 协同压缩突破T级模型内存墙
协同压缩突破T级模型内存墙





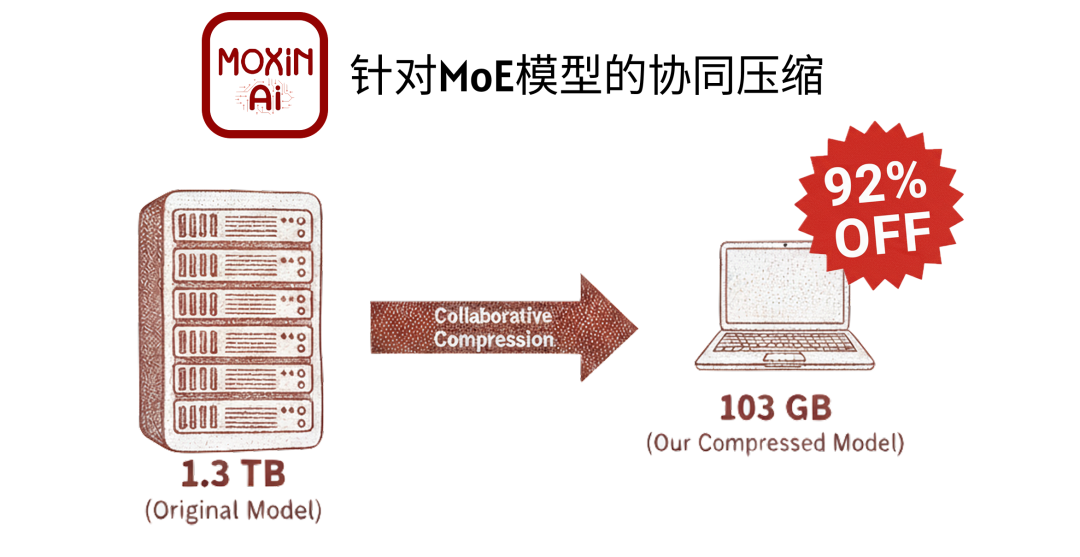
本文介绍的“协同压缩”框架,首次成功将 T 级参数的 MoE 大模型部署到 128GB 内存的消费级 PC 上,实现了 >5 tokens/秒的本地推理。该工作由 Moxin AI 团队完成,于 GOSIM HANGZHOU 2025 大会上由美国东北大学王言治教授进行了演讲收录。
近年来,混合专家(MoE)架构已成为扩展大语言模型(LLMs)至数万亿参数的首选路径。通过稀疏激活策略,MoE 模型在保持计算成本(FLOPs)相对较低的同时,实现了模型容量的巨大飞跃。
然而,这种架构也带来了新的系统挑战,即“内存墙”悖论(Memory Wall):尽管推理时的计算是稀疏的,但模型的存储却是密集的。为了让路由网络(Gating)能从庞大的专家库中进行选择,所有专家的全量参数(如 DeepSeek-V3 的 1.3TB)都必须完整加载到内存中。这使得T级模型被牢牢限制在数据中心,边缘部署(Edge Deployment)几无可能。
为了突破 128GB 这样的消费级硬件内存限制,模型必须实现超过 10x 的极端压缩率。传统的单一压缩策略在如此激进的目标下面临失效:
1. 激进剪枝(Pruning)的失效: 为达到目标而裁剪掉(例如 90%)的专家,将导致模型知识的灾难性损失和路由机制的紊乱,性能严重下降。
2. 激进量化(Quantization)的失效: 统一的极低比特量化(如 1.5-bit)会严重破坏权重精度。如下图所示,强行量化到 1.5bpw 的 130GB 模型,其性能已完全崩溃,面对提问只会输出乱码。

低比特量化模型输出乱码
3. 传统方案的局限:
卸载(Offloading): 仅靠权重卸载策略不足以满足 128GB 的严格内存限制。
主流框架的短板: GPTQ/AWQ 等量化方法缺乏对超低比特的支持(通常仅限 3/4-bit CUDA 核);同时,KTransformers 等基于 PyTorch 的框架缺乏对 Apple Silicon、AMD、Windows 等多样化边缘平台的兼容性。
单一策略无法解决这个系统性问题。为此,Moxin AI 团队提出了一种全新的“协同压缩”(Collaborative Compression)框架,旨在通过多阶段、多策略的协同优化,在实现极限压缩率的同时,保持模型的推理能力。

核心方法:三阶段协同压缩框架
该框架的核心思想是,压缩不是一个单一的步骤,而是一个环环相扣的流程。团队设计了一个由专家剪枝、激活调整与卸载、和混合精度量化三个阶段组成的协同系统。
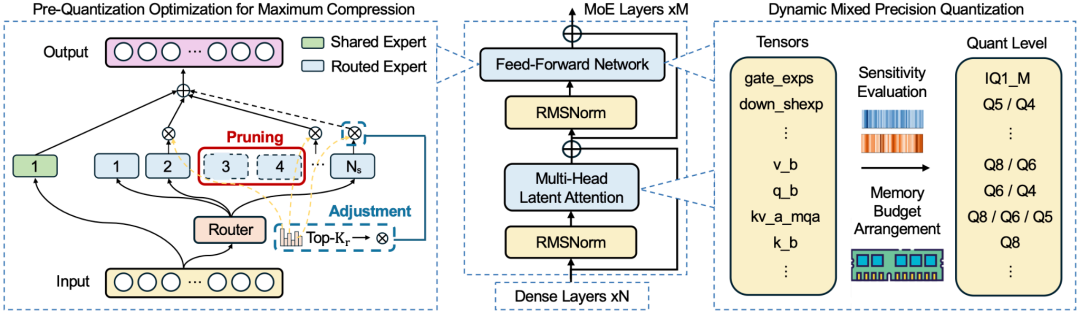
第一阶段:性能感知专家剪枝 (Performance-Aware Expert Pruning)
传统剪枝要么随机移除,要么仅凭粗略指标。本框架则采用“性能感知”策略,对专家的贡献度进行精细评估。
具体而言,框架会分析专家的两个关键指标:激活频率 (Freq) 和路由得分 (Score)。通过加权公式 ( I = α × Freq + (1 - α) × Score ) 量化每个专家的实际贡献度,从而智能地移除那些“贡献最低”的专家,最大限度地保留模型的“核心智囊”。
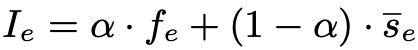
第二阶段:硬件感知激活调整 (Hardware-Aware Activation Adjustment)
这是确保剪枝后性能稳定的关键。在移除大量专家后,原始的路由机制如果保持不变,会导致严重的路由不匹配(Mismatch)。
本框架专注于修复这种结构性损伤:它根据剪枝后保留的专家比例,按比例缩放路由器的激活参数(如 num_experts_per_tok)。这一步骤使路由机制与新的、更精简的专家集重新对齐,确保模型在结构大幅精简后,依然能够维持正确的逻辑通路。
第三阶段:混合精度量化 (Mixed-Precision Quantization)
在模型结构精简并确定卸载策略后,框架会进行最后、也是最关键的量化阶段。这是一种非统一的、精细化的混合精度策略,其核心是 llama.cpp 等支持跨平台(Apple, AMD, Intel)超低比特(IQ1/IQ2)的 GGUF 格式。
1. 基准量化:首先,将精简后的模型整体量化到一个极低的基准精度(如 IQ1M)。
2. 敏感性分析:随后,框架执行“张量级敏感性分析”(Tensor-Level Sensitivity Analysis)。它会遍历模型的关键张量(尤其是 Attention 模块和路由层),通过“试探性”地将其临时升级到更高精度(如 Q8、Q4)来测量模型性能(如 PPL)的提升。
3. 预算分配与回退:最后,在一个严格的全局内存预算(例如 103GB)内,框架会优先将“比特预算”分配给那些“敏感性最高”的张量。如果超出预算,则启动“回退策略”(Back-off strategy),例如将低敏感度的张量降级,以确保模型大小绝对符合硬件限制。
这套“剪枝-调整-量化”的协同策略,实现了在保留核心性能的前提下,对模型体积的极限压缩。
部署策略:动态权重卸载 (Dynamic Weight Offloading)
为突破 128GB 内存瓶颈,框架引入了推理时的动态卸载机制。它能智能地将低频专家张量卸载至 CPU,通过 CPU/GPU 协同计算平衡负载,在确保模型完整加载的同时带来最高 25% 的加速。

实验结果与验证
团队通过一系列实验,验证了该协同框架的有效性和优越性。
1. 核心成果:实现 T 级模型的本地化部署
最引人注目的成果是,团队将 671B 参数的 DeepSeek-V3 模型(原始 1.3TB)压缩至 103GB。
这不是一次理论模拟。团队成功在 128G B内存的商用 AI 笔记本(AMD RyzenAI Max + "StrixHalo")上实现了该模型的本地部署和运行,并获得了 >5 tokens/秒的可用推理速度。据我们所知,这是 T 级参数的 MoE 模型首次在消费级 PC 硬件上成功运行。

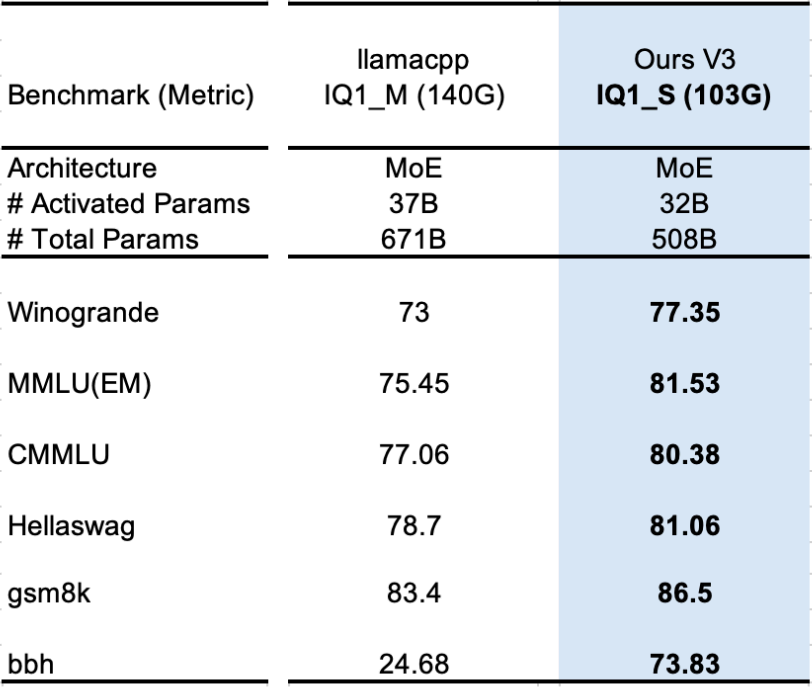
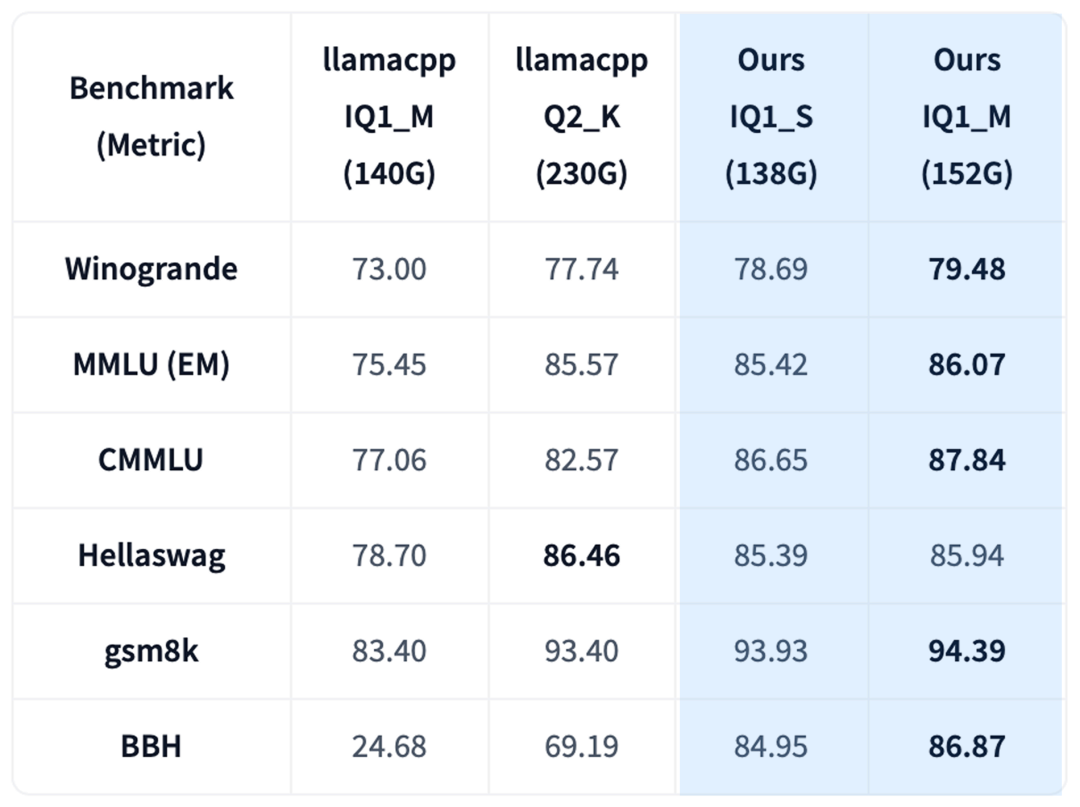
2. 性能对比 (1):103GB vs 140GB (DeepSeek-V3)
压缩不仅是为了“能跑”,更是为了“好用”。团队将他们的 103GB 压缩模型与标准的 140GB 统一低比特量化模型(llama.cpp IQ1_M)进行了基准对比。
结果显示(见下表),在 MMLU、GSM8K 等多项测试中,103GB 的协同压缩模型全面超越了 140GB 的统一量化模型。特别是在 Big-Bench Hard (BBH) 推理任务上,140GB 模型的准确性出现显著下降(24.68),而 103GB 模型依然保持了高水准的推理能力(73.83)。
3. 性能对比 (2):130GB vs 230GB (DeepSeek-V3)
协同压缩框架的优势在不同预算下同样明显。如下表所示,团队的 130GB 混合精度模型,其性能与 230GB 的 Q2_K_L 模型(一个更高比特的量化)相比,在 CMMLU 和 GSM8K 上甚至更高,在其他基准上也极具竞争力。这显示了在同等性能下,协同压缩能节省近 100GB 的内存。
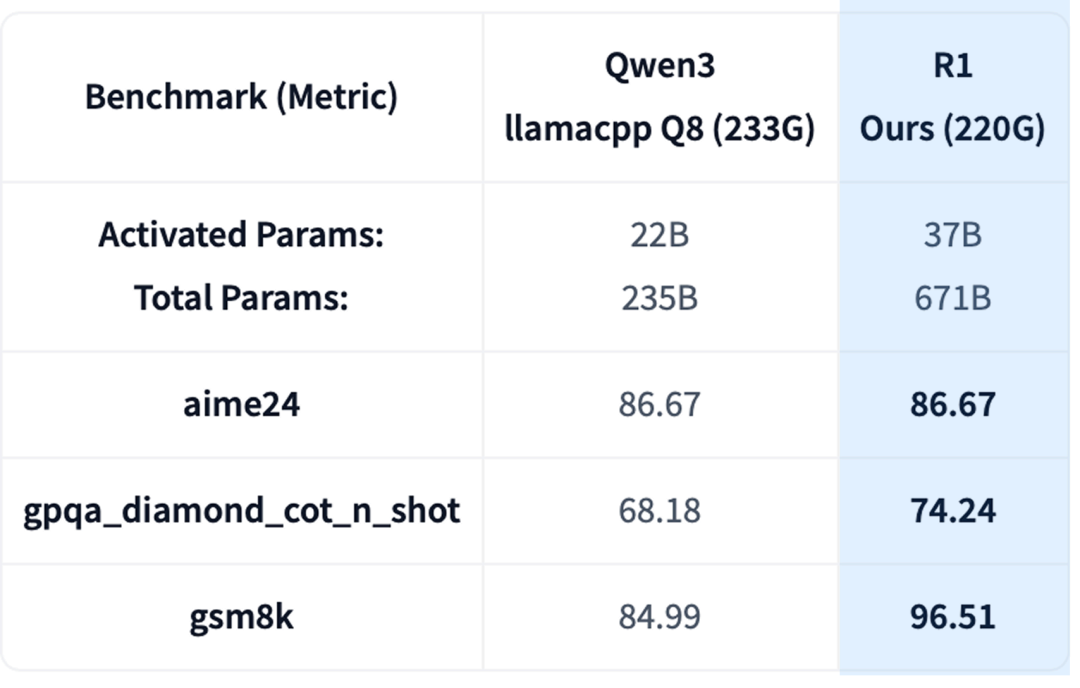
4. 框架通用性:210GB (DeepSeek-R1) vs 233GB (Qwen3)
为验证该框架并非“特调”优化,团队将其应用于另一款 671B 的 DeepSeek-R1 (0528) 推理模型。
结果显示,压缩后的 210GB DeepSeek-R1 模型,在 AIME24、GPQA Diamond 和 GSM8K 等高级推理任务上,持续优于一个体积更大(233GB)的 8-bit Qwen3 MoE 模型。这证明了该协同压缩框架具有强大的通用性。
5. Kimi K2 Thinking 量化
与此同时,在 Kimi K2 Thinking 模型发布后,Moxin AI 团队迅速应用此框架,推出了 GGUF 量化版本。这展示了该工具链快速跟进业界最新 SOTA 模型的能力,不仅再次验证了框架的通用性,也凸显了其作为 T 级模型边缘化部署工具的价值。


总结与未来展望
这项研究的意义在于,它为 T 级模型“下放”到边缘设备提供了一条切实可行的技术路径。MoE 模型的“内存墙”并非不可逾越,通过智能的、协同的压缩策略,可以在消费级硬件的严格限制下,依然保留 SOTA 模型的核心智能。
“协同压缩”框架的成功,使得在本地设备上运行强大的、保护隐私的、无网络延迟的 AI 应用成为可能。随着 T 级 AI 正从数据中心走向每个人的桌面,一个真正由端侧大模型驱动的个性化 AI 时代或将加速到来。
目前,Moxin AI 团队已将所有成果开源,包括论文和 GGUF 模型文件。

资源链接
📄 阅读完整论文:https://arxiv.org/abs/2509.25689
🤖 下载 GGUF 模型 (Hugging Face):
https://huggingface.co/collections/moxin-org/moxin-gguf(投稿或寻求报道:zhanghy@youkuaiyun.com)
【活动分享】2025 年是 C++ 正式发布以来的 40 周年,也是全球 C++ 及系统软件技术大会举办 20 周年。这一次,C++ 之父 Bjarne Stroustrup 将再次亲临「2025 全球 C++及系统软件技术大会」现场,与全球顶尖的系统软件工程师、编译器专家、AI 基础设施研究者同台对话。
本次大会共设立现代 C++ 最佳实践、架构与设计演化、软件质量建设、安全与可靠、研发效能、大模型驱动的软件开发、AI 算力与优化、异构计算、高性能与低时延、并发与并行、系统级软件、嵌入式系统十二大主题,共同构建了一个全面而立体的知识体系,确保每一位参会者——无论是语言爱好者、系统架构师、性能优化工程师,还是技术管理者——都能在这里找到自己的坐标,收获深刻的洞见与启发。详情参考官网:https://cpp-summit.org/




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











