




利用Dom4j读取XML文档:
XML文档:
<?xml version="1.0" encoding="UTF-8"?>
<!-- 人力资源管理系统-->
<!--xmlns:xsi的意思是告诉XML文档,我们的约束是使用Schema;xsi:noNamespaceSchemaLocation:指向xsd文件-->
<hr xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="hr-schema.xsd" >
<employee no="3306"> <!-- 标签和属性尽量起的有意义,做到见名知意-->
<name>张三</name>
<age>31</age>
<salary>4000</salary>
<department> <!-- 标签可以嵌套-->
<dName>会计</dName>
<dAddress>4楼103室</dAddress>
</department>
</employee>
<employee no="3377">
<name>李四</name>
<age>29</age>
<salary>5000</salary>
<department>
<dName>工程部门</dName>
<dAddress>4楼105室</dAddress>
</department>
</employee>
</hr>
读取的方法:
核心,利用Dom4j读取XML文档:下面是标准程序,以后记不清时,可以当成字典查阅、参考,慢慢熟练就好了;
/**
* 读取hr.xml
* @author Administrator
*
*/
public class HrReader {
public void readXml() {
String file = "e:/eclipse-workspace/xml/src/hr-schema.xml";
//(1) SAXReader是读取XML文件的核心类,用于将XML解析后以“树”的形式保存在内存中。
SAXReader reader = new SAXReader();
try {
// (2) SAXReader类的主要方法时read()方法,该方法返回一个Document对象;
Document document = reader.read(file);
// (3) 获取XML文档的根节点;Dom4j中所有的标签都是用Element类型来进行的包装;
Element root = document.getRootElement();
// (4) Element类型的root对象,可以调用elements()方法,获取指定的标签集合;下面就是获取根节点标签下所有标签名为“employee”的标签的Element集合
List<Element> employees = root.elements("employee");
//
for(Element employee : employees) {
// (5) element()方法用于获取唯一的子节点对象
Element name = employee.element("name");
// (6) getText()方法,用于获取name标签的文本值;
String empName = name.getText();
System.out.println(empName);
//简写:输出age,salary
System.out.println(employee.element("age").getText());
System.out.println(employee.element("salary").getText());
// 获取department节点的内容;department节点下还有子节点,所以需要多处理一步
Element department = employee.element("department");
System.out.println(department.element("dName").getText());
System.out.println(department.element("dAddress").getText());
// (7) 获取属性 :又一次印证了,DOM在处理XML的时候,遵循一切皆对象;这样挺好
Attribute att = employee.attribute("no");
System.out.println(att.getText());
}
} catch (DocumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
// 测试一下
public static void main(String[] args) {
new HrReader().readXml();
}
}
结果:
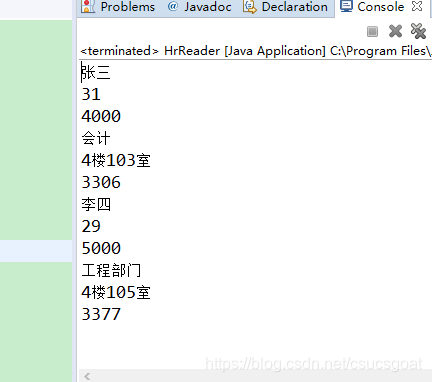
归纳:上述读取过程归纳如下(很啰嗦,这儿可以稍微瞅一瞅)
● 整个XML被读成了一个Document对象;所有的节点(包括父节点和子节点)被读成了Element对象;
● 第零步:String file = "e:/eclipse-workspace/xml/src/hr-schema.xml"; 确定,待读XML文档的路径;
● 第一步:SAXReader reader = new SAXReader(); 获得SAXReader类对象;
● 第二步:Document document = reader.read(file); 调用SAXReader类的read()方法获得,获得(整个XML文件)Document对象;
● 第三步:Element root = document.getRootElement(); 调用Document对象的getRootElement()方法获得根节点对象,作为一个Element(元素)对象;
● 第四步:List<Element> employees = root.elements("employee"); 通过调用Element的elements()方法,获得所有指定标签的Element对象的集合;
● 第五步:Element name = employee.element("name"); 通过调用Element的element()方法,获得(唯一)子节点的Element对象;
● 第六步:String empName = name.getText(); Element的getText()方法,获得标签对象的文本值;
核心就是上面几个步骤,看看就行,主要还是参考上述示例代码;
● 获取属性,第一步:Attribute att = employee.attribute("no"); 通过,ELement的attribute()方法,获得employee标签中,"no"属性的Attribute对象;
● 获取属性,第二步:System.out.println(att.getText()); 通过Attribute的geText()方法,获得属性值;
注意:上述过程会抛出DocumentException异常,需要处理;为了安全起见也可以加个IO异常啥的;

















 758
758

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









