



 本文介绍如何使用Python和Pyppeteer实现机器人流程自动化(RPA),解决繁琐且重复的工作任务,提高工作效率。
本文介绍如何使用Python和Pyppeteer实现机器人流程自动化(RPA),解决繁琐且重复的工作任务,提高工作效率。


作者 | 阿文
出品 | 优快云(ID:优快云news)
头图 | 优快云下载自东方IC

繁琐且重复的工作
在我们日常的工作中,有很多事情是重复且繁琐的,组织内部不同的部门开发出来的系统相互之间并没有过多的依赖关系,于是使用系统的人在利用现有系统去解决问题,经常需要跨越多个不同部门所提供的平台去进行操作,举个例子,在我们的日常工作中会依赖工单系统、用户信息查询系统、审核系统以及内部管理平台。这四个平台都是有不同的部门维护的,相互之间数据不互通。
有时候用户提交了一些审核性质的工单,其中包含 20 几张图片,人工审核下,需要去打开这 20 几张图片获取到指定的信息,然后去上述几个平台去做对应的操作。比如查询、提交等等。这样一来一回一个问题的解决时常可能就需要 1 个小时以上。
那么我们能不能通过机器去自动完成这些固定流程且繁琐的工作呢?答案是肯定的。现阶段,我们可以通过引入 RPA 来实现整个流程的打通。
什么是 RPA
RPA 是机器人流程自动化的简称,听起来很高大上的名字,实际上本质就是自动化,让机器帮人去做一些流程固定的事情,机器可以 7* 24小时不停转的完成工作。但是人最多只能 996,毕竟还是要睡觉的,不能剥削的太狠。
RPA 工具选型
RPA 其实出现的时间不短,但是在国内兴起也就最近几年的事情,成熟的产品并不多,例如阿里云的RPA、国外的uiPath 等等,但是这些工具对于平台依赖性较大,他们只能部署在Windows 操作系统上,而我们希望部署在Linux 服务器上,在命令行模式下运行,这样可以节省资源。
基于此,我们决定通过 Python 来实现自动化,由于我们所需要对接的系统大部分都不会给我们提供现成的 API 接口,我们一开始通过 requests 来模拟登录获取coookies 进行请求,但是这个过程中发现很多页面都是异步加载数据,而 requests 是同步的,无法获取数据,且内部系统做了非常严格的认证鉴权,仅仅靠 requests、Beautiful Soup 等是搞不定这些鉴权的。因此我们需要一些工具来实现模拟浏览器请求爬取数据,对比了目前比较流行的几款开源的自动化工具:
Selenium:老牌自动化测试工具,优点是支持大部分主流浏览器,它提供了功能丰富的API接口,且支持浏览器无头模式,但是缺点也很明显,比如速度太慢、对版本配置要求严苛,最麻烦是经常要更新对应的驱动,每次浏览器升级都需要去重新安装 Chromedriver。
Puppeteer Puppeteer:是一个 Node 库,它提供了高级 API 来通过 DevTools 协议控制 Chrome 或 Chromium,简单理解成我们日常使用的 Chrome 的无界面版本,可以使用 js 接口进行进行操控。意味凡是 Chrome 浏览器能干的事情,Puppeteer 都能出色的完成。
RPAfor Python:这个是我们最开始使用的一款 RPA 工具,它可以很好的满足我们的需求,且操作也比较简单, 通过 Xpath 定位元素就可以对 DOM 进行操作,但是其与 Selenium 有着相同的缺点即速度慢,且不支持浏览器无头模式运行,也就是说它需要一个桌面环境,对资源消耗较大,尤其是 Chromium 这种吃内存较大的程序。而我们希望将其部署到 Linux 服务器上去,所以 Rap for Python 也就无法满足需求了。
经过对比,最终我们选择了 Puppeteer 的 Python 版本 Pyppeteer 来作为 RPA 工具
Pyppeteer 是什么
Puppeteer(中文翻译”木偶”) 是 Google Chrome 团队官方的无界面(Headless)Chrome 工具,它是一个 Node库,提供了一个高级的 API 来控制 DevTools协议上的无头版 Chrome 。也可以配置为使用完整(非无头)的 Chrome。它非常适合前端开发者进行自动化测试,而我们除了使用这个自动化工具,还有一些其他功能是基于 Python 来开发的,比如使用pandas 处理表格,做数据分析,所以我们选择了一个社区维护的 Pyppeteer ,他的功能几乎和 Puppeteer 一样,所以即使是去看 Puppeteer 的文档也没多大问题。
puppeteer 可以做很多事情,简单来说你可以在浏览器中手动完成的大部分事情都可以使用 Puppeteer 完成!例如:
生成页面的截图和PDF。
抓取SPA并生成预先呈现的内容(即“SSR”)。
从网站抓取你需要的内容。
自动表单提交,UI测试,键盘输入等
创建一个最新的自动化测试环境。使用最新的JavaScript和浏览器功能,直接在最新版本的Chrome中运行测试。
捕获您的网站的时间线跟踪,以帮助诊断性能问题。
开始使用 Pyppeteer
1.无头模式配置
在打开浏览器的时候,我们需要设定一些参数,如果你需要它跑在容器里面或纯字符模式的 Linux 中,则 headless 参数必须设置为 true,同时 args 中的参数也要加上,它主要是关闭Chrome 一些没有必要的功能,例如扩展、flash、音频和gpu等,以达到节省资源的目的,executablePath 可以指定浏览器的目录,默认 Pyppeteer 会自动去执行 Pyppeteer-install 来下载 Chromium,在国内下载极其慢,建议提前安装好 Chromium。
browser = await launch(
{'executablePath': self.config["Chromium_path_linux"], #设置浏览器路径
'headless': True,
"autoClose": True,
"args": [
'--disable-extensions',
'--hide-scrollbars',
'--disable-bundled-ppapi-flash',
'--mute-audio',
'--no-sandbox',
'--disable-setuid-sandbox',
'--disable-gpu',
],
'dumpio': True
})
参数含义
2.异步编码
由于 Pyppeteer 是异步的因此在 Python 中 需要使用async def 来增加方法。
3.注入cookie
在一些场合,我们需要与 requests 进行结合,因为整体上 requets 的效率和实现相对比较容易些,可以在必要的时候调用 Pyppeteer 唤起浏览器,因此可以通过设置cookie 来让 Pyppeteer 登录某个页面
await page.setExtraHTTPHeaders(cookies)
4.阻塞
在一些场景,我们需要进行阻塞,比如说页面加载中,但是程序执行的很快,可能还没加载完就执行其他语句了,这样就拿不到想要的数据,这个时候可以使用page.waitFor 让页面进行等待,不要去使用 time.sleep()
await page.waitFor(3000)
一些页面要善于使用 Page.waitFor。因为有些click 事件程序触发过短会无法唤起
5.定位元素
在获取页面某个标签内的元素是比较常用的方法,可以通过querySelector 先定位到元素,然后通过 page.evaluate 执行js 原生方法来拿到标签内的文本
status_text = await page.querySelector(".status-text")
sussces_info = await page.evaluate('(element) => element.textContent', status_text)
6.截图
有时候我们需要对页面的某一段元素进行截图,我们可以使用page.J 先定位到元素,然后调用 screenshot 进行截图
element = await page.J('.ant-table-wrapper')
now_unix_time = int(time())
image_name = 'screenshot-{}.png'.format(str(now_unix_time))
image_path = '/'.join([self.config["images_path"], image_name])
await element.screenshot({"path": image_path})
截图的时候需要设置浏览器的分辨率await page.setViewport({'width': 1280, 'height': 720})
7.快速查找元素
很多时候我们不能通过 id、 class 来定位页面元素的具体路径,可以借助 Chrome 的开发者工具,对元素进行定位,快速的找到元素,而 Pyppeteer 提供了多种方式查找元素,如选择器、xpath
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-d3PXnzb5-1605862399160)(https://file.awen.me/blog/image-20201115074546436.png)]
例如:
await page.querySelector() # 选择器方式定位元素
await page.xpath() # xpath 方式定位元素
8.Page.waitForpage.waitFor(selectorOrFunctionOrTimeout[, options[, …args]]) 下面三个的综合 API
page.waitForFunction(pageFunction[, options[, …args]]) 等待 pageFunction 执行完成之后
page.waitForNavigation(options) 等待页面基本元素加载完之后,比如同步的 HTML, CSS, JS 等代码
page.waitForSelector(selector[, options]) 等待某个选择器的元素加载之后,这个元素可以是异步加载的。
9.使用工具自动生成代码
如果你对编写这种枯燥乏味的元素定位感到厌烦,不妨试试Chrome 的插件 Puppeteer recorder ,他可以录制你的页面操作,当然很多时候并不是很准,但是通过它来辅助开发,可以大大提升你的开发效率。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7UXYHRDD-1605862399172)(https://file.awen.me/blog/image-20201115074450488.png)]
10.执行程序
由于是异步的,因此我们需要通过异步的方式来调用,同时使用 loop的create_task 方法获取回调拿到返回值。
loop = get_event_loop()
task = loop.create_task(sync_payment_platform.get_page_image())
image_name = loop.run_until_complete(task)
11.无头模式下的调试
在我们爬取一些网站时候发现在正常有Headless 的情况下可以得到最终的效果,但是在无头模式下会拿不到元素,提示超时。报类似 下面这样的超时错误。
Waiting for selector "#indexPageViewName > div.content-view > div > div > div.left-view > div.searchform.clearfix > div:nth-child(1) > div:nth-child(3) > div > div > div.field-left" failed: timeout 30000ms exceeds.
这种情况下我们可以通过上面说的截图的方式进行Debug,看下当前报错的页面是否与实际页面一致,建议配置上 User-Agent。因为某些情况下系统会把页面当成移动端来访问,导致获取到的页面元素与实际不一致。await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36')
12.pypuppet 整合 requests
很多时候,一些系统都会提供接口,如果我们能够直接请求这些接口,效率会更高,但是内部系统会使用非常严格的校验,普通的登录方式是走不通的。不过 pypuppet 可以帮我们绕过鉴权限制,并拿到对应系统的cookies。
cookies = await page.cookies()
cookies_info = {}
for i in cookies:
key_name = i["name"]
value_name = i["value"]
cookies_info[key_name] = value_name
当我们拿到 cookies 后我们就可以通过 requests 模拟 HTTP 请求了,这样在一些非异步加载的页面下可以直接爬取接口,节省了大量的时间和精力。response = self.request_session.post(url, headers=headers, json=payload, cookies=cookies_info)
这里可以把缓存信息写到 Redis 中去,设置下过期时间,这样只需要在首次进行登录,后面直接读取cookies 进行请求,与此同时,一些网站的请求头中加了一些自定义的头,如果缺少这些头,则无法进行请求,这时候,我们可以通过page.on 来拦截请求或响应信息,例如抓取特定的url,拿到对应的 headers 将其进行缓存,然后读取 headers 信息放到请求头中去,完美的绕过鉴权。async def intercept_response(self, res):
if res.request.url == self.config["api_url"] + "api/web/emp/business:
print(f"获取请求头 {res.request.headers}")
self.redis_connect.set_redis("key", str(res.request.headers))
async def login_meike(self):
……
page.on('response', self.intercept_response)
13.服务器环境依赖
我们是将其部署在虚拟机上,由于单位提供的镜像非常精简,如果想让程序能够在无头模式下运行,只需要安装 Xvfb 即可,Xvfb是一个实现了X11显示服务协议的显示服务器。不同于其他显示服务器,Xvfb在内存中执行所有的图形操作,不需要借助任何显示设备。执行下面的命令即可安装:
yum -y install Xvfb
然后默认centos 的源中是没有 Chromium 的,需要安装 epel-release 然后执行:yum -y install epel-release
yum -y install Chromium
接着就可以部署到服务端运行了。
不过需要注意了,如果你的服务器没有安装中文字体。Chromium 中会显示方块字。这个时候只需要安装上对应的中文字体就行
yum -y groupinstall chinese-support
yum -y groupinstall Fonts
案例演示
下面是一个使用 pyppeteer 登录某网站,我们可以看到这个网站需要输入手机号、密码还有
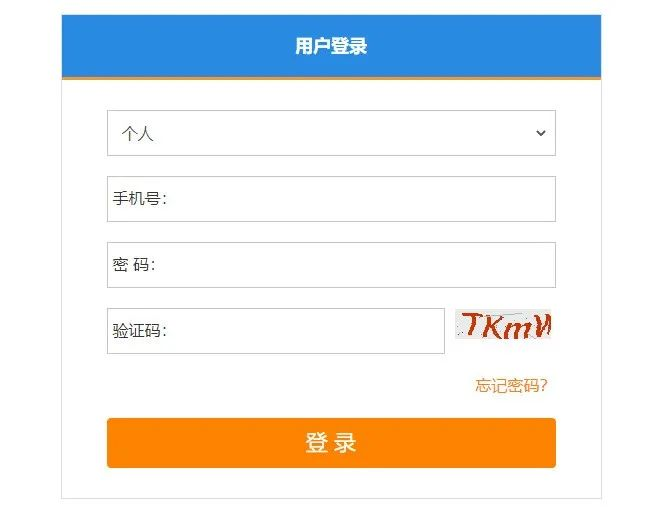
那么我们怎么使用 Pyppeteer 开完成呢?
首先,我们需要定位到手机号和密码还有验证码所在的元素,我们先定义一个函数,用于配置一些基础的浏览器属性,包括是否要启用无头模式,以及关闭浏览器一些没有用的选项,比如chrome的扩展、浏览器的页面大小和 UserAgent。以及 Webdriver 的属性, Useragent 和Webdriver 的设置主要是为了防止别识别是 Pyppeteer 在操作而被拦截,比如淘宝等网站就会有大量的反爬虫机制识别机器人登录。
async def open_browser(self):
browser = await launch(
{'executablePath': "c:/chrome-win/chrome.exe",
'headless': False, # 是否启用无头模式,False 会打开浏览器,True 则在后台运行
"autoClose": True,
"ignoreDefaultArgs": ["--enable-automation"],
"args": [
'--disable-extensions',
'--hide-scrollbars',
'--disable-bundled-ppapi-flash',
'--mute-audio',
'--no-sandbox', # --no-sandbox 在 docker 里使用时需要加入的参数,不然会报错
'--disable-setuid-sandbox',
'--disable-gpu'
],
'dumpio': True
})
await page.setViewport({'width': 1920, 'height': 1080}) # 定义浏览器的窗口大小,如果太小了,则页面显示不全
await page.evaluateOnNewDocument('Object.defineProperty('
'navigator, "webdriver", {get: () => undefined})')
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36')
return [page, browser]
定义一个函数用户打开网站,输入用户名和密码以及验证码 page.type 中的元素地址,我们可以参考上面快速查找元素部分来通过chrome 开发者模式调试获取元素路径,我们可以看到这个网站他的id 为 userLoginCode 的 input 有2个,但是他们的name 是不一样的,所以我们可以这样去选择。#personLi > td > div > input[name=loginCode]
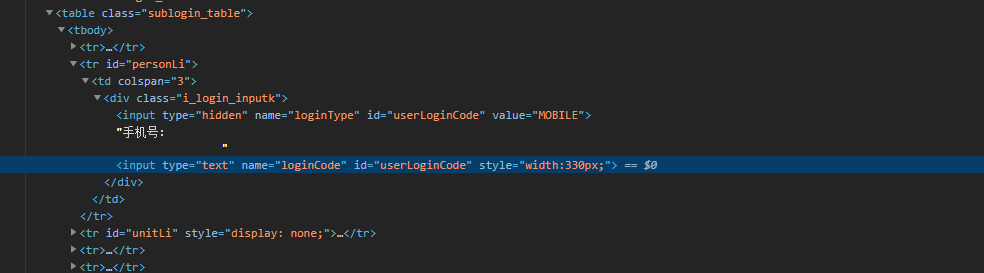
同时这个网站还有验证码。这里的验证码我们可以通过一些开放的OCR 识别能力去搞定他,比如百度的OCR 识别。

下面是这个登录函数的代码:
async def login(self):
#调用上面的函数打开浏览器
page, browser = await self.open_browser()
login_url = "https:/xxx.cn/xxx/"
# 打开网站
await page.goto(login_url)
login_random_time = randint(30, 150)
# 获取页面验证码的图片元素并截图
verification_code = await page.querySelector("#userGetValidCodeImg > a > img")
images_path = "images/verification_code.png"
await verification_code.screenshot({'path': images_path})
# 通过 OCR 识别验证码,如果返回False 则不断重试,直到登录成功,如果返回Ture,则输入用户名、密码、验证码进行登录。
code = await self.ocr_verification_code(images_path)
print(f"当前验证码 {code}")
if code is False:
while True:
await page.reload()
if await self.login_yaohao():
break
else:
# 填写用户名、密码和验证码并点击登录按钮
await page.type('#personLi > td > div > input[name=loginCode]', self.username,
{'delay': login_random_time - 50})
await page.type('#userPassword', self.password, {'delay': login_random_time - 50})
await page.type('#userValidCode', code, {'delay': login_random_time - 50})
await page.click('#userLoginButton')
await page.waitFor(2000)
cookies = await page.cookies()
cookies_info = {}
for i in cookies:
key_name = i["name"]
value_name = i["value"]
cookies_info[key_name] = value_name
self.redis_connect.set_redis("yaohao", "cookies", str(cookies_info), ex=3600)
await browser.close()
return cookies_info
通过上述方式我们登录成功后,就可以拿到cookies。并可以通过定义一个 Session(),然后去请求啦。def __init__(self):
super().__init__()
self.request_session = Session()
好了,以上就是关于使用Python 制作 RPA 机器人的分享。

更多精彩推荐
☞你熟知的开源项目,幕后推手竟然是他们?
☞AI独角兽云从科技:用人机协同战略,跨AI工程的楚河汉界
☞关键时刻卡成狗,测网速要成上网必备动作了?
☞深度揭秘垃圾回收底层,这次让你彻底弄懂它
☞别再问如何用 Python 提取 PDF 内容了!
☞偷盖茨、奥巴马 Twitter 的黑客被抓了,年轻到你想不到!
点分享点点赞点在看



















 698
698

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











