



在github上下载了JSFinder,完成了第一次使用,中间遇到了一些曲折,希望写下来,供大家参考。
首先是下载,在github.com/Threezh1/JSFinder上下载
解压后得到两个文件

我们使用的是其中的python文件,所以我们要安装python环境,在官网下载相应版本即可。
安装好python后,在JSFinder.py目录下运行cmd,然后输入python JSFinder.py -u http网址,即可得到该网址在JavaScript中使用的子域名。以jd.com为例,如下。
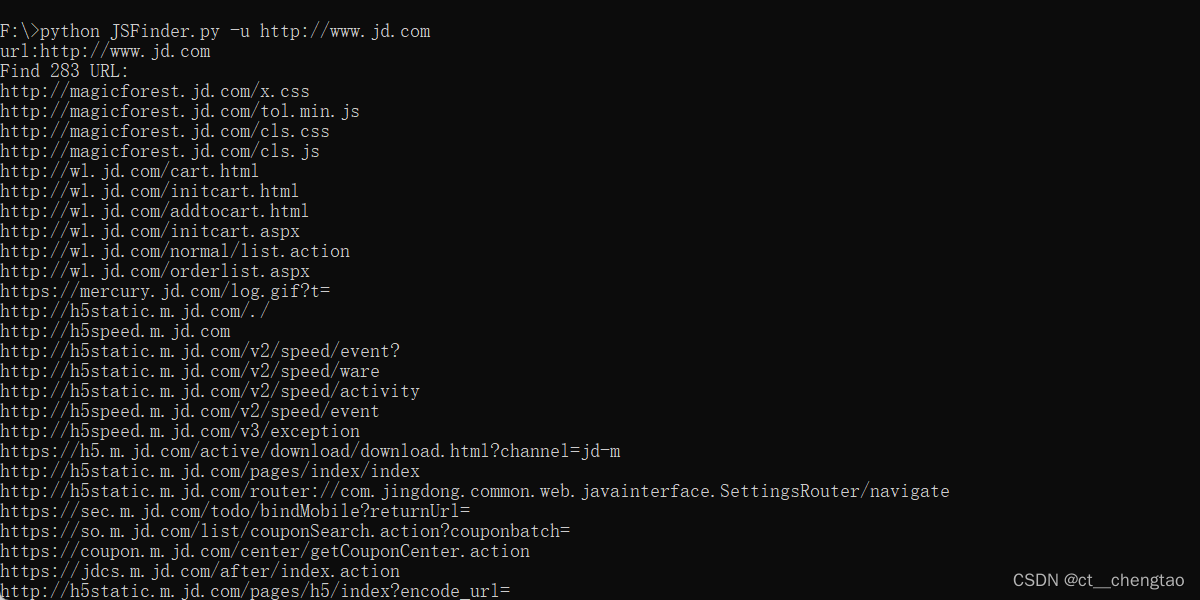
新安装的python可能会报一些错,那是因为JSFinder.py用到的一些模块新安装的python里没有,在cmd中使用pip命令安装即可,例如缺少‘bs4’模块,会报错ModuleNotFoundError: No module named 'bs4',只需要在cmd中运行pip install bs4即可,安装时间不超过十秒。

















 1528
1528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









