



- 资源使用过高
- jstack保存堆栈信息
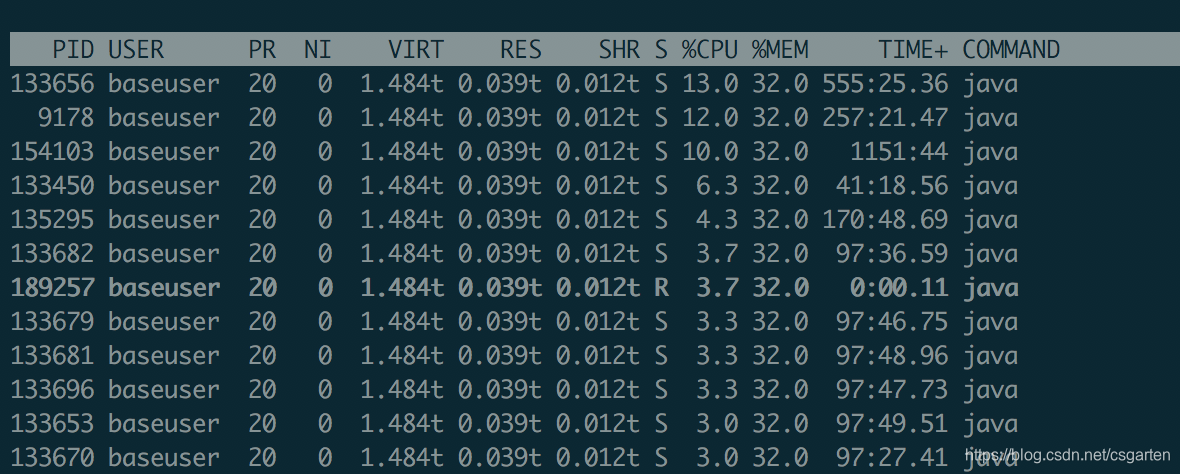
- top 查看机器负载情况
- top -H -pPID 查看线程耗费资源信息排行
- 将PID转化为16进制,去dump信息中找寻 具体线程的堆栈信息,查看耗费资源信息原因
- 结合慢日志信息排查问题
- 节点宕掉
- 查看宕机信息
- 重启节点
- 分析OOM产生的dump信息
- 结合慢查询日志分析宕机主要原因
赞成为第一个赞同者
 本文介绍如何通过jstack保存堆栈信息、top命令查看机器负载情况等手段来定位资源使用过高的问题,并提供了分析OOM产生的dump信息及结合慢查询日志分析宕机原因的方法。
本文介绍如何通过jstack保存堆栈信息、top命令查看机器负载情况等手段来定位资源使用过高的问题,并提供了分析OOM产生的dump信息及结合慢查询日志分析宕机原因的方法。
赞成为第一个赞同者
 860
1502
1231
860
1502
1231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























