:
StubClass.StubMethod(Int32, Int32, Int32)
1: push ebp
2: mov ebp, esp
3: sub esp, 0x10
4: mov [ebp-0x4], ecx
5: mov [ebp-0x8], edx
6: xor edx, edx
7: mov [ebp-0xc], edx
8: xor edx, edx
9: mov [ebp-0x10], edx
10: nop
11: mov dword [ebp-0xc], 0x5
12: mov eax, [ebp-0xc]
13: add eax, [ebp-0x4]
14: add eax, [ebp-0x8]
15: add eax, [ebp+0x8]
16: mov [ebp-0x10], eax
17: mov eax, [ebp-0x10]
18: mov esp, ebp
19: pop ebp
20: ret 0x4
StubClass.CallingMethod()
1: push ebp
2: mov ebp, esp
3: sub esp, 0x14
4: xor eax, eax
5: mov [ebp-0x14], eax
6: xor edx, edx
7: mov [ebp-0xc], edx
8: xor edx, edx
9: mov [ebp-0x8], edx
10: xor edx, edx
11: mov [ebp-0x4], edx
12: xor edx, edx
13: mov [ebp-0x10], edx
14: nop
15: mov dword [ebp-0x4], 0x7
16: mov dword [ebp-0x8], 0x8
17: mov dword [ebp-0xc], 0x9
18: push dword [ebp-0xc]
19: mov ecx, [ebp-0x4]
20: mov edx, [ebp-0x8]
21: call StubClass.StubMethod(Int32, Int32, Int32)
22: mov [ebp-0x14], eax
23: mov eax, [ebp-0x14]
24: mov [ebp-0x10], eax
25: nop
26: mov esp, ebp
27: pop ebp
28: retThe first thing to notice is the
首先要注意的是
电子血压计 (EBP)
and the
和
静电除尘器 (ESP)
registers and operations with them.
向他们注册和操作。
A misconception that the
一个误解是
电子血压计 (EBP)
register is somehow related to the pointer to the top of the stack is common among my friends. I must say that it is not.
在某种程度上,寄存器与指向栈顶的指针相关,这在我的朋友中很常见。 我必须说不是。
The
的
静电除尘器 (ESP)
register is responsible for pointing to the top of the stack. Correspondingly, with each
寄存器负责指向栈顶。 相应地,每个
推 (PUSH)
instruction (putting a value on the top of the stack) the value of
指令(将值放在栈顶)的值
静电除尘器 (ESP)
register is decremented (the stack grows towards smaller addresses), and with each
寄存器递减(堆栈朝着较小的地址增长),并且每个寄存器
流行音乐 (POP)
instruction it is incremented. Also, the
指令增加。 另外,
呼叫 (CALL)
command pushes the return address on the stack, thereby decrements the value of the
命令将返回地址压入堆栈,从而减小
静电除尘器 (ESP)
register. In fact, the change of the
寄存器。 其实,改变
静电除尘器 (ESP)
register is performed not only when these instructions are executed (for example, when interrupt calls are made, the same thing happens with the
不仅在执行这些指令时执行寄存器(例如,在进行中断调用时,
呼叫 (CALL)
instructions).
说明)。
Will consider StubMethod().
将考虑StubMethod() 。
In the first line, the content of the
在第一行中,
电子血压计 (EBP)
register is saved (it is put on a stack). Before returning from a function, this value will be restored.
寄存器被保存(放在堆栈中)。 从函数返回之前,将恢复该值。
The second line stores the current value of the address of the top of the stack (the value of the register
第二行存储栈顶地址的当前值(寄存器的值)
静电除尘器 (ESP)
is moved to
移至
电子血压计 (EBP)
). Next, we move the top of the stack to as many positions as we need to store local variables and parameters (third row). Something like memory allocation for all local needs —
)。 接下来,我们将堆栈的顶部移动到需要存储本地变量和参数的位置(第三行)。 满足所有本地需求的内存分配之类的东西-
堆栈框架 (stack frame)
. At the same time, the
。 同时,
电子血压计 (EBP)
register is a starting point in the context of the current call. Addressing is based on this value.
注册是当前调用上下文中的起点。 寻址基于此值。
All of the above is called
以上全部称为
功能序言 (the function prologue)
.
。
After that, variables on the stack are accessed via the stored
之后,通过存储的访问堆栈上的变量
电子血压计 (EBP)
register, which points on the place where the variables of this method begin. Next comes the initialization of local variables.
寄存器,它指向此方法的变量开始的位置。 接下来是局部变量的初始化。
Fastcall reminder: in .net, the FASTCALL提醒:在.NET中,使用 fastcall calling convention is used. 快速调用调用约定。The calling convention governs the location and the order of the parameters passed to the function.
调用约定控制传递给函数的参数的位置和顺序。
The first and second parameters are passed via the
第一个和第二个参数通过
ECX (ECX)
and
和
EDX (EDX )
registers, respectively, the subsequent parameters are transmitted via the stack. (This is for 32-bit systems, as always. In 64-bit systems four parameters passed through registers(
寄存器,随后的参数分别通过堆栈传输。 (与往常一样,这适用于32位系统。在64位系统中,四个参数通过寄存器传递(
RCX (RCX)
,
,
RDX (RDX)
,
,
R8 (R8)
,
,
R9 (R9)
))
))
For non-static methods, the first parameter is implicit and contains the address of the instance on which the method is called (this address).
对于非静态方法,第一个参数是隐式的,并且包含在其上调用该方法的实例的地址(此地址)。
In lines 4 and 5, the parameters that were passed through the registers (the first 2) are stored on the stack.
在第4和第5行中,通过寄存器(前两个)传递的参数存储在堆栈中。
Next is cleaning the space on the stack for local variables (stack frame) and initializing local variables.
接下来是清理堆栈上用于局部变量的空间( 堆栈框架 )并初始化局部变量。
It is worth be mentioned that the result of the function is in the register
值得一提的是,函数的结果在寄存器中
EAX (EAX)
.
。
In lines 12-16, the addition of the desired variables occurs. I draw your attention to line 15. There is a accessing value by the address that is greater than the beginning of the stack, that is, to the stack of the previous method. Before calling, the caller pushes a parameter to the top of the stack. Here we read it. The result of the addition is obtained from the register
在第12-16行中,发生了所需变量的添加。 我提请您注意第15行。该地址有一个访问值,该值大于堆栈的开头,即前一个方法的堆栈。 在调用之前,调用者将参数压入堆栈的顶部。 在这里,我们阅读它。 从寄存器中获得相加的结果
EAX (EAX)
and placed on the stack. Since this is the return value of the
并放在堆栈上。 由于这是
StubMethod(), it is placed again in StubMethod() ,将其再次放置在EAX (EAX)
. Of course, such absurd instruction sets are inherent only in the debug mode, but they show exactly how our code looks like without smart optimizer that does the lion’s share of the work.
。 当然,这种荒谬的指令集仅在调试模式下才是固有的,但是它们准确地显示了没有智能优化器来完成大部分工作的代码的样子。
In lines 18 and 19, both the previous
在第18和19行中,前一个
电子血压计 (EBP)
(calling method) and the pointer to the top of the stack are restored (at the time the method is called). The last line is the returning from function. About the value 0x4 I will tell a bit later.
(调用方法)和指向堆栈顶部的指针(在调用该方法时)。 最后一行是从函数返回。 关于值0x4,我稍后再讲。
Such a sequence of commands is called a function epilogue.
这样的命令序列称为功能结尾。
Now let's take a look at CallingMethod(). Let's go straight to line 18. Here we put the third parameter on the top of the stack. Please note that we do this using the
现在让我们看一下CallingMethod() 。 让我们直接转到第18行。在这里,我们将第三个参数放在堆栈的顶部。 请注意,我们使用
推 (PUSH)
instruction, that is, the
指令,即
静电除尘器 (ESP)
value is decremented. The other 2 parameters are put into registers (
值递减。 其他2个参数被放入寄存器(
fastcall). Next comes the fastcall )。 接下来是 StubMethod() method call. Now let's remember the StubMethod()方法调用。 现在,让我们记住RET 0x4 (RET 0x4)
instruction. Here the following question is possible: what is 0x4? As I mentioned above, we have pushed the parameters of the called function onto the stack. But now we do not need them. 0x4 indicates how many bytes need to be cleared from the stack after the function call. Since the parameter was one, you need to clear 4 bytes.
指令。 这里可能出现以下问题:0x4是什么? 如前所述,我们已经将被调用函数的参数压入堆栈。 但是现在我们不需要它们了。 0x4表示函数调用后需要从堆栈中清除多少字节。 由于该参数为1,因此需要清除4个字节。
Here is a rough image of the stack:
这是堆栈的大致图像:
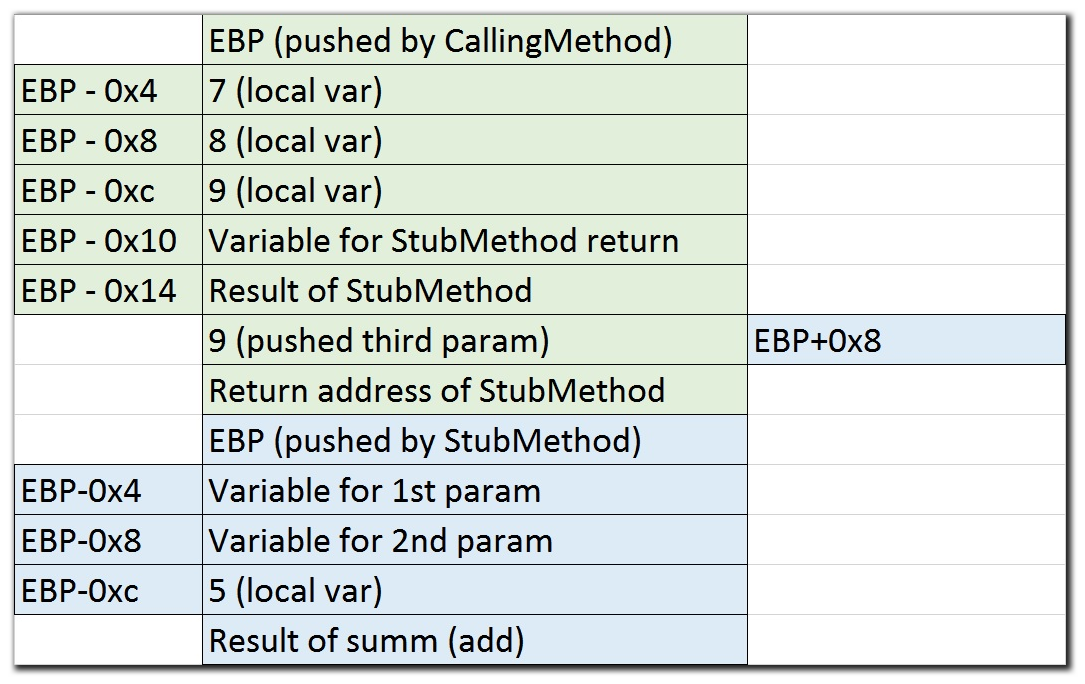
Thus, if we turn around and see what lies on the stack right after the method call, the first thing we will see
因此,如果我们转过头来看看在方法调用之后堆栈中的内容,我们将看到的第一件事
电子血压计 (EBP)
, that was pushed onto the stack (in fact, this happened in the first line of the current method). The next thing will be the return address. It determines the place, there to resume the execution after our function is finished (used by
,将其压入堆栈(实际上,这发生在当前方法的第一行)。 接下来是寄信人地址。 它确定位置,在我们的函数完成后,从那里继续执行(由
RET (RET)
). And right after these fields we will see the parameters of the current function (starting from the 3rd, first two parameters are passed through registers). And behind them the stack of the calling method hides!
)。 在这些字段之后,我们将看到当前函数的参数(从第3个开始,前两个参数通过寄存器传递)。 在它们后面隐藏着调用方法的堆栈!
The first and second fields mentioned before (
前面提到的第一个和第二个字段(
电子血压计 (EBP)
and return address) explain the offset in +0x8 when we access parameters.
和返回地址)说明我们访问参数时+ 0x8的偏移量。
Correspondingly, the parameters must be at the top of the stack in a strictly defined order before function call. Therefore, before calling the method, each parameter is pushed onto the stack.
相应地,在调用函数之前,参数必须以严格定义的顺序位于堆栈的顶部。 因此,在调用该方法之前,每个参数都被压入堆栈。
But what if they do not push, and the function will still take them?
但是,如果它们不推动,该函数仍会接住它们怎么办?
小例子 (Small example)
So, all the above facts have caused me an overwhelming desire to read the stack of the method that will call my method. The idea that I am only in one position from the third argument (it will be closest to the stack of the calling method) is the cherished data that I want to receive so much, did not let me sleep.
因此,以上所有事实都使我强烈希望读取将调用我的方法的方法堆栈。 我只在第三个参数中处于一个位置(它将最接近调用方法的堆栈)的想法是我想要收到的如此珍贵的数据,却让我无法入睡。
Thus, to read the stack of the calling method, I need to climb a little further than the parameters.
因此,要读取调用方法的堆栈,我需要比参数更进一步。
When referring to parameters, the calculation of the address of a particular parameter is based only on the fact that the caller has pushed them all onto the stack.
当引用参数时,特定参数地址的计算仅基于调用者已将它们全部压入堆栈的事实。
But implicit passing through the
但是隐式地通过
EDX (EDX)
parameter (who is interested —
参数(谁感兴趣-
previous article) makes me think that we can outsmart the compiler in some cases. 上一篇文章 )使我认为在某些情况下我们可以超越编译器。The tool I used to do this is called StructLayoutAttribute (al features are in the first article). //One day I will learn a bit more than only this attribute, I promise
我用来执行此操作的工具称为StructLayoutAttribute(其他功能在第一篇文章中 )。 //有一天,我保证我会学到的不仅仅是这个属性
We use the same favorite method with overlapped reference types.
我们对重叠的引用类型使用相同的收藏夹方法。
At the same time, if overlapping methods have a different number of parameters, the compiler does not push the required ones onto the stack (at least because it does not know which ones).
同时,如果重叠的方法具有不同数量的参数,则编译器不会将所需的参数压入堆栈(至少是因为它不知道哪些参数)。
However, the method that is actually called (with the same offset from a different type), turns into positive addresses relative to its stack, that is, those where it plans to find the parameters.
但是,实际上被调用的方法(与另一种类型具有相同的偏移量)相对于其堆栈(即计划查找参数的地址)变为正地址。
But nobody passes parameters and method begins to read the stack of the calling method. And the address of the object(with Id property, that is used in the WriteLine()) is in the place, where the third parameter is expected.
但是没有人传递参数,方法开始读取调用方法的堆栈。 对象的地址(具有Id属性,在WriteLine()中使用 )位于期望第三个参数的位置。
代码在剧透中 (Code is in the spoiler)
using System;
using System.Runtime.InteropServices;
namespace Magic
{
public class StubClass
{
public StubClass(int id)
{
Id = id;
}
public int Id;
}
[StructLayout(LayoutKind.Explicit)]
public class CustomStructWithLayout
{
[FieldOffset(0)]
public Test1 Test1;
[FieldOffset(0)]
public Test2 Test2;
}
public class Test1
{
public virtual void Useless(int skipFastcall1, int skipFastcall2, StubClass adressOnStack)
{
adressOnStack.Id = 189;
}
}
public class Test2
{
public virtual int Useless()
{
return 888;
}
}
class Program
{
static void Main()
{
Test2 objectWithLayout = new CustomStructWithLayout
{
Test2 = new Test2(),
Test1 = new Test1()
}.Test2;
StubClass adressOnStack = new StubClass(3);
objectWithLayout.Useless();
Console.WriteLine($"MAGIC - {adressOnStack.Id}"); // MAGIC - 189
}
}
}I will not give the assembly language code, everything is pretty clear there, but if there are any questions, I will try to answer them in the comments
我不会提供汇编语言代码,那里的所有内容都非常清楚,但是如果有任何问题,我将尝试在注释中回答。
I understand perfectly that this example cannot be used in practice, but in my opinion, it can be very useful for understanding the general scheme of work.
我完全理解此示例不能在实践中使用,但是我认为,它对于理解总体工作方案可能非常有用。
幕后产品

















 3936
3936

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









