



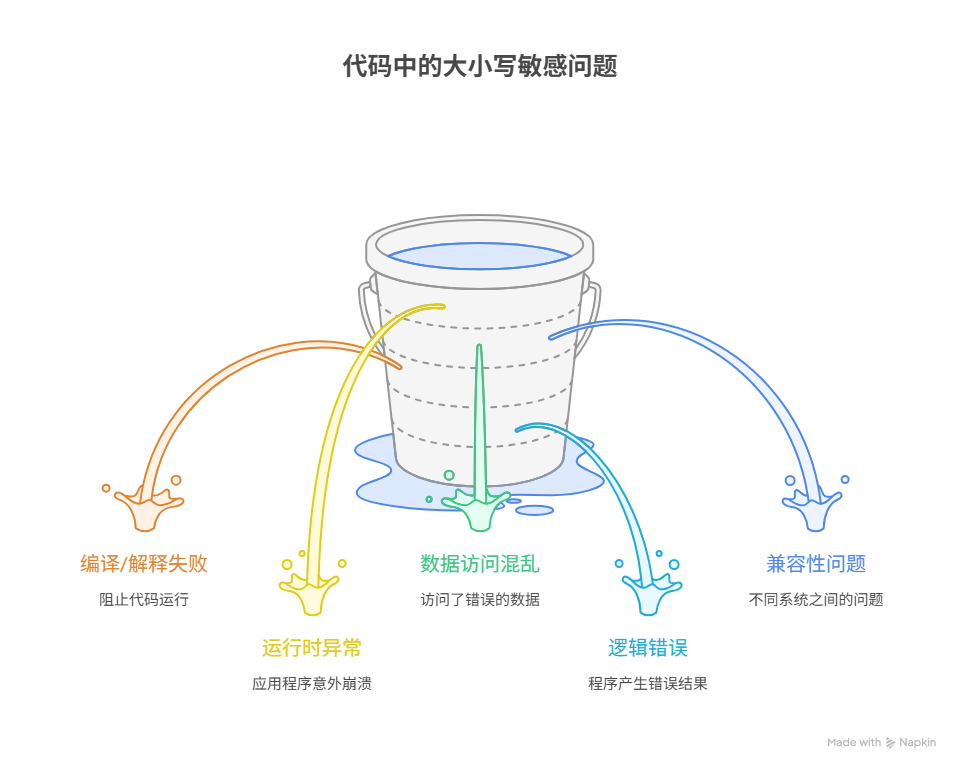
在代码中搞错大小写之所以会导致严重问题,其根本原因在于计算机系统对“标识符”的识别,是一种“字面意义”上的、精确到每一个字符的严格匹配,它缺乏人类所具备的、能够理解“意图”的模糊处理能力。对于大多数编程语言和操作系统而言,myVariable 和 myvariable 是两个完全不同的、指向不同内存地址的独立实体。这种看似微不足道的差异,会在程序的整个生命周期中,引发一系列从“编译失败”到“数据丢失”的连锁反应,其核心问题涵盖:导致编译或解释错误、引发运行时变量或函数未定义的致命异常、造成数据访问的混乱与丢失、触发难以排查的逻辑错误、以及在跨平台协作中引入潜在的兼容性灾难。
其中,引发运行时变量或函数未定义的致命异常,是这类问题中最隐蔽也最具破坏性的表现之一。在一个大小写敏感的动态语言(如JavaScript或Python)中,一个大小写错误,可能在编码和测试的“正常”路径中,都安然无事,直到某个特定的、很少被触发的业务场景下,程序试图去调用那个“大小写错误”的变量时,才会突然地、毫无征兆地,抛出一个导致整个应用程序崩溃的“未定义”异常。
一、计算机的“执拗”:为何大小写如此重要?
要理解大小写问题为何如此严重,我们必须首先深入到计算机工作的最底层,去理解其“思维模式”。与能够进行联想、推断和模糊匹配的人类大脑不同,计算机是一个绝对的“字面主义者”,其行为的唯一依据,就是被严格定义的、无歧义的“规则”。
1. “标识符”的唯一性原则
在几乎所有的编程语言中,我们所创建的变量名、函数名、类名等,都被统称为“标识符”。标识符,是我们在代码中,为一个特定的数据、一段功能逻辑、或一个对象模板,所赋予的、独一无二的“名字”。当编译器或解释器,在处理我们的代码时,它会为每一个唯一的标识符,都分配一个唯一的内存地址或符号引用。
因此,对于一个大小写敏感的系统而言,UserAge 和 userAge,在它眼中,就如同“张三”和“李四”一样,是两个完全没有关联的、截然不同的“人”。它绝不会去“猜测”:“哦,这个程序员,可能只是不小心把首字母小写了,他/她们指的,应该是同一个东西。” 这种“猜测”,是人类的特权,而非计算机的能力。
2. 大小写敏感与不敏感的“世界观”
大小写敏感:这是计算机世界的“主流”。绝大多数的、被广泛使用的编程语言(如Java, C++, C#, Python, JavaScript, Go, Ruby, Swift等),以及服务器领域占据绝对主导地位的类Unix操作系统(如Linux, MacOS),都默认是严格区分大小写的。
大小写不敏感:也存在一些“特例”。例如,一些历史悠久的语言(如Visual Basic, Pascal),以及在特定配置下的SQL语言和Windows操作系统的文件系统,对大小写是不敏感的。
正是因为这两种不同的“世界观”并存,才使得大小写问题,特别是在“跨平台”的协作中,变得尤为棘手和重要。
计算机科学巨匠高德纳(Donald Knuth)曾精辟地指出:“计算机非常擅长遵循指令,但不擅长读懂你的思想。”(Computers are good at following instructions, but not at reading your mind.)大小写错误,正是程序员,将自己“脑中所想”,错误地“写在纸上”,从而导致“只会照本宣科”的计算机,无法正确执行的典型案例。
二、问题一:“编译”与“运行”时的“致命伤”
这是大小写错误最直接、也最常见的表现形式,它直接导致程序无法正常构建或运行。
1. 编译时错误:找不到的“符号”
在静态编译型语言(如Java, C++, C#)中,大小写错误,通常会在“编译阶段”,就被编译器所捕获,从而以一种“快速失败”的形式暴露出来。
场景示例:假设我们在Java中,定义了一个类 UserManager。Javapublic class UserManager { public void addUser() { // ... } } // 在另一个文件中,我们试图去使用它 userManager myManager = new userManager(); // 错误!
问题分析:在第二行代码中,因为我们将类名 UserManager 错误地写成了 userManager(首字母小写),编译器在进行类型检查时,会发现,在它的整个“符号表”中,根本不存在一个名为 userManager 的类定义。因此,它会立即中断编译,并抛出一个清晰的错误:“找不到符号:类 userManager”。
影响:这类错误,虽然会导致程序无法构建,但因为其暴露得非常早,且错误信息通常非常明确,所以修复成本相对较低。
2. 运行时异常:未定义的“变量”
在动态解释型语言(如JavaScript, Python)中,情况则要凶险得多。大小写错误,常常能够“逃逸”过编译或语法检查阶段,直到在程序实际运行到那一行错误的代码时,才会以“运行时异常”的形式爆发。
场景示例:假设我们在JavaScript中,有一段处理用户输入的代码。JavaScriptlet userName = "Alice"; // ... 经过了大量的、复杂的其他代码 ... if (username) { // 错误! console.log("Welcome, " + username); }
问题分析:我们定义变量时,使用的是驼峰式的 userName。但在数百行代码之后的一个if判断中,我们不小心,将其全部写成了小写 username。在JavaScript中,访问一个不存在的变量,其值是 undefined,在布尔判断中,会被视为false。
影响:这个错误,不会导致程序立即崩溃。它只会让那个if代码块,永远不会被执行。用户可能会发现“欢迎信息”莫名其妙地消失了,而开发者,则需要花费大量的时间,去调试为何一个看似简单的逻辑,没有按预期执行。这种“沉默的失败”,远比一个明确的崩溃,更难排查。
更严重的情况是,如果后续的代码,试图去调用这个未定义变量的“方法”(例如,username.trim()),那么,程序就会在那个时刻,毫无征兆地,抛出一个“无法读取undefined的属性‘trim’”的致命异常,导致整个应用程序的崩溃。
三、问题二:数据的“无声”灾难
如果说编译和运行时的错误,是“响亮”的警报,那么,由大小写错误,所导致的数据问题,则更像是一场“无声的”、但后果同样严重的灾难。
1. 配置文件中的“键”不匹配
现代应用,常常通过JSON或YAML等格式的文件,来进行配置。这些格式,通常都是大小写敏感的。
场景:在配置文件中,我们定义了数据库的连接地址:"databaseURL": "..."。而在我们的代码中,读取这个配置的代码,却错误地写成了 config.databaseUrl。
后果:程序在启动时,无法获取到正确的数据库地址。其最终表现,可能是一个关于“数据库连接失败”的、看似与大小写毫无关系的、令人困惑的错误。
2. 数据库查询的“陷阱”
虽然SQL语言的关键字(如SELECT, FROM, WHERE)通常是大小写不敏感的,但数据库中的“表名”、“列名”以及“数据本身”,其大小写敏感性,则取决于数据库的类型和其“排序规则”的配置。
更重要的是,我们应用程序代码中,用于映射数据库列的“对象属性名”,几乎总是大小写敏感的。例如,数据库中有一列名为 user_name,而在我们的代码实体类中,我们将其映射为了 userName。如果我们不小心,在代码的某个查询中,试图去访问 username,那么,这个字段的数据,就会被“静默地”丢失,永远无法被正确地读取出来。
3. 数据传输的“失联”
在前后端分离、微服务盛行的今天,数据,通常以JSON的格式,在不同的服务之间进行传输。这个序列化和反序列化的过程,是大小写错误的“重灾区”。
场景:前端发送了一个JSON请求体:{"UserName": "Bob", "Age": 25}。而后端接收这个数据的Java或C#对象,其属性定义是:String userName; 和 int age;。
后果:由于大小写的不匹配(UserName vs userName, Age vs age),自动化的数据绑定框架,将无法正确地,将JSON中的值,映射到对象的属性上。其结果是,后端服务接收到的,是一个**属性值都为“空”**的对象,并可能因此,而触发一系列的、非预期的业务逻辑错误。
四、问题三:跨平台协作的“噩梦”
这是由不同操作系统的“世界观”不同,而导致的、极具迷惑性的“终极噩梦”。
1. 文件系统的“不统一”
Windows的文件系统,是大小写不敏感,但保留大小写的。这意味着,在Windows上,File.txt 和 file.txt 被认为是同一个文件,你无法在同一个目录下,同时创建这两个文件。
而Linux和MacOS(在大多数默认配置下)的文件系统,则是严格区分大小写的。File.txt 和 file.txt 是两个完全独立的文件。
2. “在我的电脑上是好的啊!”
这个操作系统层面的差异,是导致“本地正常,服务器异常”这类问题的最常见原因。
场景:一位使用Windows电脑的前端开发者,在代码中,引用了一张图片:<img src="./images/logo.png">。而他实际提交到代码库中的文件名,却是 Logo.png(首字母大写)。
后果:在他的Windows电脑上,因为文件系统不区分大小写,所以图片显示一切正常。然而,当代码被部署到大小写敏感的Linux生产服务器上时,服务器会因为找不到那个“严格”名为 logo.png 的文件,而导致图片加载失败,出现一个“破图”。
3. Git版本控制中的“隐形”冲突
Git在设计时,为了兼容不同的操作系统,其本身,是可以被配置为“忽略”或“尊重”文件名的大小写的。在Windows上,Git默认会“忽略”大小写。
场景:一个Windows开发者,将一个文件名,从 MyComponent.js 修改为了 myComponent.js,然后提交了代码。
后果:在他的系统上,Git可能不会将此,识别为一次“重命名”,而只是认为文件内容发生了变化。然而,当一个使用Linux或MacOS的同事,拉取这个更新时,他的文件系统,可能会因为试图在同一个目录下,处理两个“不同”的文件(MyComponent.js 和 myComponent.js)而产生严重的冲突,甚至导致代码库的本地状态被破坏。
五、如何“预防”:建立“免疫系统”
要从根本上,避免这些由大小写错误所导致的严重问题,我们必须建立一个多层次的“免疫系统”。
1. 制定并严格遵守“命名规范” 这是最核心、也最重要的预防措施。团队必须就代码中,所有类型“标识符”的命名,达成一个统一的、书面化的、并被严格遵守的规范。
驼峰命名法:例如 myVariableName,通常用于变量和函数名。
帕斯卡命名法(大驼峰):例如 MyClassName,通常用于类名。
蛇形命名法:例如 my_variable_name,在Python等语言中,常用于变量和函数名。
2. 善用“静态代码分析”工具 在现代的开发流程中,我们不应只依赖于“人的自觉”。应将命名规范,配置到静态代码分析工具(Linter)中去(如ESLint, Pylint, Checkstyle等)。这些工具,可以在代码被提交之前,就自动地,扫描出所有不符合规范的命名,并给出警告甚至错误。
3. 实施“代码审查” 人类的眼睛,对于发现“模式”和“不一致”,依然具有不可替代的作用。将“代码审查”(Code Review)作为团队的强制性流程,能够有效地,在同行之间,相互检查和纠正潜在的大小写错误。
4. 统一“开发与生产”环境 为了根除因文件系统差异而导致的问题,最佳实践是,使用容器化技术(如Docker),来确保所有团队成员的本地开发环境,与测试、生产环境,在操作系统层面,保持100%的一致。
5. 在工具中“固化”规范 所有这些规范和约定,都不应只是口头说说。它们应该被文档化,并沉淀到团队的“共享知识库”中。
一个像 Worktile 或 PingCode 内置的知识库功能,是撰写和维护这份《团队编码与命名规范》的理想场所。它可以确保,所有现有的、和未来新加入的成员,都能方便地,查阅到这份团队的“最高法典”。
更进一步,在像 PingCode 这样的研发管理平台中,可以将“静态代码分析”的步骤,直接集成到其持续集成的流水线中,并将其,设置为一个“质量门禁”。任何包含了不符合命名规范代码的提交,都将无法通过这个“门禁”,从而在技术流程上,强制性地,保障了规范的落地。
常见问答 (FAQ)
Q1: 为什么有些编程语言(如SQL)对大小写不敏感?
A1: 这通常是出于历史原因和设计哲学的考虑。早期的、旨在让非专业程序员(如业务分析师)也能使用的语言,常常会选择大小写不敏感,以降低学习门槛、提高容错性。但现代的主流编程语言,则普遍选择了大小写敏感,因为它能提供更高的精确性,并避免潜在的命名冲突。
Q2: 文件名的大小写问题,在所有操作系统上都一样吗?
A2: 不一样。Windows和早期的MacOS文件系统,默认是“不敏感”的。而Linux和当前主流配置下的MacOS,则是“敏感”的。这正是导致跨平台协作中,出现“本地正常,线上异常”这类诡异问题的根源。
Q3: 如何修复一个已经因为大小写问题,在Git仓库中产生冲突的文件?
A3: 一个安全、标准的修复方法是,使用git mv命令,来进行一次明确的、能被所有操作系统正确识别的“重命名”操作。例如,先将MyFile.js重命名为MyFile_temp.js,提交一次;然后再将MyFile_temp.js重命名为myfile.js,再提交一次。
Q4: 除了遵循命名规范,还有什么个人习惯可以帮助减少这类错误?
A4: 善用现代代码编辑器或集成开发环境的“自动补全”功能。当你开始输入一个变量或函数名时,让工具来为你补全它,而不是完全依赖于自己的手打和记忆。这能极大地,减少因“手误”而导致的大小写错误。

















 17万+
17万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









