




Kubernetes 诞生至今已有 11 年,当前版本已推进至 v1.33。在这十余年里,它从 Google 内部的容器编排工具,成长为支撑全球云基础设施的核心组件。然而,随着生态不断扩张与场景复杂化,K8s 也暴露出许多设计层面的局限与“历史债务”。如果我们有机会从头再来,打造一个 Kubernetes 2.0,它应该长什么样?
本文作者 Mathew Duggan 是一位资深 DevOps 工程师,在长年实践中与 Kubernetes 深度交锋。他站在一线用户视角,结合真实痛点,提出了对 K8s 2.0 的系统性设想。从 YAML 的替代方案到更合理的包管理机制,从 etcd 替换路径到默认启用 IPv6,他用一篇诚恳而犀利的技术长文,描绘出一个更强大、更易用、更现代的 Kubernetes。
原文链接:https://matduggan.com/what-would-a-kubernetes-2-0-look-like/
作者 | Mathew Duggan
出品 | 优快云(ID:优快云news)
大约在 2012-2013 年间,我在系统管理员圈子里频繁听到一个叫“Borg”的技术名词。据说那是 Google 内部的一个 Linux 容器系统,用来运行他们所有的服务。
当时一连串的术语让人听起来有点摸不着头脑,比如什么“Borglet”运行在带有“cells”的集群中。但随着时间的推移,渐渐地,一些只有 Google 内部员工才懂的基本概念开始向业界流传开来,如 Borg 中有“服务(services)”和“作业(jobs)”之分:应用程序可以通过服务响应用户请求,再通过作业处理那些运行时间更长的批处理任务。
然后时间来到 2014 年 6 月 7 日,我们看到了 Kubernetes 项目的首次提交。这个名字源自希腊语,意为“掌舵者”,但前三年几乎没人能正确念出来。(到底是 koo-ber-NET-ees,还是 koo-ber-NEET-ees?算了,跟大家一样叫它 k8s 吧。)
紧接着,微软、红帽、IBM 和 Docker 也很快加入了 Kubernetes 社区,这让它从一个“有趣的 Google 项目”转变成了“也许真能成为一款正式产品”的水平。
2015 年 7 月 21 日,我们迎来了 Kubernetes v1.0 的发布,同时 CNCF 基金会也宣告成立。
从首次提交至今的十年里,Kubernetes 成为了我职业生活的重要组成部分。我在家里用它,在公司用它,甚至在一些个人项目中也用它——只要合适就用。它的学习曲线陡峭,但也是一个强大的效率倍增器。我们早就不再以服务器为单位来“管理基础设施”了:现在一切都是声明式的、可扩展的、可恢复的,甚至在幸运的情况下,能实现自我修复。
当然,这一路走来也并非一帆风顺。有些共性的问题反复出现:应用中的很多失误以及配置有问题,都源自 Kubernetes 在某些地方缺乏明确的设计立场。即便十年过去了,生态系统中仍有很大的动荡,许多用户仍然会碰到那些众所周知的“坑”。
所以,基于我们目前掌握的知识,如果我们要重新设计一遍,怎样才能让这个强大的工具更易于被更多人、更广泛的问题场景所接受?
AI 产品爆发,但你的痛点解决了吗?8.15-16 北京威斯汀·全球产品经理大 会 PM-Summit,3000+ AI 产品人社群已就位。
直面 AI 落地难题、拆解头部案例、对接精准资源!
扫码登记信息,添加小助手进群,抢占 AI 产品下一波红利:

进群后,您将有机会得到:
· 最新、最值得关注的 AI 产品资讯及大咖洞见
· 独家视频及文章解读 AGI 时代的产品方法论及实战经验
· 不定期赠送 AI 产品干货资料和秘籍

K8s 做对了什么?
先说点正面的。为什么十年过去了,我们还在谈论这个平台?
容器的规模化能力
容器作为软件开发工具,是极其合理的选择。它避免了“每台笔记本配置都不一样”这类混乱,用一种统一的方式贯穿整个技术栈。虽然像 Docker Compose 这样的工具也能部署容器,但使用起来总有些笨拙,你还是得手动处理很多步骤。比如我自己就曾写过一个 Compose 部署脚本,用来把某个实例从负载均衡器中移除,拉取新的容器镜像,确认启动成功,再重新加回负载均衡器——很多人当时都这么干。
而 Kubernetes 则让这一切实现了规模化。它让你可以将本地开发的容器无缝扩展到成千上万台服务器。正因为有了这种灵活性,许多组织得以重新审视自身的架构策略,逐渐放弃单体应用,转而采用更灵活(虽然往往也更复杂)的微服务架构。
低维护成本
如果把运维的发展历程按照“命名风格”的演进时间线来做比喻,从“宠物式”到“牲畜式”,那么早期阶段我称之为“辛普森时代”。
那时的服务器是裸金属机器,由团队手动配置。它们往往有一些独一无二的名字,在团队内部成了俚语,每台机器都像雪花一样特殊且难以替代。服务器运行得越久,堆积的问题就越多,最后甚至连重启都让人胆战心惊,更别提重建了。
我把那段时间叫做“辛普森时代”,是因为我当时待过的好几家公司都喜欢用《辛普森一家》角色的名字给服务器命名。那时什么都不会自动修复,一切都得手动操作。
接着,我们进入了“01 时代”。Puppet 和 Ansible 等工具开始普及,服务器不再那么“金贵”,变得更易于替换。堡垒机(bastion host)和其他访问控制机制也逐渐成为常态。服务器不再直接暴露在公网,而是藏在负载均衡器之后;命名也不再那么有趣,取而代之的是像 “app01” 或 “vpn02” 这种编号式名称。系统设计允许某些服务器偶尔宕机不影响整体运作。不过,宕机并不会自愈,总得有人 SSH 进去排查原因,再更新工具脚本,把修复方案部署到整个机器池上。操作系统升级依然是个麻烦事。
而现在,我们进入了“UUID 时代”。服务器的存在仅仅是为了运行容器,它们完全是一次性的。没人关心某个特定版本的操作系统还能支持多久,只需要重新打一个镜像(比如 AMI),整机替换就好了。虽然 Kubernetes 不是唯一支持这一变革的技术,但它无疑加快了整个演进的进程。现在,如果我还要通过 SSH 登录到某台服务器里排错,这种行为已经属于“破窗”式的例外情况。大多数情况下的标准做法是:“销毁那个节点,让 k8s 自动重新调度,再拉起一个新的节点”。
那些曾经对我职业生涯至关重要的 Linux 技能,现在更多是“锦上添花”而非“必备技能”了。你可能会为此高兴,也可能觉得遗憾——我自己也常常在这两种情绪之间反复,但这就是现实。
作业调度
Kubernetes 的作业系统并不完美,但已经远胜于我们曾经用的“雪花型 cron01 服务器”。过去很多年里,企业内部常常专门有一台机器跑定时任务或从消息队列中拉任务,这种方式非常脆弱。现在,我们可以稳定地将作业放入队列中,由系统调度执行,失败后自动重试,然后你就可以放心去做别的事了。
这不仅释放了人力资源,避免了重复枯燥的人工操作,也极大提升了资源使用效率。虽然队列里的每个任务依然要启动一个 pod,但开发者可以根据 pod 的定义自由决定运行什么、怎么运行。对于像我这样需要频繁处理后台任务、但又不希望再花精力盯着的人来说,这无疑是一次生活质量的提升。
服务发现与负载均衡
应用中硬编码 IP 地址,一直是我职业生涯中的“老大难”。这种做法让请求的目标服务器变得极难更换。如果运气好,依赖的是 DNS 而非 IP,那你还可以在不修改代码的前提下更换服务地址,但很多时候并没有这么幸运。
Kubernetes 通过内置的 DNS 服务,简化了服务间通信。你只需通过一个普通的服务名称就能访问其他服务,省去了大量麻烦。这不仅消除了很多类型的错误,也大大简化了部署流程。借助 Service API,开发者可以获得一个稳定且长期存在的 IP 和主机名作为入口,不需要操心底层的实现细节。甚至还可以通过 ExternalName 把集群外部的服务“伪装”成集群内部的服务来访问。

如果让我设计 Kubernetes 2.0,我会加入什么?
用 HCL 取代 YAML
YAML 之所以受欢迎,是因为它不是 JSON,也不是 XML——就好像你夸一辆新车好,是因为它既不是马也不是独轮车。确实,YAML 在 Kubernetes 的演示中看起来更清爽,放在代码仓库里也更美观,给人一种“这只是个简单配置文件”的错觉。
但实际上,YAML 根本就不适合我们用在 Kubernetes 上的场景,也不够安全。缩进很容易出错;文件一旦变长,管理起来就很痛苦(没人想面对几千行的 YAML);调试体验也很糟。而且 YAML 的规范中还藏着许多隐晦又复杂的行为。
我至今都记得第一次遇到所谓“挪威问题”(Norway Problem)时的震惊。如果你还没遇到过,那真是幸运。所谓“挪威问题”指的是 YAML 中会把 'NO' 自动解释成布尔值 false。想象一下你要向挪威的同事解释,整个国家的代号在配置文件里被判断为“假”的尴尬场景。类似的还有各种因为缺少引号而被错误解析成数字的情况,列表太长不便维护……这些问题数不胜数。网上有不少文章深入探讨了 YAML 的各种“神操作”,比我能写的好得多,比如这篇:https://ruudvanasseldonk.com/2023/01/11/the-yaml-document-from-hell
为什么是 HCL?
HCL(HashiCorp Configuration Language)目前已经是 Terraform 的主要配置语言——换句话说,如果我们改用 HCL,至少只需要“讨厌”一种配置语言,而不是两种。HCL 是强类型的,支持显式的类型声明,已有成熟的校验机制。它就是为我们现在强行用 YAML 实现的这些用途而设计的,阅读上也并不难理解。它内置了许多函数,这些功能已经广泛被使用,可以帮助我们减少对 YAML 流程中各种第三方工具的依赖。
我敢打赌,现在大约有 30% 的 Kubernetes 集群已经是通过 Terraform 结合 HCL 来管理的。就算不引入 Terraform,光是使用更优秀的配置语言本身,也能带来许多好处。
当然,也不是没有代价。HCL 相比 YAML 会稍微啰嗦一点;而且它采用的是 Mozilla 公共许可证 2.0(MPL-2.0),要整合进 Kubernetes 这种基于 Apache 2.0 的项目中,需要做充分的法律审查。不过,考虑到它能带来的“使用体验质变”,这些障碍是值得克服的。
为什么 HCL 更好?
我们先来看一个简单的 YAML 文件示例:
# YAML doesn't enforce typesreplicas: "3" # String instead of integerresources: limits: memory: 512 # Missing unit suffix requests: cpu: 0.5m # Typo in CPU unit (should be 500m)即使是最基本的例子中,也到处都有错误。HCL 和类型系统可以捕获所有这些问题。
replicas = 3 # Explicitly an integerresources { limits { memory = "512Mi" # String for memory values } requests { cpu = 0.5 # Number for CPU values }}以这样的 YAML 文件为例,你的 K8S 仓库里可能有 6000 个这样的文件。现在,无需任何外部工具,就可以查看 HCL 了。
# Need external tools or templating for dynamic valuesapiVersion: v1kind: ConfigMapmetadata: name: app-configdata: # Can't easily generate or transform values DATABASE_URL: "postgres://user:password@db:5432/mydb" API_KEY: "static-key-value" TIMESTAMP: "2023-06-18T00:00:00Z" # Hard-coded timestampresource "kubernetes_config_map" "app_config" { metadata { name = "app-config" } data = { DATABASE_URL = "postgres://${var.db_user}:${var.db_password}@${var.db_host}:${var.db_port}/${var.db_name}" API_KEY = var.api_key != "" ? var.api_key : random_string.api_key.result TIMESTAMP = timestamp() }}resource "random_string" "api_key" { length = 32 special = false}以下是这种转变带来的主要优势:
-
类型安全:在部署前就能捕捉类型错误
-
变量与引用:减少重复配置,提升可维护性
-
函数与表达式:支持动态生成配置
-
条件逻辑:便于根据不同环境生成特定配置
-
循环与迭代:简化重复性配置的书写
-
更友好的注释格式:增强文档说明和可读性
-
错误处理机制:更容易定位和修复问题
-
模块化支持:可复用配置组件,提升组织结构
-
验证能力:防止无效配置被提交
-
数据转换支持:适用于复杂的数据处理逻辑
支持替换 etcd
我知道,这话已经被人写了一万遍都不止了。etcd 表现不错,但它是目前「唯一的选项」这件事还是有些离谱。对于小规模集群或资源有限的部署来说,etcd 所占用的资源非常可观,而这些场景可能永远不会达到 etcd 所带来的性能回报所要求的节点规模。更奇怪的是,现在的 etcd 几乎只剩 Kubernetes 这一个主要用户了。
我的建议是:把 kine 项目的成果“官方化”(https://github.com/k3s-io/kine)。从长远来看,允许 Kubernetes 插入多个存储后端是有益的。做一层抽象,让我们未来更容易替换后端系统,并且根据部署的硬件环境进行更灵活的调优。
我想象中的方案,大概会类似于这个项目:https://github.com/canonical/k8s-dqlite —— 它是一个基于 SQLite 的分布式内存数据库,采用 Raft 协议实现共识,几乎无需升级迁移步骤。这将为集群运维人员提供更灵活的持久化选项。如果你部署的是传统数据中心,etcd 的资源开销不是问题,那当然没必要换。但对于轻量级 Kubernetes 部署,这样的替代方案能显著提升使用体验,也(有希望)能降低社区对 etcd 的依赖。
超越 Helm:内建的包管理器
Helm 是一个典型的“临时解决方案用久了就成了刚需”的例子。我非常感谢 Helm 的维护者们,能把一个本是黑客松上诞生的小工具,发展成 Kubernetes 安装软件的事实标准。这是个令人敬佩的成就,也填补了 k8s 本身缺乏包管理机制的空白。
但话说回来,Helm 的使用体验简直是一场噩梦。Go 模板难以调试,模板里常常嵌套着复杂逻辑,最终导致各种莫名其妙的错误。而这些错误信息通常难以理解,几乎无法追踪来源。更根本的问题在于,Helm 并不是一个合格的软件包管理系统,它连最基本的两个功能都做不好:传递依赖管理和冲突解析。
什么意思呢?
接下来我想给你展示一个条件逻辑的例子,你可以告诉我,它到底想做什么?(这里原文将开始举例分析 Helm 模板中难以理解的逻辑)
# A real-world example of complex conditional logic in Helm{{- if or (and .Values.rbac.create .Values.serviceAccount.create) (and .Values.rbac.create (not .Values.serviceAccount.create) .Values.serviceAccount.name) }}apiVersion: rbac.authorization.k8s.io/v1kind: ClusterRolemetadata: name: {{ template "myapp.fullname" . }} labels: {{- include "myapp.labels" . | nindent 4 }}{{- end }}或者,如果我向图表提供多个值文件,哪一个会胜出:
helm install myapp ./mychart -f values-dev.yaml -f values-override.yaml --set service.type=NodePort那如果我想用一个 Helm Chart 来管理我的应用程序及其所有依赖项怎么办?这是合理的:我的应用本身依赖于其他组件,所以我希望把它们整合在一起。
于是我就在 Chart.yaml 中定义了子 Chart 或“伞形”Chart(umbrella chart)。
dependencies:- name: nginx version: "1.2.3" repository: "<https://example.com/charts>"- name: memcached version: "1.2.3" repository: "<https://another.example.com/charts>"但假设我有多个应用程序,那么完全有可能我有 2 个服务都依赖于 nginx 或类似的东西:
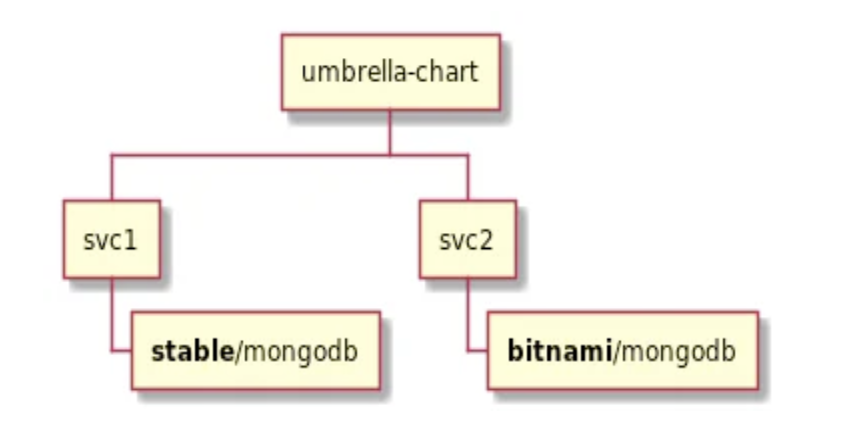
Helm 在处理这种情况时并不理想,因为所有模板的命名是全局的,而且加载顺序是按字母排序的。换句话说,你需要注意以下几点:
-
不要对同一个 Chart 声明多次依赖 —— 但对于大量微服务来说,这其实很难做到。
-
如果确实声明了多个相同的 Chart,版本号必须完全一致。
而且,这类问题远不止这些。
-
Helm 对跨 Namespace 的安装支持很糟糕。
-
Chart 的验证流程非常繁琐,结果几乎没人用
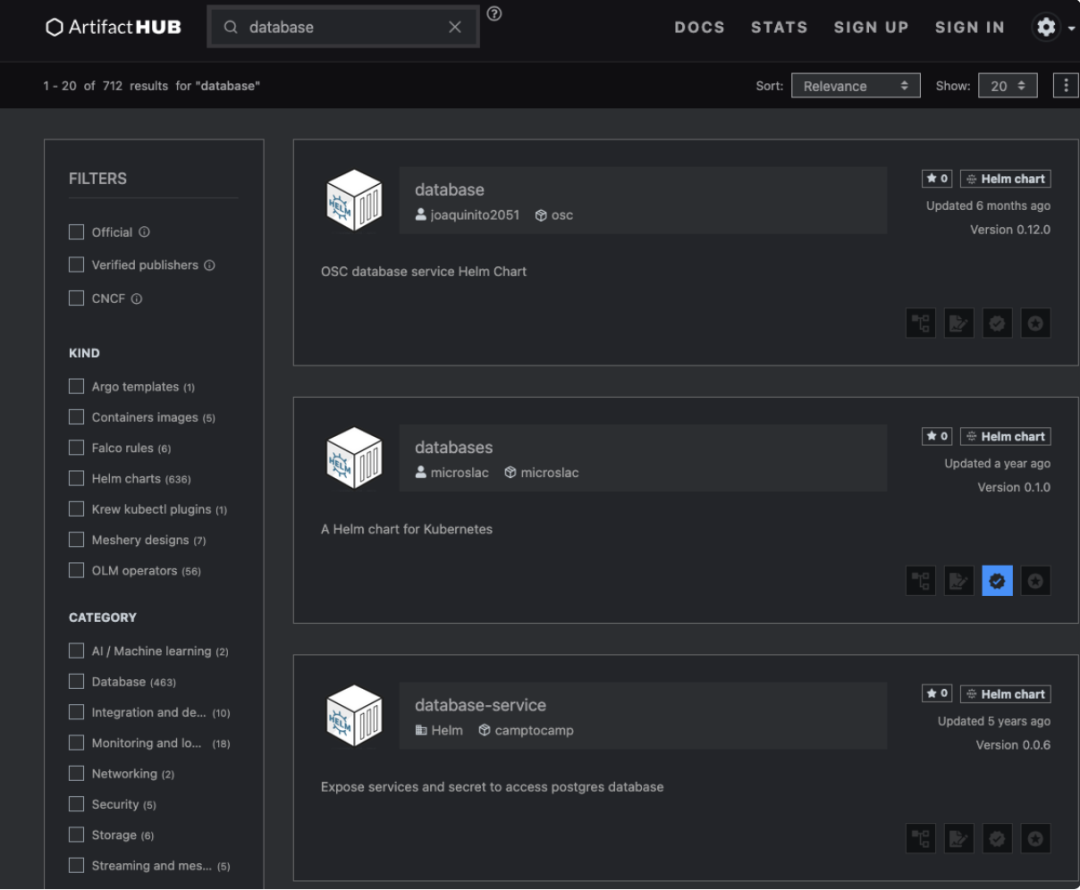
我们随便打开 ArtifactHub 的首页看看就明白了:
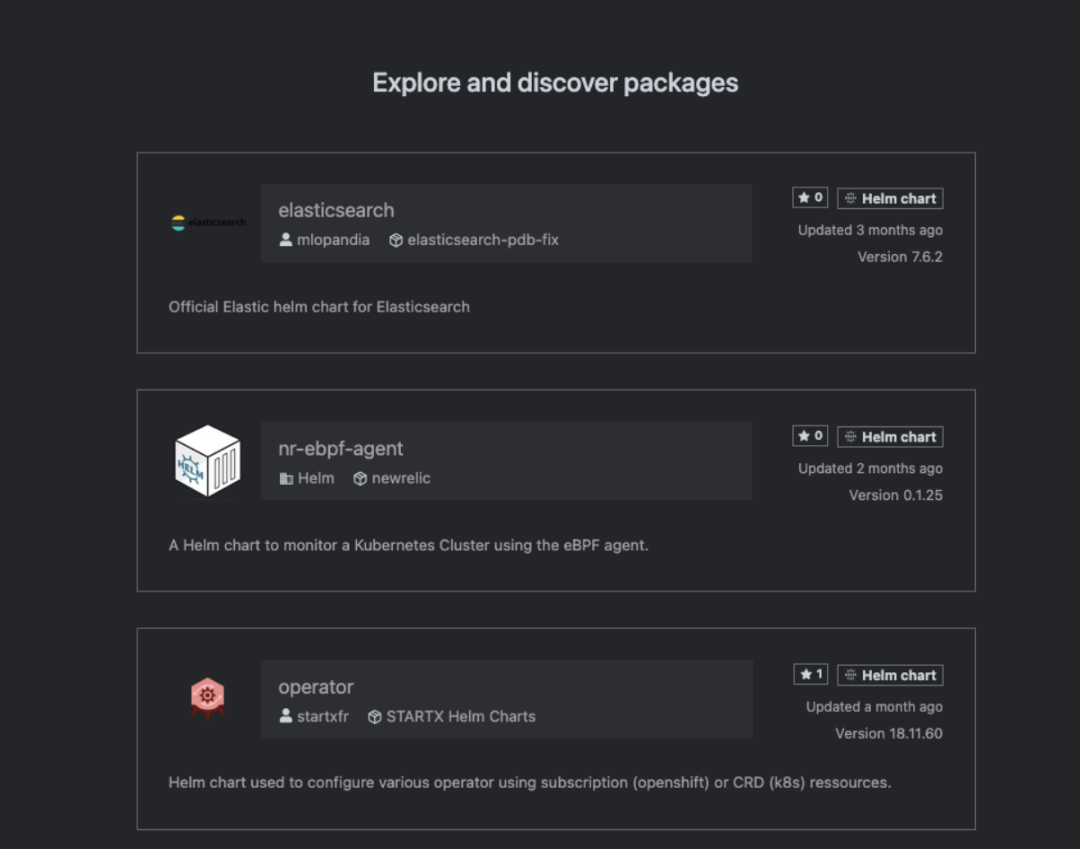
我会抓住 elasticsearch 因为它看起来很重要。
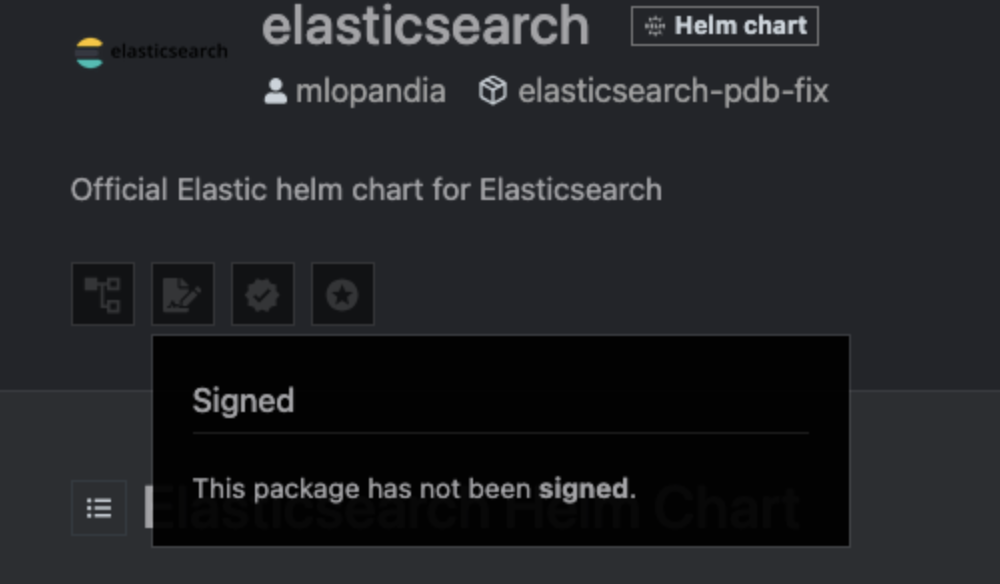
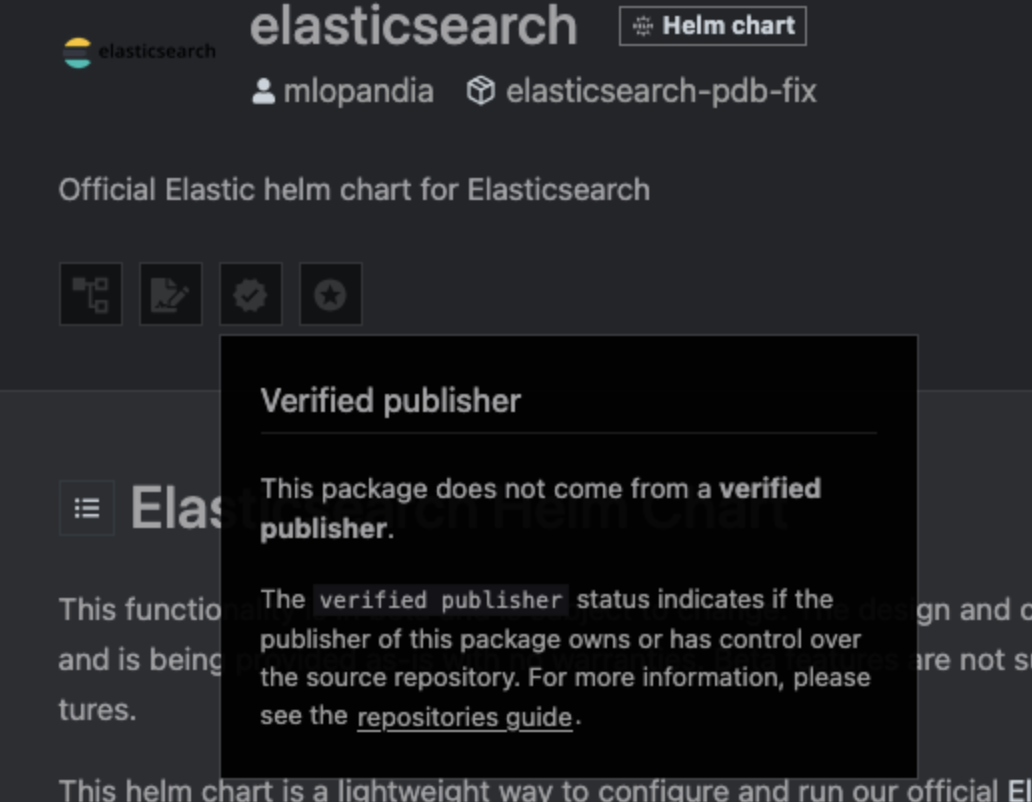
这对官方的 Elastic Helm Chart 来说看起来确实很糟糕。那 ingress-nginx 总该没问题吧?它可是整个行业都依赖的关键组件。
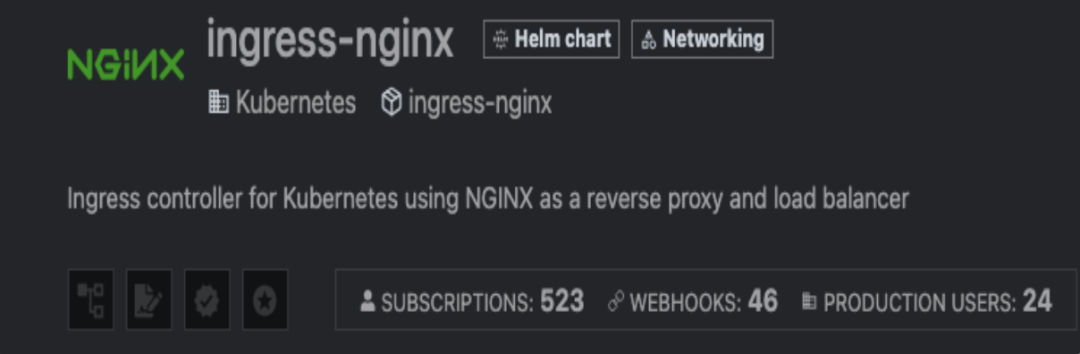
不行,还是不行。还有,Chart 的维护者都标明是 “Kubernetes” 了,结果竟然还没被标记为“已验证发布者”。天哪,这还能怎么更“官方”?
-
Chart 搜索时没有任何元数据支持。你只能按名称和描述进行搜索,无法根据功能、能力或其他元数据来筛选。
-
Helm 并不强制遵守语义化版本规范(Semantic Versioning)
# Chart.yaml with non-semantic versionapiVersion: v2name: myappversion: "v1.2-alpha"-
如果你卸载再重新安装一个带有 CRD 的 Chart,它有可能会把通过这些 CRD 创建的资源给删掉。这问题我踩过好几次,真的非常不安全。
我可以再写 5000 字,也说不完 Helm 的问题。说实话,Helm 根本无法胜任“地球上所有关键基础设施的软件包管理器”这个任务。k8s 包系统是什么样的?那么,一个理想的 Kubernetes 包管理系统应该是什么样子?我们暂且称它为 KubePkg —— 毕竟 Kubernetes 生态最需要的,就是再多一个带 “K” 的缩写名字。设计思路是:尽可能借鉴 Linux 生态中已有的成熟机制,同时充分利用 Kubernetes 的 CRD(自定义资源定义)能力。我的设想大致如下:
这些软件包类似于 Linux 软件包:
并配有一个定义文件,能够覆盖你在安装软件时遇到的各种真实场景。
apiVersion: kubepkg.io/v1kind: Packagemetadata: name: postgresql version: 14.5.2spec: maintainer: name: "PostgreSQL Team" email: "maintainers@postgresql.example.com" description: "PostgreSQL database server" website: "https://postgresql.org" license: "PostgreSQL" # Dependencies with semantic versioning dependencies: - name: storage-provisioner versionConstraint: ">=1.0.0" - name: metrics-collector versionConstraint: "^2.0.0" optional: true # Security context and requirements security: requiredCapabilities: ["CHOWN", "SETGID", "SETUID"] securityContextConstraints: runAsUser: 999 fsGroup: 999 networkPolicies: - ports: - port: 5432 protocol: TCP # Resources to be created (embedded or referenced) resources: - apiVersion: v1 kind: Service metadata: name: postgresql spec: ports: - port: 5432 - apiVersion: apps/v1 kind: StatefulSet metadata: name: postgresql spec: # StatefulSet definition # Configuration schema using JSON Schema configurationSchema: type: object properties: replicas: type: integer minimum: 1 default: 1 persistence: type: object properties: size: type: string pattern: "^[0-9]+[GMK]i$" default: "10Gi" # Lifecycle hooks with proper sequencing hooks: preInstall: - name: database-prerequisites job: spec: template: spec: containers: - name: init image: postgres:14.5 postInstall: - name: database-init job: spec: # Job definition preUpgrade: - name: backup job: spec: # Backup job definition postUpgrade: - name: verify job: spec: # Verification job definition preRemove: - name: final-backup job: spec: # Final backup job definition # State management for stateful applications stateManagement: backupStrategy: type: "snapshot" # or "dump" schedule: "0 2 * * *" # Daily at 2 AM retention: count: 7 recoveryStrategy: type: "pointInTime" verificationJob: spec: # Job to verify recovery success dataLocations: - path: "/var/lib/postgresql/data" volumeMount: "data" upgradeStrategies: - fromVersion: "*" toVersion: "*" strategy: "backup-restore" - fromVersion: "14.*.*" toVersion: "14.*.*" strategy: "in-place"有一个真正的签名过程是必需的,它允许你更好地控制该过程。
apiVersion: kubepkg.io/v1kind: Repositorymetadata: name: official-repospec: url: "https://repo.kubepkg.io/official" type: "OCI" # or "HTTP" # Verification settings verification: publicKeys: - name: "KubePkg Official" keyData: | -----BEGIN PUBLIC KEY----- MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAvF4+... -----END PUBLIC KEY----- trustPolicy: type: "AllowList" # or "KeyRing" allowedSigners: - "KubePkg Official" - "Trusted Partner" verificationLevel: "Strict" # or "Warn", "None"如果有一些东西可以让我自动更新软件包而不需要我做任何事情,那该有多好啊。
apiVersion: kubepkg.io/v1kind: Installationmetadata: name: postgresql-main namespace: databasespec: packageRef: name: postgresql version: "14.5.2" # Configuration values (validated against schema) configuration: replicas: 3 persistence: size: "100Gi" resources: limits: memory: "4Gi" cpu: "2" # Update policy updatePolicy: automatic: false allowedVersions: "14.x.x" schedule: "0 2 * * 0" # Weekly on Sunday at 2am approvalRequired: true # State management reference stateRef: name: postgresql-main-state # Service account to use serviceAccountName: postgresql-installerKubernetes 需要一个满足以下条件的包管理系统:
-
真正的 Kubernetes Native:一切都是 Kubernetes 的资源对象,具备完整的状态(status)与事件(events)机制
-
一流的状态管理:对有状态应用提供内建支持
-
增强的安全性:强健的签名验证机制、安全扫描流程
-
声明式配置:无需模板,仅使用具备 schema 的结构化配置
-
生命周期管理:覆盖整个生命周期的钩子机制与升级策略
-
依赖关系解析:类 Linux 的依赖管理机制,支持语义化版本
-
审计日志:完整记录每次变更,包括谁改了、改了什么、什么时候改的——而不是 Helm 现在那种模糊不清的方式
-
策略强制:支持组织级的合规性策略与准则
-
简化的用户体验:借鉴 Linux 的包管理命令行风格,使用直观。这么多年来被验证有效的包管理方式,我们却在 Kubernetes 上走了另一条复杂的路,实在是没必要。

默认启用 IPv6
试着想象一下,全世界范围内,有多少时间与精力被浪费在以下三个问题上:
-
我希望这个集群中的 Pod 能访问另一个集群里的 Pod
-
NAT 穿透过程中出了问题,我得解决它
-
我的集群 IP 地址用完了,因为我没算好会用多少。举个例子:某公司使用的是一个 /20 子网(大约 4096 个地址),部署了 40 个节点,每个节点运行 30 个 Pod,然后突然发现——IP 不够用了!这还不是特别大的集群!
我并不是说整个互联网现在就该切换到 IPv6。目前 Kubernetes 已经可以支持 IPv6-only 或双栈(dual-stack)模式。但我的意思是,现在是时候把默认选项改成 IPv6 了。因为这么做可以一下子解决大量长期存在的网络问题:
-
集群内部的网络拓扑更加扁平、简洁
-
是否使用多个集群,对企业而言变成一个可选项,特别是当你希望直接使用公网 IP 时
-
更容易理解应用内部的流量路径
-
原生支持 IPSec 加密
这和推动全球 IPv6 普及无关,而是现实地承认:我们已经不再生活在那个必须接受 IPv4 各种限制的时代。今天,你可能随时需要 1 万个 IP 地址,而且不会提前几个月知道。
对于拥有公网 IPv6 地址的组织来说,这种转变的好处显而易见。但即使是对云服务商和用户来说,价值也足够大,大到连“企业大老板们”都有可能支持。比如 AWS 就再也不需要在 VPC 内到处搜刮有限的私有 IPv4 地址了——这难道不值得吗?

结语
针对上述这些想法,最常见的反驳是:“Kubernetes 是一个开放平台,社区可以自己去实现这些功能。”虽然这话没错,但它忽略了一个关键问题:“默认选项”才是技术中最具力量的驱动器。
核心项目所定义的“推荐路径”(happy path),会决定 90% 的用户怎么使用这个系统。如果系统默认启用签名包,并且提供一个稳健、原生的管理方式,那么整个生态自然就会围绕这个方向发展。
我知道,这是一份雄心勃勃的清单。但既然要设想 Kubernetes 2.0,那就不妨大胆一点。毕竟我们就是那个曾经以为“叫 Kubernetes 这个鬼名字也能火起来”的行业——结果还真就火了。
我们在移动开发、Web 开发等领域已经看到这种事一次次发生:平台评估现状后,果断迈出一大步。这些建议可能不是当前维护者或厂商会立刻采纳的任务,但我真心觉得,它们值得有人回过头去认真想一想、重新审视一下这个平台:现在我们已经占据了全球数据中心运维的很大一部分,这些想法是否值得去做一做?
📢 2025 全球产品经理大会
8 月 15–16 日
北京·威斯汀酒店
2025 全球产品经理大会将汇聚互联网大厂、AI 创业公司、ToB/ToC 实战一线的产品人,围绕产品设计、用户体验、增长运营、智能落地等核心议题,展开 12 大专题分享,洞察趋势、拆解路径、对话未来。
更多详情与报名,请扫码下方二维码。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











