




目录
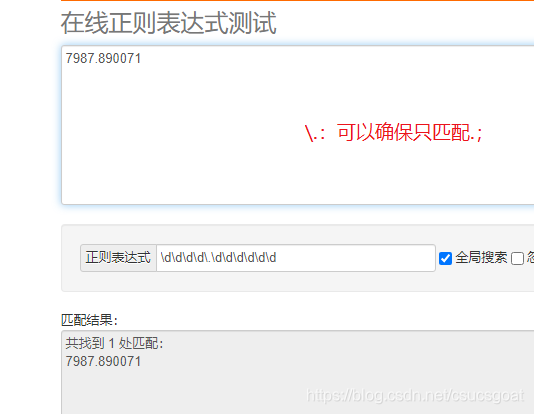
示例1:匹配:四位整数六位小数的一个数字,如3467.798789:
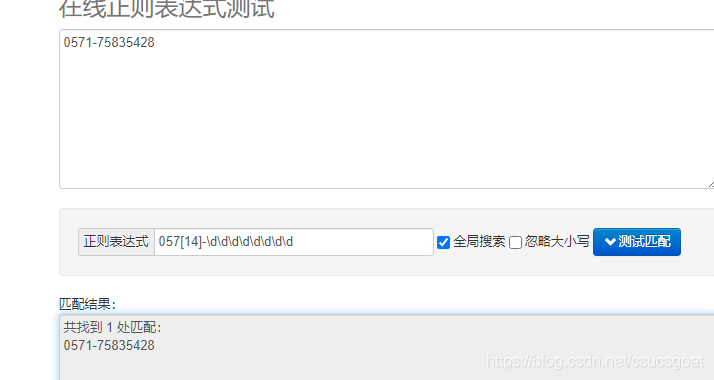
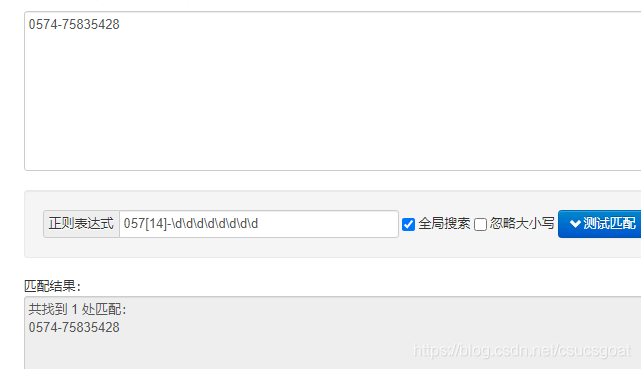
示例2:匹配杭州与宁波的座机号码(0571|0574-XXXXXXXX):
示例3:匹配十八位身份证号:省份证号的规则是前面有17位数字,最后一个可能是数字也可能是X或x
一:元字符
好好理解下元的含义!元可以看成是一种指代,是后续基础的支撑性的东西!
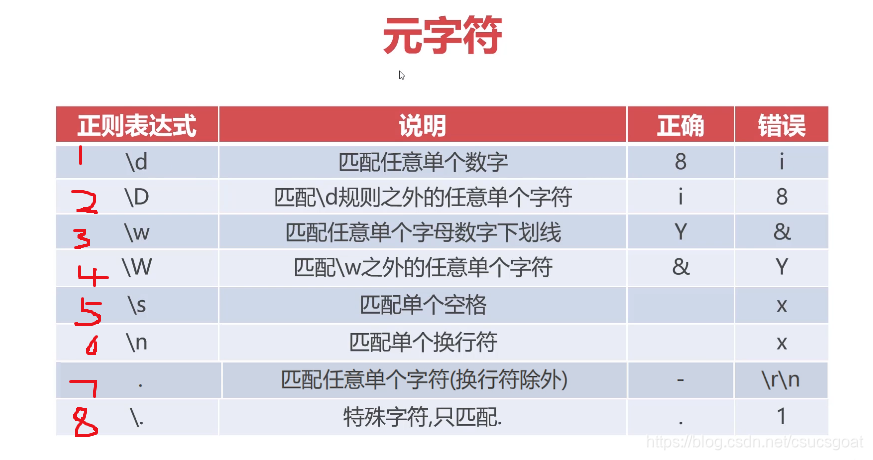
下面的几个例子,正则表达式的匹配条件都是字符串,只是这个字符串的某些字符可能是没有定死的而已,而是使用了元字符去指代;;;自然,如果正则表达式的匹配条件是字符串的话,其匹配结果也会是字符串!这种字符串形式的正则表达式应该是以后最常使用的形式。。。
示例1:匹配:四位整数六位小数的一个数字,如3467.798789:
示例2:匹配杭州与宁波的座机号码(0571|0574-XXXXXXXX):
示例3:匹配十八位身份证号:省份证号的规则是前面有17位数字,最后一个可能是数字也可能是X或x
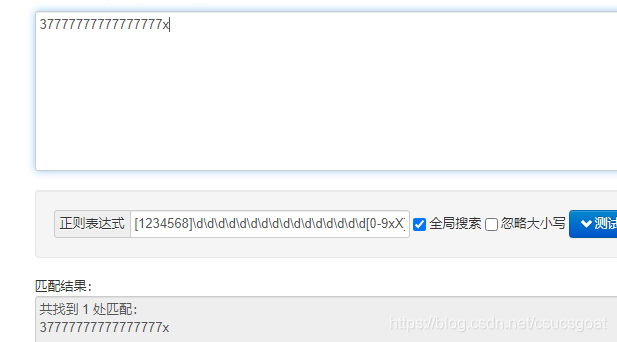
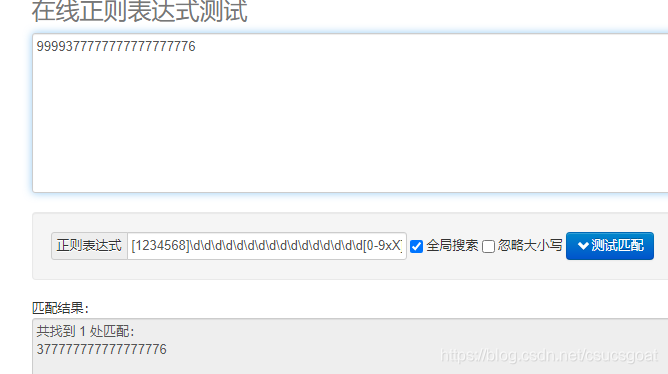
身份证号的第一位的范围是1234568这几个数字:
可以采用的正则表达式可以是:[1234568]\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d[0-9xX]
二:多次重复匹配
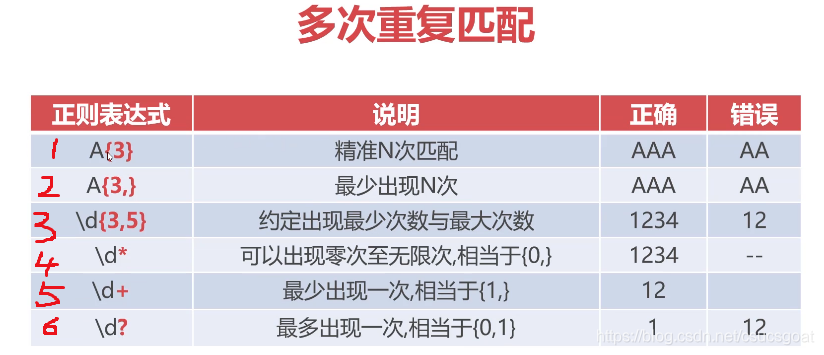
{},*,+,?是一个多次重复匹配修饰符,跟在其他字符后面,用来和其他字符组合使用……
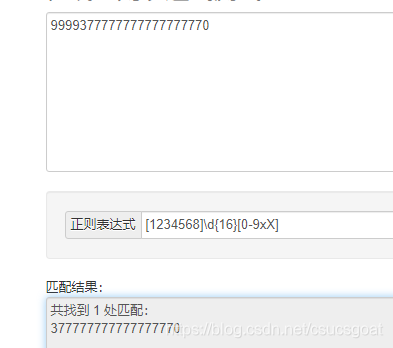
同样是上面身份证号的匹配:[1234568]\d{16}[0-9xX]。同样可以达到效果
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









