



缘起
在研究 RAG 技术时,遇到几个 PDF 文件。没多想就直接把它们丢给程序处理,结果发现什么都读不出来。打开 PDF 查看时,发现文件里有图片和文字,但点击图片正常显示,文字却无法选中。这很奇怪 - 要么是图片,要么是文字,但都不太符合:图片点击后会变暗显示边框,而这些文字点击后完全没反应。
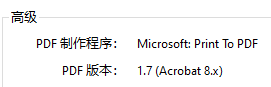
开始怀疑是加密文件,检查后确认没有加密。后来在文档属性的"高级"选项中发现了端倪:【PDF 制作程序:Microsoft: Print To PDF】。这才明白,这些 PDF 是通过虚拟打印机从网页生成的,网页文字被转换成了矢量图形。

解决方案
知道原由那就简单了,用 OCR 识别就行,大致是先把 PDF 里每一页临时保存为图片,然后再用 OCR 识别出文字。如果是 Python 的话,就是 pdf2image + pytesseract。
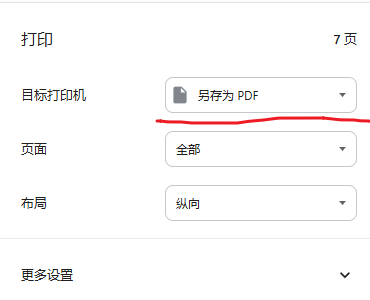
另外,如果你自己可以控制 PDF 文件的生成,如果还是要把网页保存为 PDF,且还是要使用虚拟打印机,那么,在【目标打印机】的位置选择【另存为 PDF】就好了,何苦难为自己。

















 1417
1417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









