



 本文详细介绍了Sharding-JDBC中的数据源和表分片策略,包括分片键、分片算法及其实现方法。同时,探讨了读写分离配置及其在解决读延迟问题上的策略。
本文详细介绍了Sharding-JDBC中的数据源和表分片策略,包括分片键、分片算法及其实现方法。同时,探讨了读写分离配置及其在解决读延迟问题上的策略。
Sharding-JDBC中的分片策略有两个维度,分别是:
- 数据源分片策略(DatabaseShardingStrategy)
- 表分片策略(TableShardingStrategy)
其中,数据源分片策略表示:数据路由到的物理目标数据源,表分片策略表示数据被路由到的目标表。
特别的,表分片策略是依赖于数据源分片策略的,也就是说要先分库再分表,当然也可以只分表。
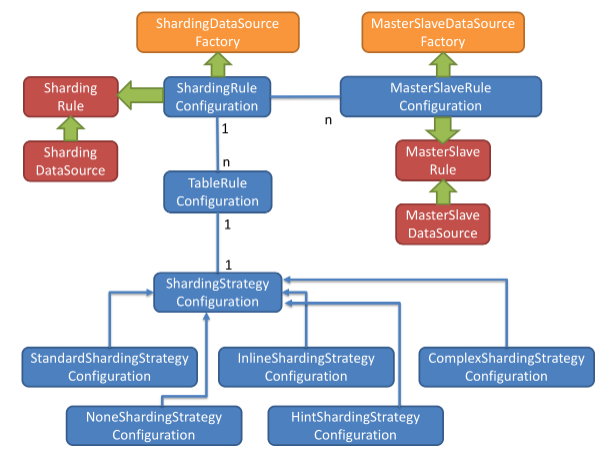
Sharding-JDBC的数据分片策略
Sharding-JDBC的分片策略包含了分片键和分片算法。由于分片算法与业务实现紧密相关,因此Sharding-JDBC没有提供内置的分片算法,而是通过分片策略将各种场景提炼出来,提供了高层级的抽象,通过提供接口让开发者自行实现分片算法。
以下内容引用自官方文档。官方文档
首先介绍四种分片算法。
通过分片算法将数据分片,支持通过=、BETWEEN和IN分片。
分片算法需要应用方开发者自行实现,可实现的灵活度非常高。目前提供4种分片算法。由于分片算法和业务实现紧密相关,
因此并未提供内置分片算法,而是通过分片策略将各种场景提炼出来,
提供更高层级的抽象,并提供接口让应用开发者自行实现分片算法。
分片键
用于分片的数据库字段,是将数据库(表)水平拆分的关键字段。例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。 SQL中如果无分片字段,将执行全路由,性能较差。 除了对单分片字段的支持,ShardingSphere也支持根据多个字段进行分片。
分片算法
通过分片算法将数据分片,支持通过=、BETWEEN和IN分片。分片算法需要应用方开发者自行实现,可实现的灵活度非常高。
目前提供4种分片算法。由于分片算法和业务实现紧密相关,因此并未提供内置分片算法,而是通过分片策略将各种场景提炼出来,提供更高层级的抽象,并提供接口让应用开发者自行实现分片算法。
- 精确分片算法
对应PreciseShardingAlgorithm,用于处理使用单一键作为分片键的=与IN进行分片的场景。需要配合StandardShardingStrategy使用。
- 范围分片算法
对应RangeShardingAlgorithm,用于处理使用单一键作为分片键的BETWEEN AND进行分片的场景。需要配合StandardShardingStrategy使用。
- 复合分片算法
对应ComplexKeysShardingAlgorithm,用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。需要配合ComplexShardingStrategy使用。
- Hint分片算法
对应HintShardingAlgorithm,用于处理使用Hint行分片的场景。需要配合HintShardingStrategy使用。
分片策略
包含分片键和分片算法,由于分片算法的独立性,将其独立抽离。真正可用于分片操作的是分片键 + 分片算法,也就是分片策略。目前提供5种分片策略。
- 标准分片策略
对应StandardShardingStrategy。提供对SQL语句中的=, IN和BETWEEN AND的分片操作支持。StandardShardingStrategy只支持单分片键,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法。PreciseShardingAlgorithm是必选的,用于处理=和IN的分片。RangeShardingAlgorithm是可选的,用于处理BETWEEN AND分片,如果不配置RangeShardingAlgorithm,SQL中的BETWEEN AND将按照全库路由处理。
- 复合分片策略
对应ComplexShardingStrategy。复合分片策略。提供对SQL语句中的=, IN和BETWEEN AND的分片操作支持。ComplexShardingStrategy支持多分片键,由于多分片键之间的关系复杂,因此并未进行过多的封装,而是直接将分片键值组合以及分片操作符透传至分片算法,完全由应用开发者实现,提供最大的灵活度。
- 行表达式分片策略
对应InlineShardingStrategy。使用Groovy的表达式,提供对SQL语句中的=和IN的分片操作支持,只支持单分片键。对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发,如: t_user_$->{u_id % 8} 表示t_user表根据u_id模8,而分成8张表,表名称为t_user_0到t_user_7。
- Hint分片策略
对应HintShardingStrategy。通过Hint而非SQL解析的方式分片的策略。
- 不分片策略
对应NoneShardingStrategy。不分片的策略。
SQL Hint
对于分片字段非SQL决定,而由其他外置条件决定的场景,可使用SQL Hint灵活的注入分片字段。例:内部系统,按照员工登录主键分库,而数据库中并无此字段。SQL Hint支持通过Java API和SQL注释(待实现)两种方式使用。
-----------------------------------------------------------分库分表----------------------------------------------------------------------------------------
<!--sharding-jdbc -->
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>3.1.0</version>
</dependency>
<!--sharding-jdbc结束-->sharding-jdbc 按月份分表需要自己实现。需要实现两个接口PreciseShardingAlgorithm,RangeShardingAlgorithm。并在配置文件里添加实现路径
如下:com.simianBook.conf.TimeShardingTableAlgorithm
sharding:
jdbc:
datasource:
names: user-0,user-1
user-0: #springboot 在yml 配置里key不支持 '_' 推荐使用'-'
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/t_user_0?characterEncoding=UTF-8&serverTimezone=GMT
username: root
password: hou1147646079
user-1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/t_user_1?characterEncoding=UTF-8&serverTimezone=GMT
username: root
password: hou1147646079
config:
sharding: #分片
default-database-strategy:#数据库默认分库
inline:
sharding-column: user_id
algorithm-expression: user ->${user_id % 2}
props:
sql.show: true
tables:
user:
key-generator-column-name: user_id #user 表的主键
database-strategy:
inline:
shardingColumn: user_id #数据库分片测略
algorithm-expression: user-${user_id % 2} #
# actual-data-nodes: user-${0..1}.user_${0..1} #设置的datasource 的名字 如user-0,user-1,user_${0..1} 数据库中的
table-strategy:
standard: # 单列sharidng算法,需要配合对应的preciseShardingAlgorithm,rangeShardingAlgorithm接口的实现使用,目前无生产可用实现
shardingColumn: user_id # 列名,允许单列
precise-algorithm-class-name: com.simianBook.config.TimeShardingTableAlgorithm # preciseShardingAlgorithm接口的实现类
# rangeShardingAlgorithm: # rangeShardingAlgorithm接口的实现类
# inline:
# sharding-column: user_id
# algorithm-expression: user_${user_id % 2}
defaultTableStrategy:
none:
defaultKeyGenerator:
type: SNOWFLAKE
按月分表查询更新
因为SimpleDateFormat 不是线程安全的需要修改为DateTimeFormatter
import com.google.common.collect.Range;
import com.simianBook.tool.GenericTool;
import com.simianBook.tool.ParaseShardingKeyTool;
import io.shardingsphere.api.algorithm.sharding.RangeShardingValue;
import io.shardingsphere.api.algorithm.sharding.standard.RangeShardingAlgorithm;
import io.shardingsphere.core.keygen.DefaultKeyGenerator;
import java.text.SimpleDateFormat;
import java.time.Instant;
import java.time.LocalDate;
import java.time.LocalDateTime;
import java.time.ZoneId;
import java.time.format.DateTimeFormatter;
import java.util.Calendar;
import java.util.Collection;
import java.util.Date;
import java.util.LinkedHashSet;
import java.util.stream.Stream;
/**
* 搜查多表
* 范围搜索时(跨表)应传递时间戳并左移22位
*/
public class TimeRangeShardingAlgorithm implements RangeShardingAlgorithm<Long> {
private DateTimeFormatter dateformat = DateTimeFormatter.ofPattern("yyyyMM");
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<Long> shardingValue) {
Collection<String> result = new LinkedHashSet<String>();
Range<Long> shardingKey = shardingValue.getValueRange();
long startShardingKey = shardingKey.lowerEndpoint();
long endShardingKey = shardingKey.upperEndpoint();
//获取到开始时间戳
String startTimeString = ParaseShardingKeyTool.getYearAndMonth(startShardingKey);
//获取结束时间戳
String endTimeString = ParaseShardingKeyTool.getYearAndMonth(endShardingKey);
Calendar cal = Calendar.getInstance();
//获取开始的年月
//时间戳
LocalDateTime startLocalDate = GenericTool.getLocalDate(startTimeString);
//获取结束的年月
LocalDateTime endLocalDate = GenericTool.getLocalDate(endTimeString);
//进行判断 获取跨月份的表 如201901,201902,201903 三个月的表
//目前只支持同一年内的查询,跨年不支持
int end = Integer.valueOf(dateformat.format(endLocalDate));
int start = Integer.valueOf(dateformat.format(startLocalDate));
while(start <= end){
StringBuffer tableName = new StringBuffer();
tableName.append(shardingValue.getLogicTableName())
.append("_").append(start);
result.add(tableName.toString());
start++;
}
return result;
}
}使用到的方法
import io.shardingsphere.core.keygen.DefaultKeyGenerator;
import java.text.SimpleDateFormat;
import java.time.Instant;
import java.time.LocalDate;
import java.time.LocalDateTime;
import java.time.ZoneId;
import java.time.format.DateTimeFormatter;
public class ParaseShardingKeyTool {
private static DateTimeFormatter yearAndMonth = DateTimeFormatter.ofPattern("yyyyMM");
private static DateTimeFormatter year = DateTimeFormatter.ofPattern("yyyy");
public static String getYearAndMonth(long shardingKey){
Instant instant = Instant.ofEpochMilli(DefaultKeyGenerator.EPOCH+(Long.valueOf(shardingKey+"")>>22));
LocalDateTime localDateTime = LocalDateTime.ofInstant(instant, ZoneId.systemDefault());
return yearAndMonth.format(localDateTime);
}
public static String getYear(long shardingKey){
Instant instant = Instant.ofEpochMilli(DefaultKeyGenerator.EPOCH+(Long.valueOf(shardingKey+"")>>22));
LocalDateTime localDateTime = LocalDateTime.ofInstant(instant, ZoneId.systemDefault());
return year.format(localDateTime);
}
public static void main(String[] args) {
DefaultKeyGenerator defaultKeyGenerator = new DefaultKeyGenerator();
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyyMM");
System.out.println(simpleDateFormat.format(System.currentTimeMillis()));
System.out.println(ParaseShardingKeyTool.getYearAndMonth(Long.valueOf(defaultKeyGenerator.generateKey()+"")));
System.out.println(ParaseShardingKeyTool.getYearAndMonth(Long.valueOf(defaultKeyGenerator.generateKey()+"")));
}
}
下面需要来编写按单月分表的方法
package com.simianBook.config;
import com.simianBook.tool.ParaseShardingKeyTool;
import io.shardingsphere.api.algorithm.sharding.PreciseShardingValue;
import io.shardingsphere.api.algorithm.sharding.standard.PreciseShardingAlgorithm;
import java.text.SimpleDateFormat;
import java.time.format.DateTimeFormatter;
import java.util.Collection;
public class TimeShardingTableAlgorithm implements PreciseShardingAlgorithm<Long> {
private DateTimeFormatter dateformat = DateTimeFormatter.ofPattern("yyyyMM");
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> shardingValue) {
StringBuffer tableName = new StringBuffer();
tableName.append(shardingValue.getLogicTableName())
.append("_").append(ParaseShardingKeyTool.getYearAndMonth(shardingValue.getValue()));
return tableName.toString();
}
}
我是使用sharding-jdbc 自带的雪花算法 来生成主键的,雪花算法的实现逻辑
因此我在得到分片键时对分片键进行逆推可以推出分片键的时间戳。再根据时间戳得到创建此条数据创建的年月进而定位到那个表位置(或者说表名)
DefaultKeyGenerator.EPOCH+(Long.valueOf(shardingKey+"")>>22)
DefaultKeyGenerator.EPOCH 表示起始时间。在雪花算法当中生成的时间戳需要减去起始时间在进行左移22位在进行或运算
sharding-jdbc 的雪花实现方法如下 版本3.0 该版本有bug 并发量低的时候生成的分片键始终为偶数
public synchronized Number generateKey() {
long currentMillis = timeService.getCurrentMillis();
Preconditions.checkState(this.lastTime <= currentMillis, "Clock is moving backwards, last time is %d milliseconds, current time is %d milliseconds", new Object[]{this.lastTime, currentMillis});
if (this.lastTime == currentMillis) { //最新时间与当前时间相同(发生并发)
// //sequence+1 如果suquence&4095L==0时条件成立时
if (0L == (this.sequence = this.sequence + 1L & 4095L)) {
currentMillis = this.waitUntilNextTime(currentMillis);//获取最新时间
}
} else {
this.sequence = 0L; //此处有bug 并发量低的时候this.sequence始终为0L的
}
this.lastTime = currentMillis;
return currentMillis - EPOCH << 22 | workerId << 12 | this.sequence;
}3.1.0 版本解决了 自己可以看一下有什么不同
public synchronized Number generateKey() {
long currentMilliseconds = timeService.getCurrentMillis();
if (this.waitTolerateTimeDifferenceIfNeed(currentMilliseconds)) {
currentMilliseconds = timeService.getCurrentMillis();
}
if (this.lastMilliseconds == currentMilliseconds) {
if (0L == (this.sequence = this.sequence + 1L & 4095L)) {
currentMilliseconds = this.waitUntilNextTime(currentMilliseconds);
}
} else {
this.vibrateSequenceOffset();
this.sequence = (long)this.sequenceOffset;
}
this.lastMilliseconds = currentMilliseconds;
return currentMilliseconds - EPOCH << 22 | workerId << 12 | this.sequence;
}工具类
package com.simianBook.tool;
import io.shardingsphere.core.keygen.DefaultKeyGenerator;
import org.apache.commons.lang.StringUtils;
import java.lang.management.ManagementFactory;
import java.math.BigDecimal;
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
import java.time.Instant;
import java.time.LocalDateTime;
import java.time.ZoneId;
import java.util.regex.Pattern;
/**
* @program: simianBook1
* @description: 通用工具类
* @author: houzi
* @create: 2019-03-14 10:54
*/
public class GenericTool {
private static final String EMAIL_FORMAT =" /^\\w+([\\.-]?\\w+)*@\\w+([\\.-]?\\w+)*(\\.\\w{2,3})+$/";
public static long getWorkId(){
String name = ManagementFactory.getRuntimeMXBean().getName();
long workId =Long.valueOf(name.split("@")[0]);
return workId;
}
/**
*
* @return
*/
public static long getSahrdingKey(){
long workId = GenericTool.getWorkId();
DefaultKeyGenerator.setWorkerId(workId);
DefaultKeyGenerator defaultKeyGenerator = new DefaultKeyGenerator();
GenericTool.getWorkId();
return Long.valueOf(defaultKeyGenerator.generateKey()+"");
}
/**
* 通过时间戳获取时间
* @param timestamp
* @return
*/
public static LocalDateTime getLocalDate(String timestamp){
Instant startInstant = Instant.ofEpochMilli(Long.valueOf(timestamp));
LocalDateTime localDate = LocalDateTime.ofInstant(startInstant, ZoneId.systemDefault());
return localDate;
}
public static boolean isEmail(String email){
if(StringUtils.isBlank(email)){
return false;
}
return Pattern.matches(EMAIL_FORMAT,email);
}
}
-------------------------------------------------------------------读写分离------------------------------------------------------------------------------------------
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
datasource:
names:
master,slave
# 主数据源
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/db_master?characterEncoding=utf-8
username: ****
password: ****
# 从数据源
slave:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/db_slave?characterEncoding=utf-8
username: ****
password: ****
masterslave:
# 读写分离配置
load-balance-algorithm-type: round_robin
# 最终的数据源名称
name: dataSource
# 主库数据源名称
master-data-source-name: master
# 从库数据源名称列表,多个逗号分隔
slave-data-source-names: slave
props:
# 开启SQL显示,默认false
sql:
show: trueload-balance-algorithm-type 用于配置从库负载均衡算法类型,可选值:ROUND_ROBIN(轮询),RANDOM(随机)
props.sql.show=true 在执行SQL时,会打印SQL,并显示执行库的名称
读写分离架构中经常出现,那就是读延迟的问题如何解决?
刚插入一条数据,然后马上就要去读取,这个时候有可能会读取不到?归根到底是因为主节点写入完之后数据是要复制给从节点的,读不到的原因是复制的时间比较长,也就是说数据还没复制到从节点,你就已经去从节点读取了,肯定读不到。mysql5.7 的主从复制是多线程了,意味着速度会变快,但是不一定能保证百分百马上读取到,这个问题我们可以有两种方式解决:
(1)业务层面妥协,是否操作完之后马上要进行读取
(2)对于操作完马上要读出来的,且业务上不能妥协的,我们可以对于这类的读取直接走主库,当然Sharding-JDBC也是考虑到这个问题的存在,所以给我们提供了一个功能,可以让用户在使用的时候指定要不要走主库进行读取。在读取前使用下面的方式进行设置就可以了:
public List<UserInfo> getList() {
// 强制路由主库
HintManager.getInstance().setMasterRouteOnly();
return this.list();
}

















 8806
8806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









